This is an automated email from the ASF dual-hosted git repository.
zhongjiajie pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/dolphinscheduler-website.git
The following commit(s) were added to refs/heads/master by this push:
new b41434427 Add new article for Python API and change some logos (#826)
b41434427 is described below
commit b414344271f933d1641b8c40f1afa860e55feee9
Author: lifeng <[email protected]>
AuthorDate: Mon Sep 19 10:25:41 2022 +0800
Add new article for Python API and change some logos (#826)
---
.../Introducing-Apache-DolphinScheduler-1.3.9.md | 2 -
blog/en-us/Python_API_and_AWS_Support.md | 327 +++++++++++++++++++++
blog/zh-cn/YouZan-case-study.md | 240 ---------------
img/ourusers/[email protected] | Bin 14265 -> 5116 bytes
img/ourusers/[email protected] | Bin 23263 -> 681 bytes
img/ourusers/[email protected] | Bin 22781 -> 8754 bytes
img/ourusers/[email protected] | Bin 11128 -> 70590 bytes
img/ourusers/[email protected] | Bin 22211 -> 65265 bytes
site_config/blog.js | 16 +-
site_config/home.jsx | 15 +-
10 files changed, 343 insertions(+), 257 deletions(-)
diff --git a/blog/en-us/Introducing-Apache-DolphinScheduler-1.3.9.md
b/blog/en-us/Introducing-Apache-DolphinScheduler-1.3.9.md
index 018453c60..c512d3647 100644
--- a/blog/en-us/Introducing-Apache-DolphinScheduler-1.3.9.md
+++ b/blog/en-us/Introducing-Apache-DolphinScheduler-1.3.9.md
@@ -1,6 +1,5 @@
# Introducing Apache DolphinScheduler 1.3.9, StandaloneServer is Available!
-[](https://imgpp.com/image/OQFd4)
On October 22, 2021, we are excited to announce the release of Apache
DolphinScheduler 1.3.9. After a month and a half,Apache DolphinScheduler 1.3.9
brings StandaloneServer to users with the joint efforts of the community.
StandaloneServer is a major update of this version, which means a huge leap in
ease of use, and the details will be introduced below. In addition, this
upgrade also fixes two critical bugs in 1.3.8.
@@ -57,7 +56,6 @@ DolphinScheduler assembles Tasks in the form of DAG (Directed
Acyclic Graph), wh
According to incomplete statistics, as of October 2020, 600+ companies and
institutions have adopted DolphinScheduler in production environments. Partial
cases are shown as below (in no particular order).
-[](https://imgpp.com/image/OQylI)
## 3 Participate in Contribution
diff --git a/blog/en-us/Python_API_and_AWS_Support.md
b/blog/en-us/Python_API_and_AWS_Support.md
new file mode 100644
index 000000000..cc33df626
--- /dev/null
+++ b/blog/en-us/Python_API_and_AWS_Support.md
@@ -0,0 +1,327 @@
+---
+title:Apache DolphinScheduler Extends Capabilities Through Python API and AWS
Support
+keywords: Apache,DolphinScheduler,scheduler,big
data,ETL,airflow,hadoop,orchestration,dataops,Meetup
+description: Today, Apache DolphinScheduler announced the official release of
version 2.0.5.
+---
+# Apache DolphinScheduler Extends Capabilities Through Python API and AWS
Support
+
+In the ever-changing world of technology, data is abundant. In fact, trillions
of gigabytes of data are generated every day!
+
+Stop and think about that for a second!
+
+Storing and processing these humongous amounts of data is no easy feat. Big
data workflow schedulers such as the Apache DolphinScheduler and Apache Airflow
help businesses perform operations on large volumes of data.
+
+Let’s take a deep dive and look at two prominent features of Apache
DolphinScheduler: **PyDolphinScheduler and AWS support.**
+
+Happy reading!
+
+About PyDolphinScheduler
+Before we formally define PyDolphinScheduler, let’s take a deep dive and
understand what Apache DolphinScheduler does.
+
+Apache DolphinScheduler is a distributed and extensible workflow scheduler
platform that offers powerful DAG visual interfaces, helping data scientists
and analysts author, schedule, and monitor batch data pipelines smoothly
without needing heavy code.
