Hi Roland,
sounds great that you are pushing for the whole CQRS story.
I'm just experimenting with akka and CQRS and have no production
experience, but I'm thinking about the concepts since some time. So please
take my comments with a big grain of salt and forgive me for making it
sound somewhat like a wish list. But I think if there is a time for wishes,
it might be now.
I feel the need to distinguish a little more between commands, querys,
reads and writes.
In a CQRS setup, I (conceptually) see three parts:
(1) the Command side: mainly eventsourced PersistentActors that build
little islands of consistency for changing the application state
(2) the link between the Command and Query side: the possibility to
make use of all or a subset of all events/messages written in (1) for
building an optimized query side (3) or even for updating other islands of
consistency on the Command side (other aggregates or bounded contexts) in
(1)
(3) the Query side: keeping an eventually consistent view of the
application state in any form that is suitable for fast application queries
>From the 10000-foot view, we write to (1) and read from (3) but each of
(1),(2) and (3) has its own reads and writes:
(1) writes: -messages produced by the application to be persisted
reads: -consistent read of the persisted messages for actor replay
-stream of all messages (I think, that's what you mean by
SuperscalableTopic)
(2) writes: -at least conceptually: all messages of the all-messages
stream of (1)
reads: -different subsets of the all-messages stream that make
sense to different parts of our application
(3) writes: -any query-optimized form of our data that was read of some
sub-stream of (2)
reads: -whatever query the query-side datastore allows (SQL,
fulltext searches, graph walks etc.)
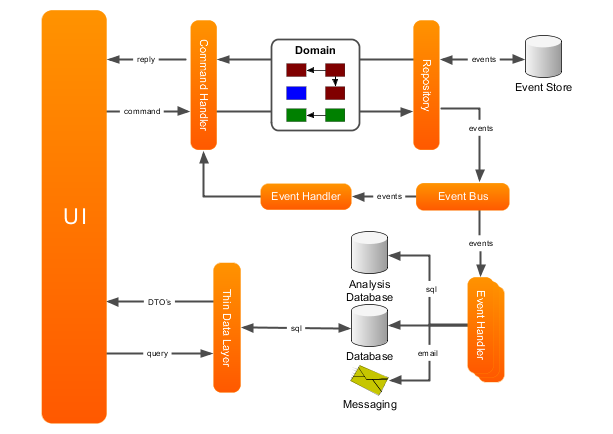
While (1) is the current akka persistence implementation plus a way to get
all messages, (2) is more like the Event Bus (though I would name it
differently) in this picture from the axonframework documentation
(http://www.axonframework.org/docs/2.0/images/detailed-architecture-overview.png).
(1) and (2) could be done by one product like what eventstore does with its
projections or it could be different products like Cassandra for (1) and
Kafka for (2). (3) could be anything that holds data.
Some more detail:
On (1):
As said before, the command side is fine as it is today to put messages
into the datastore and get them out again for persistent actors. I
definitely would consider replaying of messages for persistent actors part
of the command side, since the command side in itself has stronger
consistency requirements (consistentency within an aggregate) than the
query side.
Additionally, as Ashley wrote, any actor should be able to push messages to
the all-messages stream. In contrast to persistent actors I dont' see any
need for replay here. Therefore and for other reasons (like message
deduplication in (2)) I would like to propose adding an extra unique ID
(UUID?) for any message handled by the command side, independent of an
actors' persistenceId (which would be needed for replays nevertheless).
Also, I see the need to provide some guarantees for the all-messages
stream. I would consider an ordering guarantee for messages from the same
actor and an otherwise (at least roughly) timestamp based sorting a good
compromise. This would also be comparable to the guarantees that akka
provides for message sending. Ideally, the order stays the same for
repeated reads of the all-messages stream. With the guarantees mentioned
before, if the datastore keeps all messages of an actor on the same node,
the all-messages stream could even be created per datastore node.
On (2):
As mentioned above, I see the QueryByPersistenceId as part of (1) as it
requires stronger consistency guarantees. All other QueryByWhatever are all
about the question, how to retrieve the right subset of messages from the
all-messages stream for the application and its domain. This of course
differs by application and domain. Therefore I like Martin's
QueryByStream(name, ...), where a stream is any subset of messages the
application cares about.
I also think it should not be up to the datastore to decide what streams to
offer. I also can't really imagine how this should work in most datastores.
While there might be some named index on top of JSON messages in MongoDB
that can be served as as stream, I don't see how to create a
stream/view/index in Key-Value stores or RDBMS where a message is probably
persisted as byte array whithout any knowledge of the application.
To tell the datastore what streams to offer, I would consider something
like projections in eventstore or user-defined topics in Martin's
kafka-persistence that are driven by the application. In the simplest form
it could be a projection function like
Message => Seq[String]
that is applied to each message of the all-messages stream, which taskes a
message and gives back Strings of sub-stream-IDs. This could be anything
from the type-name to the persistenceId of an actor to a property of the
message. So it feels a little like "tagging on the read side" or more
precisely "tagging on the way from the command to the query side". New
messages should be added to the sub-streams as they arrive in the
all-messages stream. This could probably be done in any datastore that can
keep another index based on message IDs (if IDs are added on the command
side) and is adjustable with application needs.
The interface for (2) could allow new projections that could be run against
the all-messages stream or any sub-stream at any later time. A
PersistentView could just track one of the projected sub-streams.
For datastore implementations this would bring the minimum requirement to
construct sub-streams as told by the application and serve streams by name.
On (3):
On the query side of the application I see anything, that holds a view of
the data written on the command side and allows querying/consuming by some
criteria. As you wrote in your post, the variety of datastores is huge and
I'm not sure if the set of common queries is very big. I like the idea of
ad-hoc querying you proposed as it is a much more messaging like way to
query datastores but I see disperate sets of standardized queries per
datastore type (graph dbs, rdbms, key-value etc.) that focus on the
datatsore conceps (tables and rows in rdbms, nodes and edges in graph dbs -
something like QueryById(id, table) for RDBMS etc.) and not on messages. I
would very much like to see this kind of datastore querying but I don't
think it's neccessary for CQRS setups with akka.
As a user of a full akka-cqrs-solution the points to provide application
logic could be
- which messages to persist in (1)
- which projections to make for the application in (2)
- which project streams to consume from (2) in order to trigger
anything from query-side updates to creation of new commands for other
aggregates to updating a view in someone's browser
Kind regards
Markus
--
>>>>>>>>>> Read the docs: http://akka.io/docs/
>>>>>>>>>> Check the FAQ:
>>>>>>>>>> http://doc.akka.io/docs/akka/current/additional/faq.html
>>>>>>>>>> Search the archives: https://groups.google.com/group/akka-user
---
You received this message because you are subscribed to the Google Groups "Akka
User List" group.
To unsubscribe from this group and stop receiving emails from it, send an email
to [email protected].
To post to this group, send email to [email protected].
Visit this group at http://groups.google.com/group/akka-user.
For more options, visit https://groups.google.com/d/optout.
{kind=link}