ashb commented on issue #5743: [AIRFLOW-5088][AIP-24] Persisting serialized DAG in DB for webserver scalability URL: https://github.com/apache/airflow/pull/5743#issuecomment-528002396 Kaxil and I did some benchmarking of this with 50 dags, and we noticed a couple of things. First each of our dags was storing 1MB (Yes, Really!) of JSON data in the field of the serialized dag. (We need to sanitize the dag we were using a bit before testing it) Secondly something was taking a long time (about 4 seconds per dag) to call `Serialization.from_json` which was... slow. So we ran it through py-spy and got this flame graph: 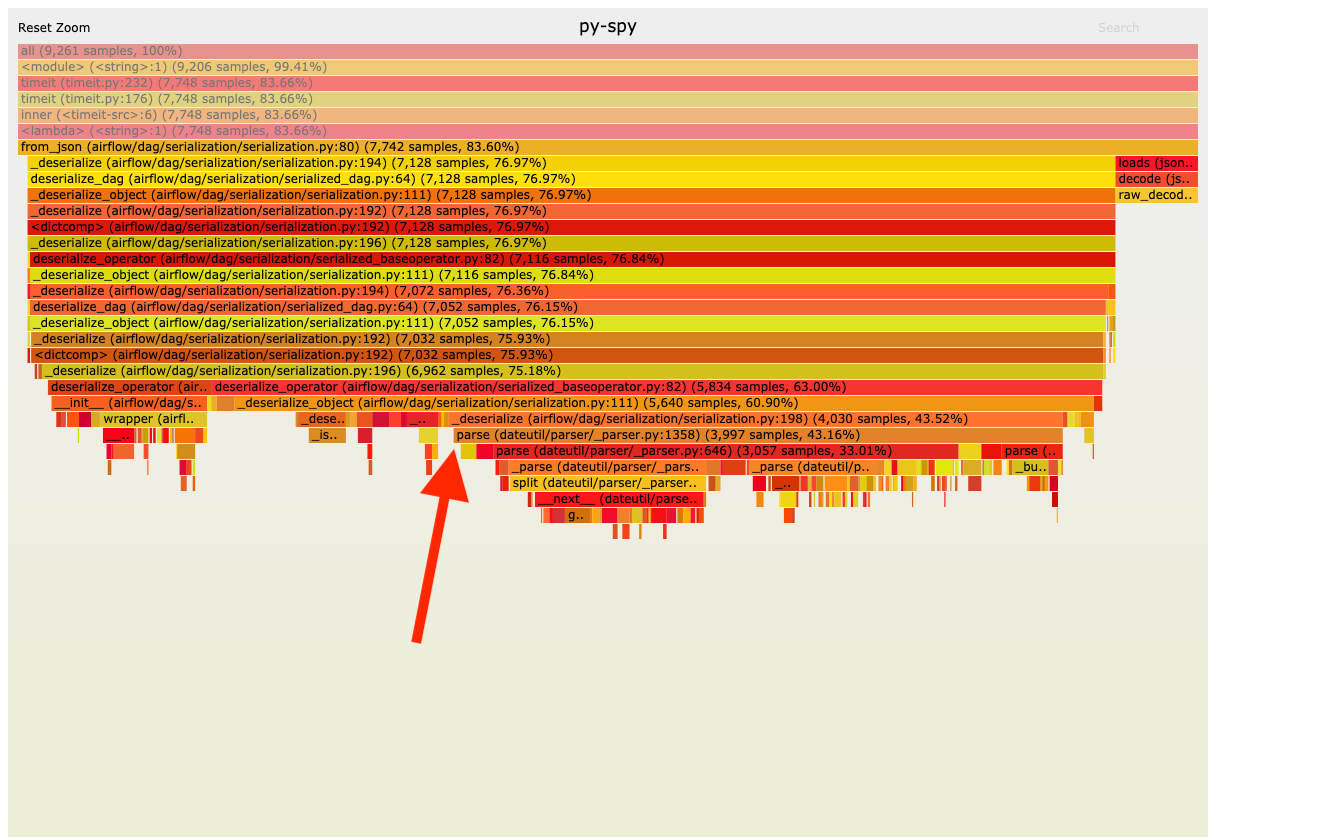 (Calls go from top, to bottom, the wider the bar the more time spent in a function or it's children) This shows us that we spent 43% of the time parsing dates! Oops! A bit of benchmarking of different parsing/storage methods ```python In [39]: %timeit dateutil.parser.parse(json.loads('"2019-09-04T17:57:59.869630+00:00"')) 158 µs ± 15 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) In [23]: %timeit pendulum.parse(json.loads('"2019-09-04T17:57:59.869630+00:00"')) 32.6 µs ± 2.36 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) In [24]: %timeit datetime.datetime.fromtimestamp(json.loads("1567616279.86963")) 4.91 µs ± 169 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) In [25]: %timeit datetime.datetime(*json.loads("[2019, 9, 4, 17, 57, 59, 869630]")) 5.47 µs ± 394 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) In [27]: %timeit pendulum.fromtimestamp(json.loads("1567616279.86963")) 42.6 µs ± 3.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) In [28]: %timeit pendulum.from_timestamp(json.loads("1567616279.86963")) 14.5 µs ± 1.11 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) In [29]: %timeit pendulum.from_timestamp(json.loads("1567616279.86963")) 14.5 µs ± 571 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) In [30]: %timeit pendulum.fromtimestamp(json.loads("1567616279.86963")) 44.4 µs ± 9.43 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) ``` So storing dates as fractional-seconds since the epoch and using `pendulum.from_timestamp` (but not `pendulum.fromtimestamp`!) will cut the parsing time from dates by a factor of 10 (158 µs ± 15 µs down to 14.5 µs ± 0.5 µs) which seems well worth it. The other thing to look at might be to store fewer dates. For instance I think (but haven't checked) that we are storing the start_date against the dag and against each and every operator -- we don't need to store it against the operators if it is the same value.
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services