[
https://issues.apache.org/jira/browse/CASSANDRA-6474?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=13878160#comment-13878160
]
sankalp kohli commented on CASSANDRA-6474:
------------------------------------------
Yup make sense. We can have like 400 4 byte min hashes in memory.
> Compaction strategy based on MinHash
> ------------------------------------
>
> Key: CASSANDRA-6474
> URL: https://issues.apache.org/jira/browse/CASSANDRA-6474
> Project: Cassandra
> Issue Type: New Feature
> Components: Core
> Reporter: Yuki Morishita
> Labels: compaction
> Fix For: 3.0
>
>
> We can consider an SSTable as a set of partition keys, and 'compaction' as
> de-duplication of those partition keys.
> We want to find compaction candidates from SSTables that have as many same
> keys as possible. If we can group similar SSTables based on some measurement,
> we can achieve more efficient compaction.
> One such measurement is [Jaccard
> Distance|http://en.wikipedia.org/wiki/Jaccard_index],
> !http://upload.wikimedia.org/math/1/8/6/186c7f4e83da32e889d606140fae25a0.png!
> which we can estimate using technique called
> [MinHash|http://en.wikipedia.org/wiki/MinHash].
> In Cassandra, we can calculate and store MinHash signature when writing
> SSTable. New compaction strategy uses the signature to find the group of
> similar SSTable for compaction candidates. We can always fall back to STCS
> when such candidates are not exists.
> This is just an idea floating around my head, but before I forget, I dump it
> here. For introduction to this technique, [Chapter 3 of 'Mining of Massive
> Datasets'|http://infolab.stanford.edu/~ullman/mmds/ch3.pdf] is a good start.
--
This message was sent by Atlassian JIRA
(v6.1.5#6160)
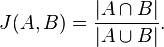{kind=link}