alamb commented on code in PR #247:
URL: https://github.com/apache/arrow-site/pull/247#discussion_r997430055
##########
_posts/2022-10-01-arrow-parquet-encoding-part-3.md:
##########
@@ -0,0 +1,169 @@
+---
+layout: post
+title: Arrow and Parquet Part 3: Arbitrary Nesting with Lists of Structs and
Structs of Lists
+date: "2022-10-01 00:00:00"
+author: tustvold, alamb
+categories: [parquet, arrow]
+---
+<!--
+{% comment %}
+Licensed to the Apache Software Foundation (ASF) under one or more
+contributor license agreements. See the NOTICE file distributed with
+this work for additional information regarding copyright ownership.
+The ASF licenses this file to you under the Apache License, Version 2.0
+(the "License"); you may not use this file except in compliance with
+the License. You may obtain a copy of the License at
+
+http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+{% endcomment %}
+-->
+
+## Introduction
+
+This is the third of a three part series exploring how projects such as [Rust
Apache Arrow](https://github.com/apache/arrow-rs) support conversion between
[Apache Arrow](https://arrow.apache.org/) for in memory processing and [Apache
Parquet](https://parquet.apache.org/) for efficient storage. This post covers
how to combine the `Struct` and `List` types described in the previous posts
for arbitrary nesting.
+
+
+[Apache Arrow](https://arrow.apache.org/) is an open, language-independent
columnar memory format for flat and hierarchical data, organized for efficient
analytic operations. [Apache Parquet](https://parquet.apache.org/) is an open,
column-oriented data file format designed for very efficient data encoding and
retrieval.
+
+
+# Structs with Lists
+
+
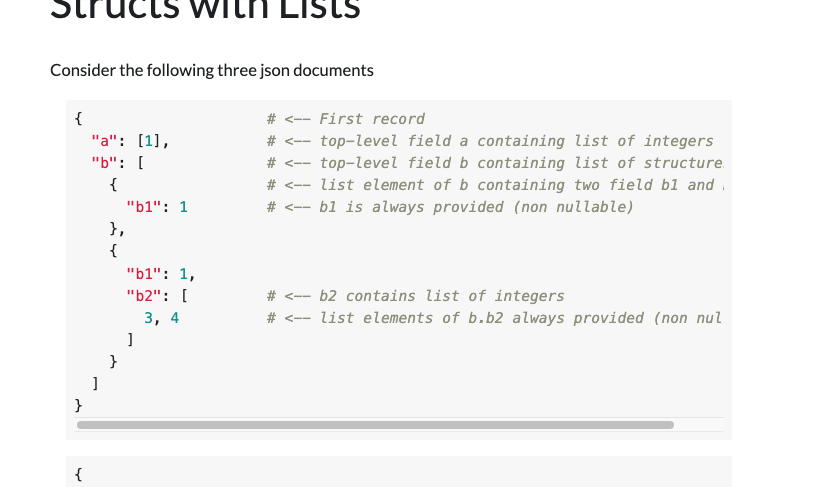
+```json
+{ <-- First record
+ “a”: [1], <-- top-level field a containing list of integers
+ “b”: [ <-- top-level field b containing list of structures
+ { <-- list element of b containing two field b1 and b2
+ “b1”: 1 <-- b1 is always provided (not null)
+ },
+ {
+ “b1”: 1,
+ “b2”: [ <-- b2 contains list of integers
+ 3, 4 <-- list elements of b.b2 always provided (not null)
+ ]
+ }
+ ]
+}
+{
+ “b”: [ <-- b is always provided (not null)
+ {
+ “b1”: 2
+ },
+ ]
+}
+{
+ “a”: [null, null], <-- list elements of a are nullable
+ “b”: [null] <-- list elements of b are nullable
+}
+```
Review Comment:
This is an excellent idea -- I tried it out and with some finagling it looks
quite good:
I will update this blog as well as the previous ones
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}