+
+
+
+
+While users of Apache DolphinScheduler can monitor and tunnel Directed Acyclic
Graphs (DAG) through its drag-and-drop visual interface (we’ll talk more on
this later), Apache DolphinScheduler lets users implement workflows through
Python code for the best control over their workflows.
+
+With this in mind, let’s formally define PyDolphinScheduler.
+
+According to their website,
+
+“PyDolphin Scheduler is the Python API for Apache DolphinScheduler, which
allows you to define your workflows through Python code, aka workflow-as-codes.”
+
+In essence, the DolphinScheduler Python API is a wrapper for the workflow
scheduler that lets you easily create and define workflows. You can still run
and monitor all your workflows through the visual DAG interface, making
DolphinScheduler an attractive option compared to Apache Airflow and Apache
Azkaban.
+
+
+
+You get the best of both worlds: the innate versatility of the Python code
followed by the intuitive ease of using the visual drag-and-drop interface.
+
+The rate at which data is generated has blown out of proportion in the 21st
century.
+
+According to Cisco, the global internet traffic is estimated to be around one
zettabyte per year!
+
+Let’s stop short and put this into perspective. If each brick of the Great
Wall of China measures 1 gigabyte, this hypothetically means that you could
build a whopping 258 Great Walls of China with a single zettabyte!
+
+
+The burden of analyzing vast amounts of data can be clearly seen here.
+
+That’s what makes Python one of the best programming languages for analysis,
maintenance, and deployment. Since Python is typically employed for data
analytics and pipelines, PyDolphinScheduler is the perfect way to define your
workflows.
+
+Python is also extensively used by machine learning and artificial
intelligence teams and also in schedulers and various libraries.
+
+## Benefits of Visual DAG
+Let’s check out the benefits of having a visual DAG interface.
+
+Since its release in 2016, Apache Airflow has become quite popular among data
scientists and engineers.
+
+But there was a caveat.
+
+While developers of Airflow’s code-first philosophy positively impacted the
platform’s versatility, it proved disastrous at times. For example, developers
often found maintaining and troubleshooting errors through code extremely hard
and time-consuming.
+
+This is where Apache DolphinScheduler shone through. Users now could create
and define workflows easily through PyDolphinSceduler and then utilize the
visual DAG interface to monitor the workflows.
+
+
+In addition, Apache DolphinScheduler had one of the best visual suspension and
error handling features: something that was unavailable in Apache Airflow,
which agonized users a lot.
+
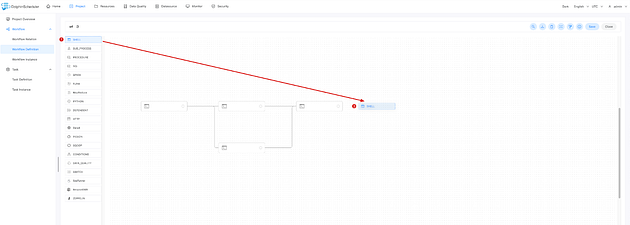
+To show you how easy it is to create and run workflows in DolphinScheduler
using the visual DAG method, here’s an example:
+
+You can drag-and-drop tasks to create or add them to existing workflows.
+
+
+
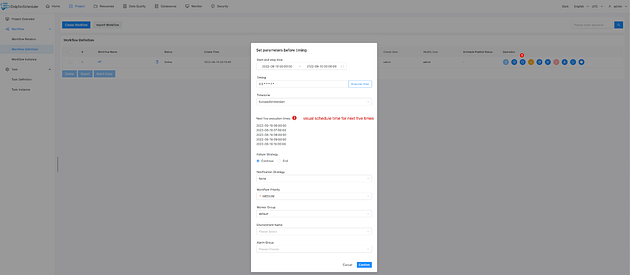
+In addition, you can visually check and schedule the timing, including start
time, end time, timezone, and Crontab expressions. Furthermore, you can
visually set timing in advance for the next, say, 5 times.
