EricGao888 opened a new issue, #13316: URL: https://github.com/apache/dolphinscheduler/issues/13316
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar feature requirement. ### Description * Still WIP. * Discussions are more than welcome. ### Why we need it? * Higher resource utilization - The core idea is `one task per pod`. With the help of K8S metrics server, users could clearly get the resource consumption data for each task (both CPU and Memory) so that they could adjust and allocate suitable amount of resources based on the data to each specific task pod and achieve global minimum resource consumption. In the future, we might even use `K8S VPA` to automatically adjust the resource allocation. * Better monitoring (pod level, cloud native, K8S metrics server) * Easier fault tolerance * Faster iteration, for updating task plugin, there is no need to upgrade all workers. ### How to design it? #### Compatibility * Do some decoupling and abstraction work before adding a K8S executor. Make executor configurable. If users choose not to use `K8S Executor`, he will be able to use the current way - one worker per pod. #### Fault Tolerance * Make DS worker stateless in K8S environment (one task per pod) * DS worker does not need to rely on ZK. We could start a thread in K8S executor to interact with K8S watcher to subscribe to the state change event of worker pod. Since one task per pod, there is no need to decide which pod to resume the task execution if worker crashes, just start a new one. #### Communication With Master * Is it possible to use a simpler way instead of `Netty` for communication between worker and master in K8S environment? Such as a message queue? Since there is one task per pod and `K8S Executor` could kill the pod through K8S API server, looks like not necessary to use `Netty` server and client in worker in K8S environment. For logging, we could use PV or remote logging. Maybe we could find a simpler way for K8S Executor to pass `TaskExecutionContext` into worker. #### Combined With DS Hadoop Executor * For difference, we temporarily call current executor as DS HadoopExecutor. * There is no perfect