yihao-tcf commented on issue #14923: URL: https://github.com/apache/dolphinscheduler/issues/14923#issuecomment-1782138666
> I have also experienced such problems, which seriously affect the normal operation of scheduled tasks. **version**:3.1.7 > > **Reproduction steps** > > 1. Create Work groups > 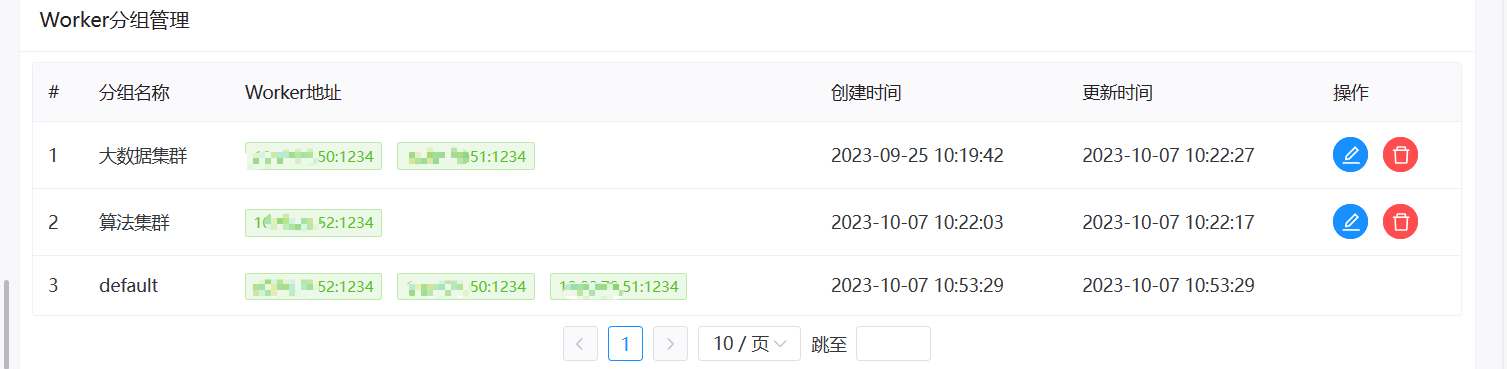 > 2. Create Test Tasks(Three different working groups) > Task 1 use '大数据集群' worker group > > 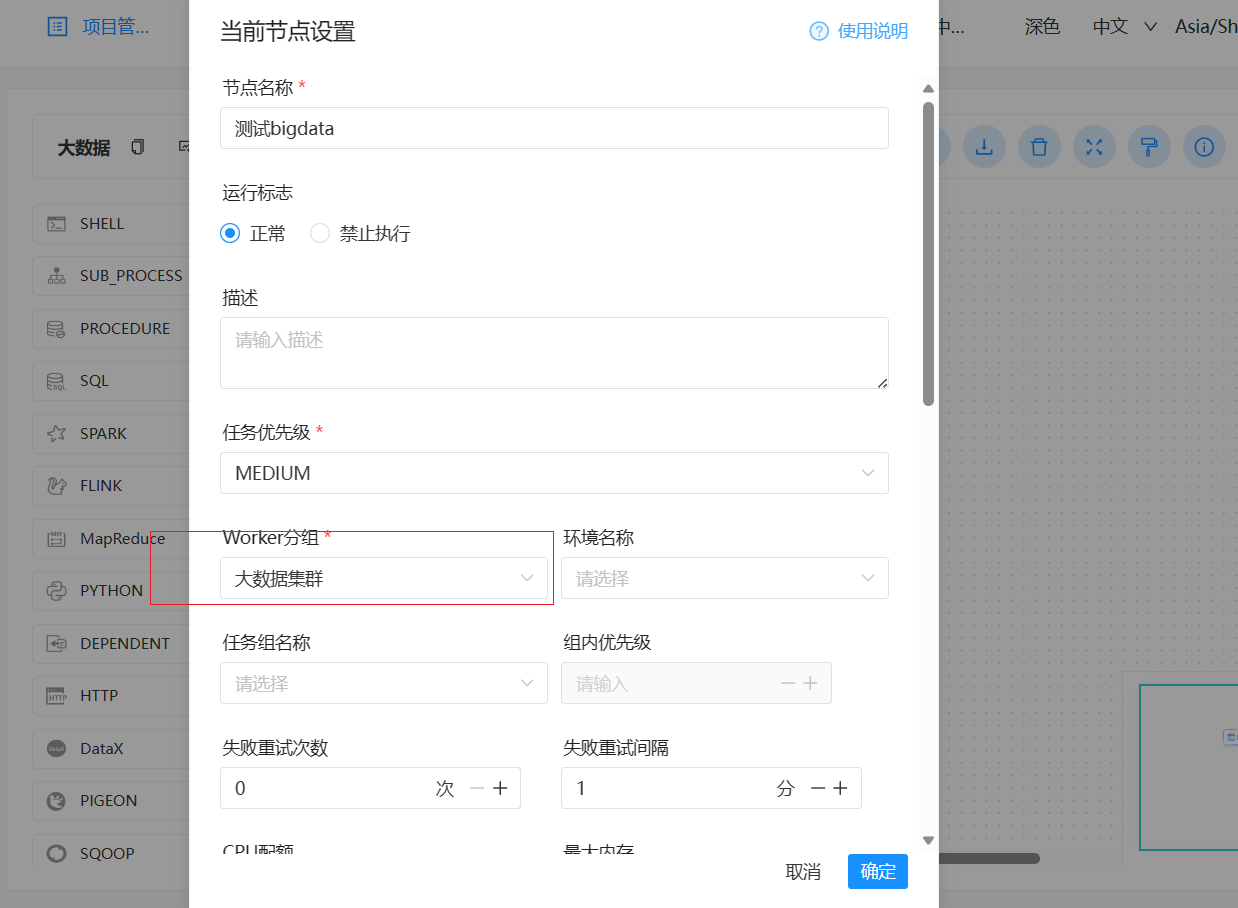 > > Task 2 use '算法集群' worker group > > 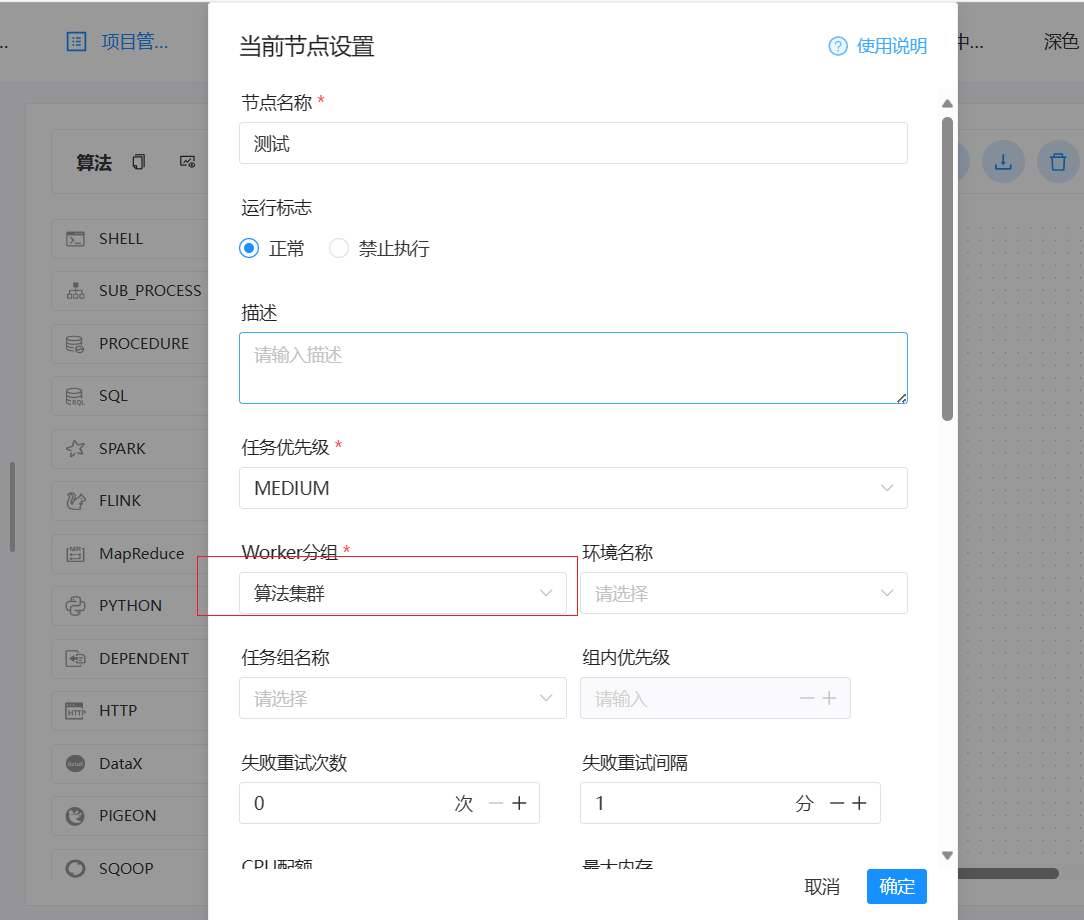 > > Task 3 use 'default' worker group > >  > > Set scheduled execution,online workflow and scheduling 3. Stop the