[
https://issues.apache.org/jira/browse/AIRFLOW-3001?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16639364#comment-16639364
]
ASF GitHub Bot commented on AIRFLOW-3001:
-----------------------------------------
ubermen opened a new pull request #3885: [AIRFLOW-3001] Add index 'ti_dag_date'
to taskinstance
URL: https://github.com/apache/incubator-airflow/pull/3885
Sorry for recreate PR. (I had ruined master of my fork. It will be never
occured again.)
[ Description ]
There was no index composed of dag_id and execution_date. So, when scheduler
find all tis of dagrun like this "select * from task_instance where dag_id =
'some_id' and execution_date = '2018-09-01 ...'", this query will be using
ti_dag_state index (I was testing it in mysql workbench. I was expecting
'ti_state_lkp' but, it was not that case). Perhaps there's no problem when
range of execution_date is small (under 1000 dagrun), but I had experienced
slow allocation of tis when the dag had 1000+ accumulative dagrun. So, now I
was using airflow with adding new index ti_dag_date (dag_id, execution_date) on
task_instance table. I have attached result of my test :)
[ Test ] I have tested using 1.10 version
1. just running scheduler with past start_date and high concurrency. (3
years ago, 10 minute interval)
2. scheduler may be executing backfill and "select tis" query (like below
sequence)
models.py > DAG.run
jobs.py > BaseJob.run
jobs.py > BackfillJob._execute
jobs.py > BackfillJob._execute_for_run_dates
jobs.py > BackfillJob._task_instances_for_dag_run
models.py > DagRun.get_task_instances
tis = session.query(TI).filter(
TI.dag_id == self.dag_id,
TI.execution_date == self.execution_date,
)
3. wait until enough dagruns will be accumlate.
I can find that many slow query logs get to occur from mysql log file.
(query like below sample)
"select * from task_instance where dag_id = 'some_id' and execution_date =
'2018-09-01 ...'"
[ASIS] current
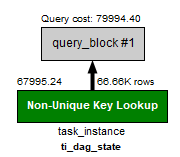
[TOBE] after adding new index

### Jira
- [ ] My PR addresses the following [Airflow
Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references
them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-XXX
- In case you are fixing a typo in the documentation you can prepend your
commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [ ] Here are some details about my PR, including screenshots of any UI
changes:
### Tests
- [ ] My PR adds the following unit tests __OR__ does not need testing for
this extremely good reason:
### Commits
- [ ] My commits all reference Jira issues in their subject lines, and I
have squashed multiple commits if they address the same issue. In addition, my
commits follow the guidelines from "[How to write a good git commit
message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [ ] In case of new functionality, my PR adds documentation that describes
how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation
generation needs to be added.
### Code Quality
- [ ] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
> Accumulative tis slow allocation of new schedule
> ------------------------------------------------
>
> Key: AIRFLOW-3001
> URL: https://issues.apache.org/jira/browse/AIRFLOW-3001
> Project: Apache Airflow
> Issue Type: Improvement
> Components: scheduler
> Affects Versions: 1.10.0
> Reporter: Jason Kim
> Assignee: Jason Kim
> Priority: Major
>
> I have created very long term schedule in short interval. (2~3 years as 10
> min interval)
> So, dag could be bigger and bigger as scheduling goes on.
> Finally, at critical point (I don't know exactly when it is), the allocation
> of new task_instances get slow and then almost stop.
> I found that in this point, many slow query logs had occurred. (I was using
> mysql as meta repository)
> queries like this
> "SELECT * FROM task_instance WHERE dag_id = 'some_dag_id' AND execution_date
> = ''2018-09-01 00:00:00"
> I could resolve this issue by adding new index consists of dag_id and
> execution_date.
> So, I wanted 1.10 branch to be modified to create task_instance table with
> the index.
> Thanks.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}
{kind=link}