solution, only trade-off. Pros and cons? * detach(async) vs attach(sync) - sync task, resource usage hard to estimate -> use Hadoop Executor (one worker per pod); async task, resource usage easy to estimate -> use K8S Executor (one task per pod) * Two queues for two executors: `HadoopTaskPriorityQueue` and `K8STaskPriorityQueue` * For Hadoop Executor (one worker one pod), we could add worker pod elasticity feature, also mentioned in #9337 One possible solution is to use `K8S HPA` and `KEDA` with the number of queued and running tasks as the metric. ## General Design (Not Detailed) ### K8S Executor 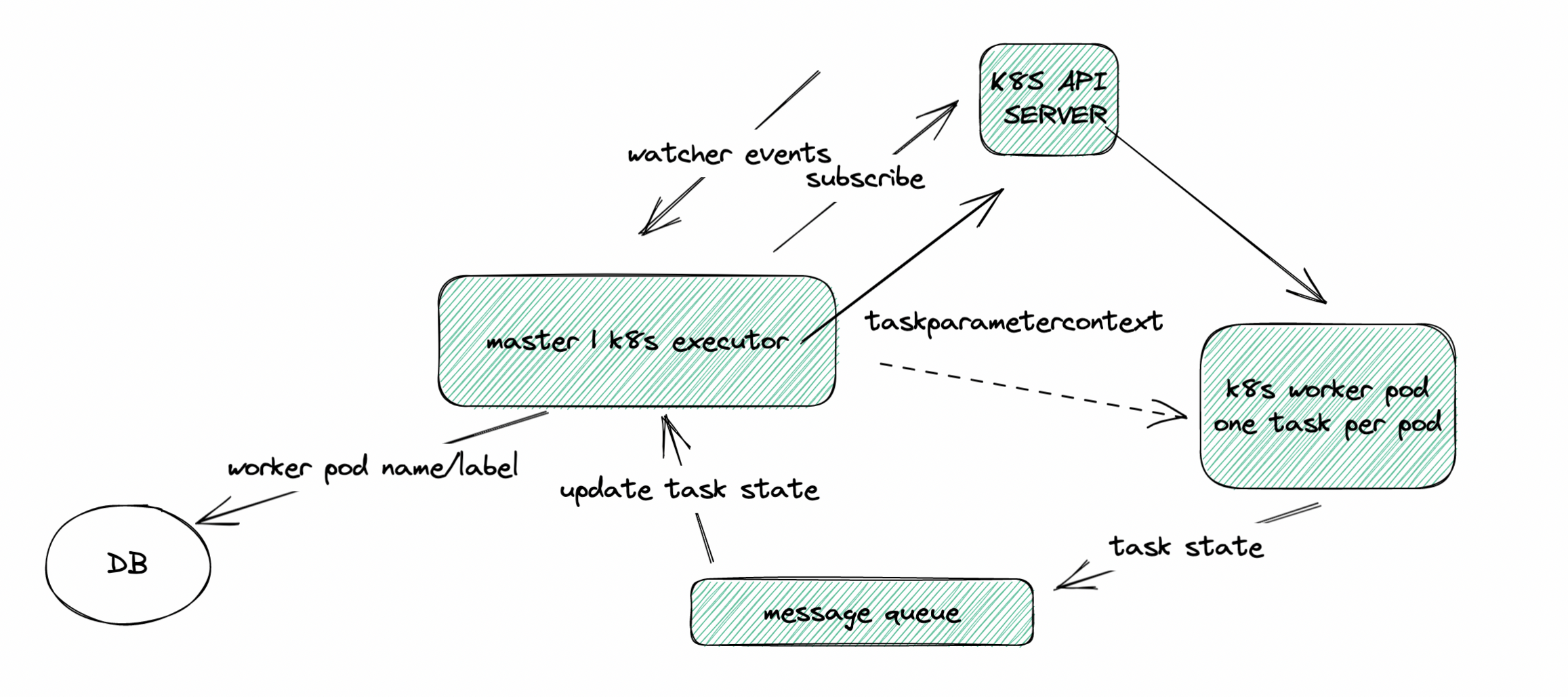 * With VPA: WIP * DS K8S Worker: WIP * Pros & Cons ### Compound Solution (K8S Executor + Hadoop Executor) 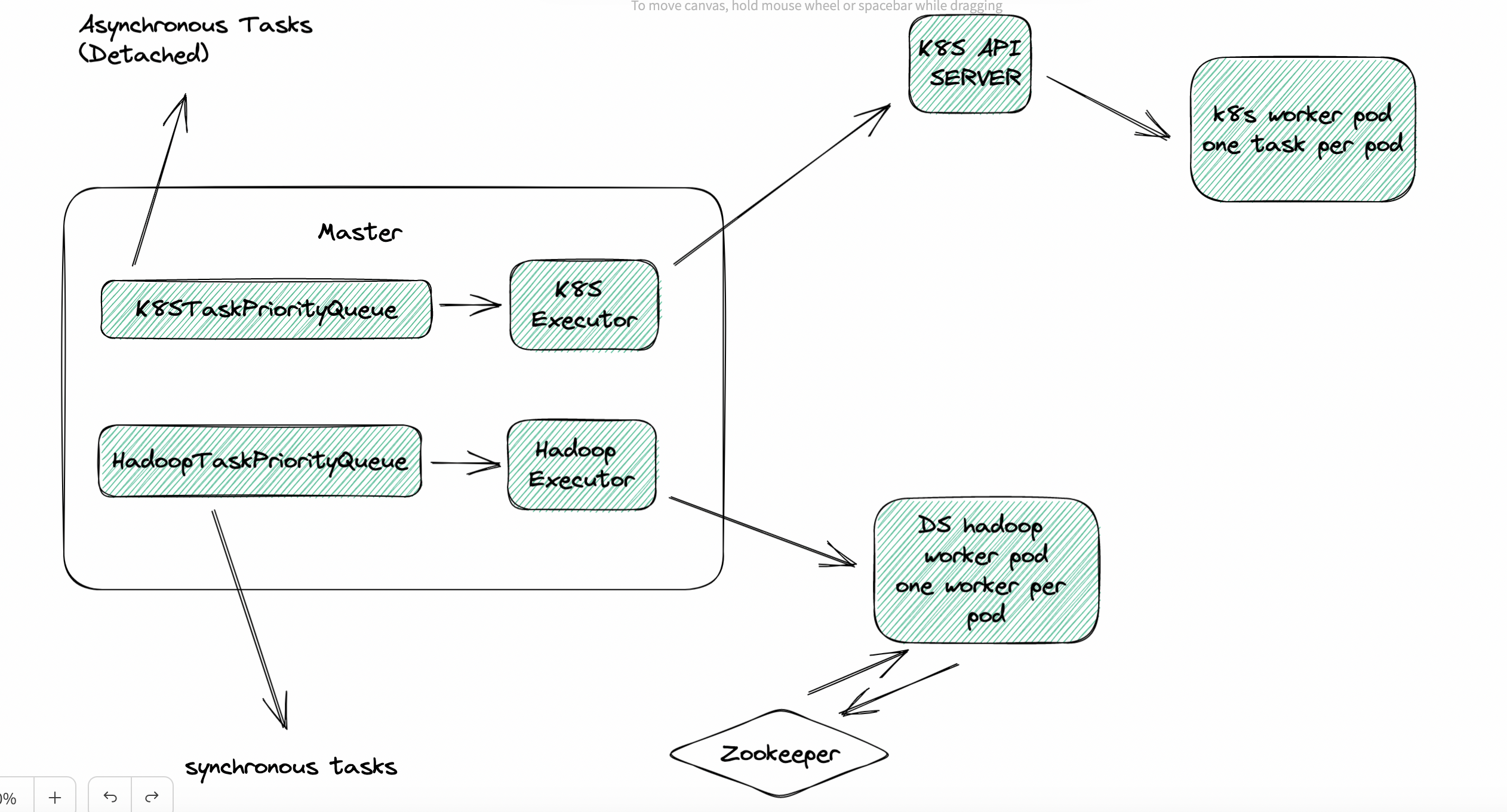 #### Asynchronous Tasks (Detach) #### Synchronous Tasks (Attach) #### Maximum Resource Utilization Rate ### Elastic Worker  ### RoadMap & Milestones * 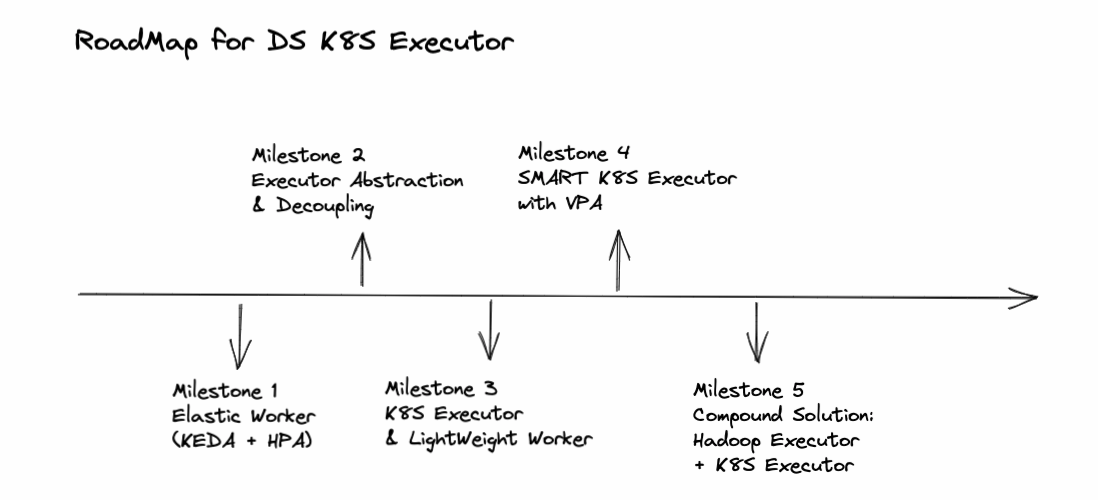 ### Sub-Tasks ### Are you willing to submit a PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}