worker of the '算法集群'`* * * * * ? *` 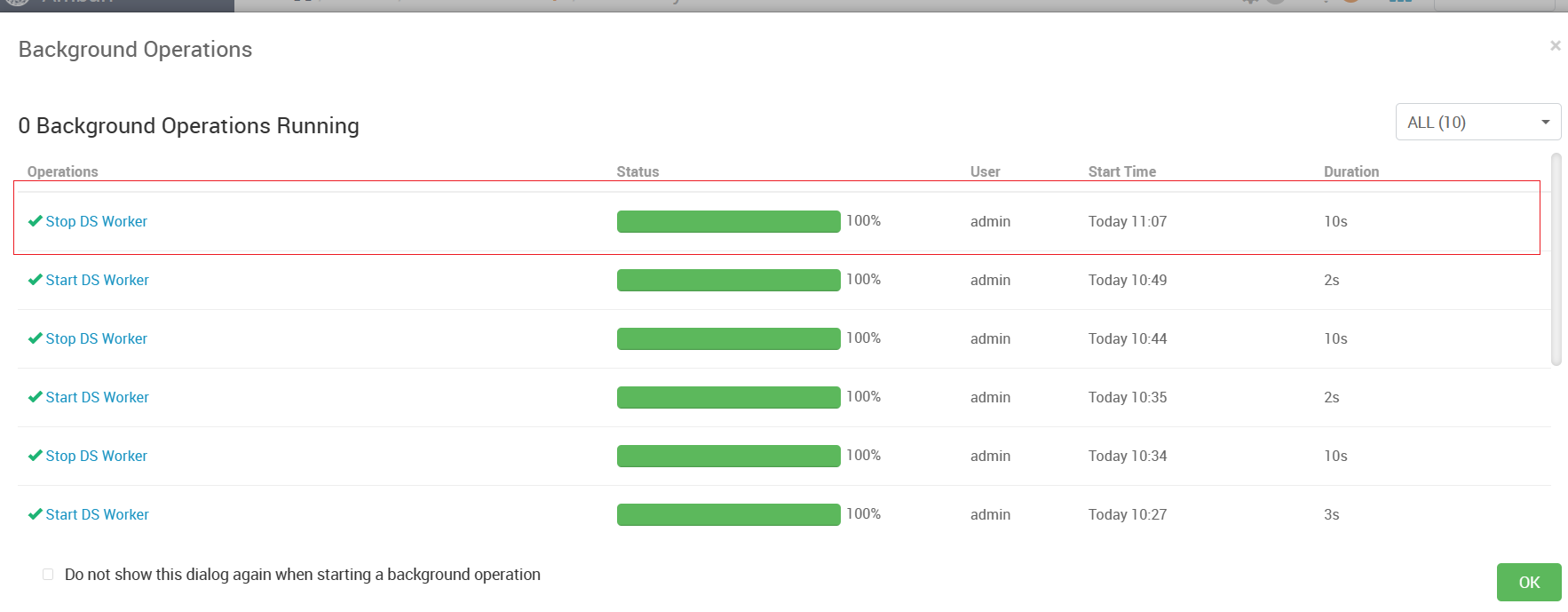 > > **After stopping, all tasks will be affected and an error will be reported as task instance is null or host is null.** > > After stopping woker group info: 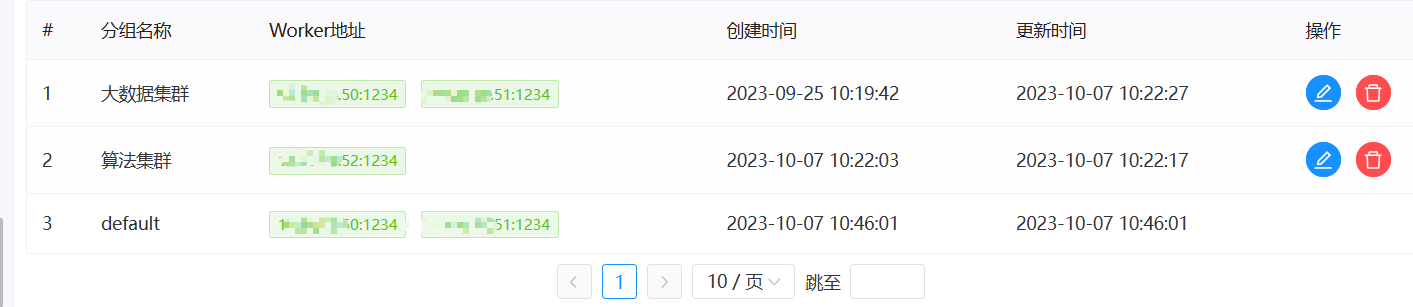 > > After stopping task execution status: 