github-actions[bot] commented on issue #6021: URL: https://github.com/apache/dolphinscheduler/issues/6021#issuecomment-903416279
**Steps to reproduce the behavior** Use shell script to encapsulate spark-submit command to submit spark task to yarn **Describe the question** A shell script is used to encapsulate the spark-submit command to execute a spark task. Some tasks are executed successfully but the dolphinscheduler returns a status of failure. But there are also some tasks in the workflow that dolphinscheduler returns successfully. And using the same shell script to execute hive tasks does not exist. **Environment Description:** dolphinscheduler:1.3.2 Hadoop version : 2.6.0-cdh5.13.3 Hive version : 1.1.0-cdh5.13.3 yarn.resourcemanager:single Storage (HDFS/S3/GCS..) : HDFS Running on Docker? (yes/no) :no **common.properties**  **shell script** #!/bin/bash sqlfile_name=$1 data_date=$2 curDay=`echo $data_date | cut -c 7-8` curMonth=`echo $data_date | cut -c 5-6` curYear=`echo $data_date |cut -c 1-4` curCal=`cal $curMonth $curYear` endDay=`echo $curCal | awk '{print $NF}'` #echo $endDay if [ "$curDay" -eq "$endDay" ] then echo "开始执行.sql文件" spark2-submit \ --class com.wecreditlife.framework.SparkExecSqlResApp \ --master yarn \ --deploy-mode cluster \ --driver-memory 1G \ --num-executors 2 \ --executor-memory 1G \ --executor-cores 4 \ --conf spark.yarn.executor.memoryOverhead=512 \ --conf spark.yarn.driver.memoryOverhead=512 \ /opt/xysh/xysh-udf-project-1.0-SNAPSHOT.jar ${sqlfile_name} ${data_date} echo "执行完毕" else echo "ignore" fi **Additional context:** 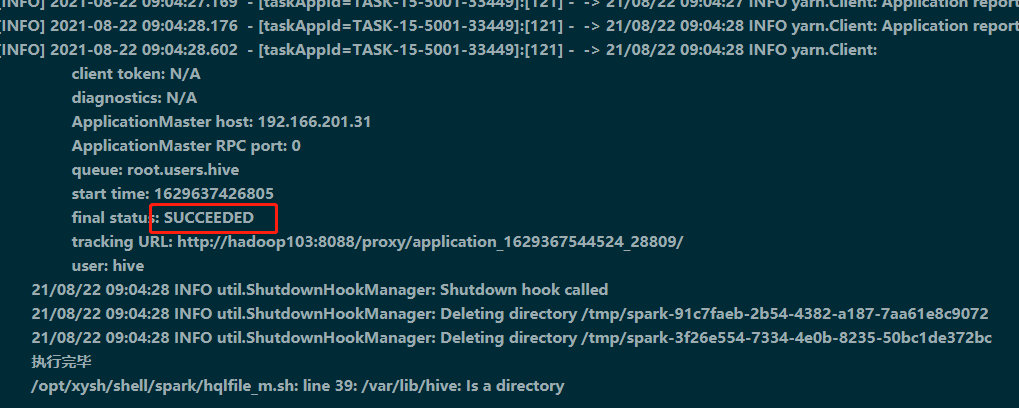  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}