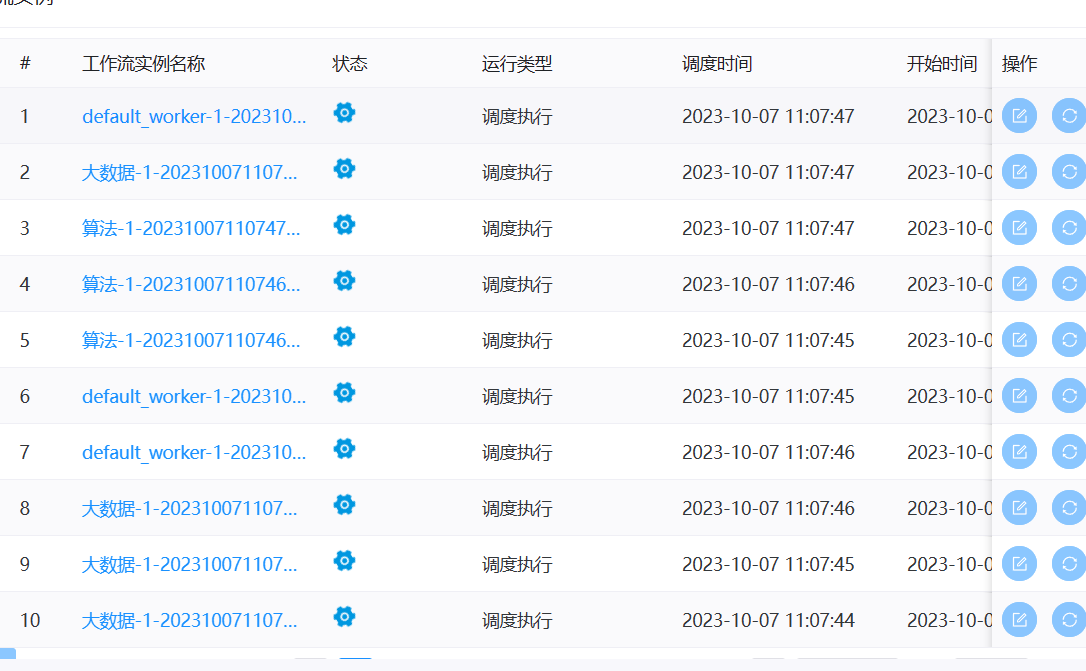 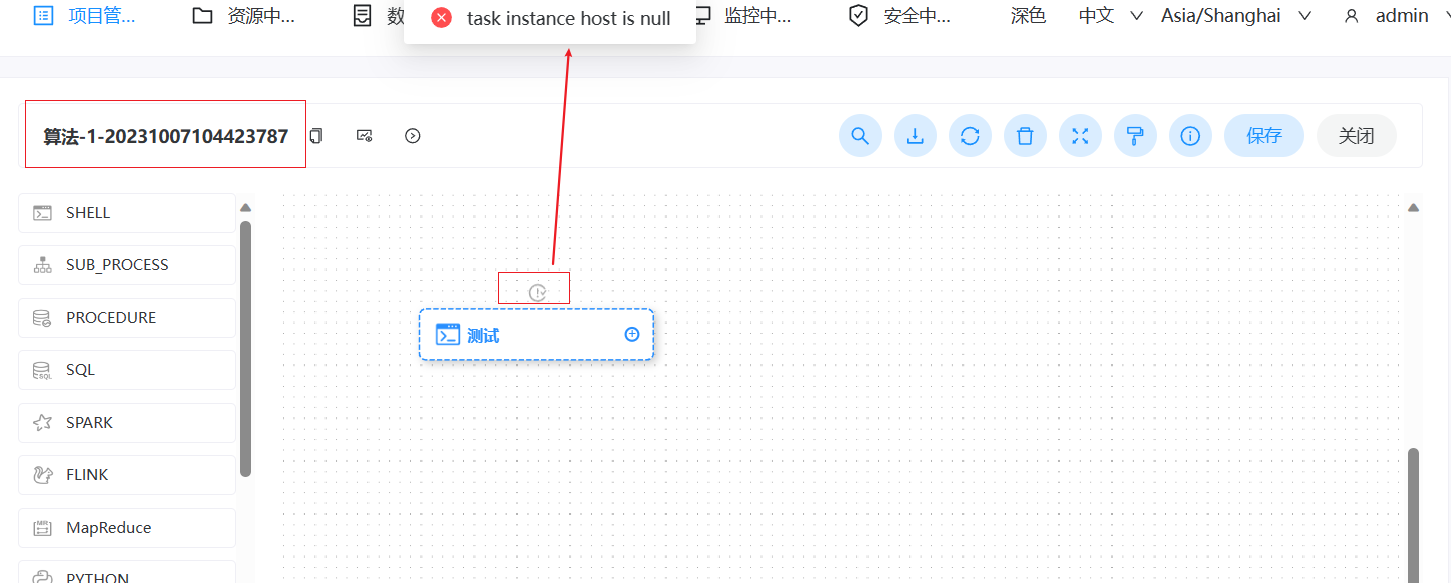 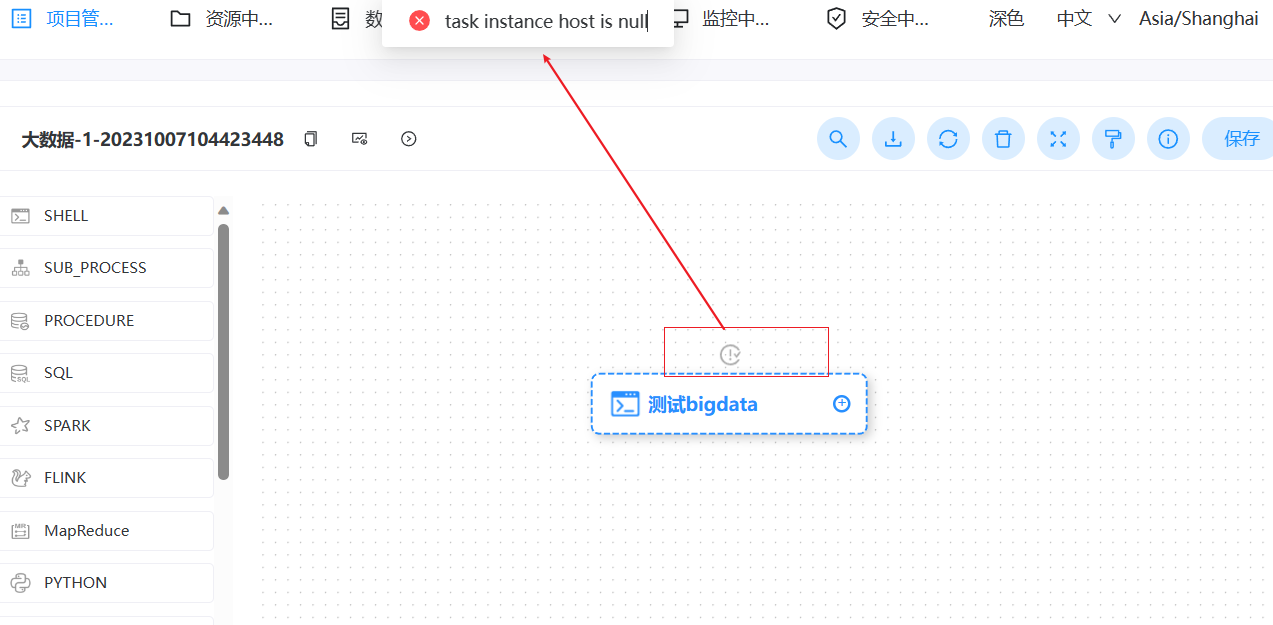 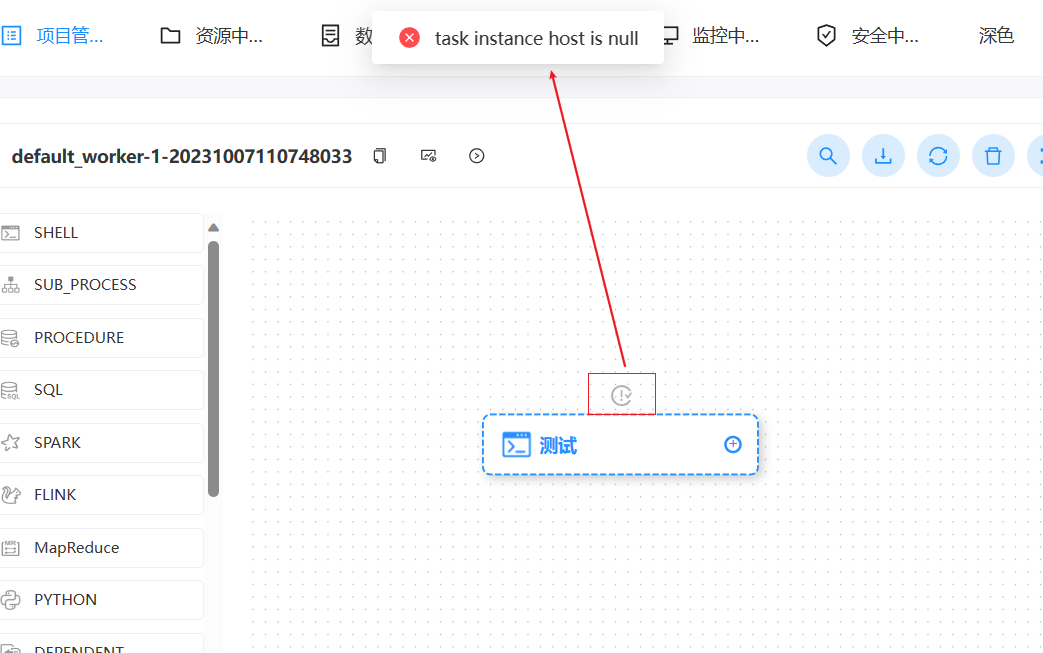 > > error logs message:  > > After starting the stopped worker, the task resumes execution. A large number of backlogged tasks are resuming execution, which may cause the cluster to be in a high load state and lead to the downtime of other services in the cluster. This is very dangerous > > I don't quite understand why the node downtime of the '算法集群' worker group affects the tasks of other worker group nodes @kezhenyang163 From the steps of replication, it can be seen that when the nodes corresponding to my "算法集群" workgroup were closed, the tasks of the "大数据集群" and "default" workgroups were also affected and could not work properly. I think this is very unreasonable, as one of the executor nodes goes down, causing all nodes in the current system to be affected. Do you think it's reasonable? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}