+
+
+
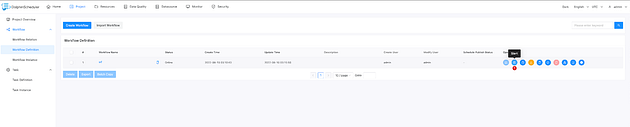
+If you wish to manually trigger the workflow, you can do so through the start
button. After clicking on the start button, you can see the workflow instance
and running status in the ‘Workflow Instance’ page.
+
+
+
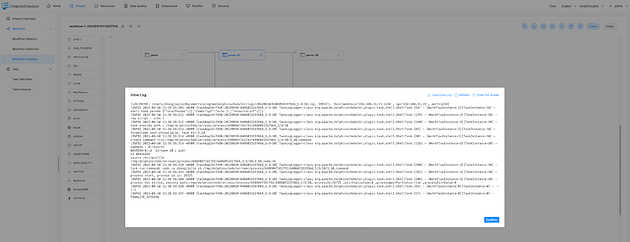
+In addition, you can also view the task log for specific workflow instances.
+
+
+
+See how easy it is to handle workflows through the visual DAG interface?
+
+## What is No-Code Workflow?
+In the early days of data engineering, scientists found it extremely hard to
merge specific actions with code.
+
+For example, let’s say a database is about to run out of storage. Most likely,
engineers would have some sort of troubleshooting or monitoring system in
place. In addition, they had to verify whether it was a false alarm, then
create a bigger instance, move the data, and redirect services to the new one —
all the while testing for data integrity.
+
+Soon engineers realized that many of these steps could be automated through
workflows with code.
+
+A workflow, after all, is a set of tasks with dependencies between them.
+
+For big data, powerful schedulers like Apache Airflow and Apache
DolphinScheduler helps users create workflows as codes, specifically in the
form of Directed Acyclic Graphs. In workflow-as-a-code, the tasks are
well-defined through precise inputs and outputs — making this system an
excellent leap for data scientists and engineers.
+
+While it has benefits in and of itself, such as optimized performance and
modeling, workflow-as-code has its own flaws.
+
+Firstly, it requires significant expertise in Python coding just to execute
the workflow.
+
+Secondly, since the data comes out in the form of code, deciphering data and
valuable information at a higher level is a daunting task.
+
+Thirdly, making changes, monitoring, and handling errors is a nightmare when
it comes to the code-only approach.
+
+That’s why Apache DolphinScheduler employs a visual DAG interface to address
these problems.
+
+With the no-code workflow, even beginners and non-technical users can execute
workflows and monitor them. The drag-and-drop capability allows users to easily
envision data and overall logic — which is not available in Apache Airflow.
+
+Furthermore, this also reduces errors, which, when paired with Apache
DolphinScheduler’s error handling methods, can vastly improve performance,
productivity, and efficiency.
+
+## Installing PyDolphinScheduler
+To get started with PyDolphinSchduler, you must have Python and pip installed
on your machine.
+
+## Installing Python
+Installing Python and pip varies depending on the operating system you use.
This Python Wiki offers detailed installation guides for various systems.
+
+For PyDolphinScheduler, I recommend using Python 3.6 and above. For smoother
usage, ensure that you install stable releases instead of beta versions.
+
+Once you’ve downloaded and installed Python, verify if your installation is
successful by typing:
+
+python — version.
+
+You’ll see details about the installed Python version if your installation was
successful.
+
+## Installing PyDolphinScheduler
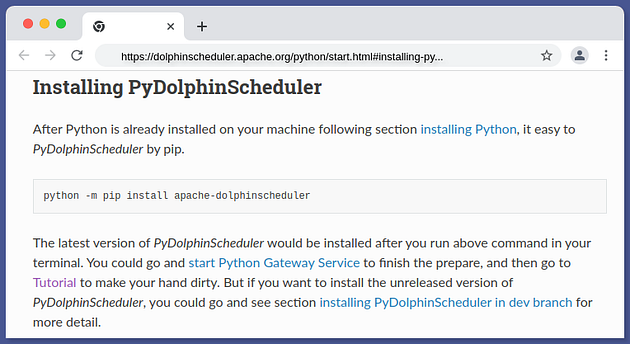
+The next step is to install PyDolphinScheduler by using pip.
+
+Here’s the terminal command:
+
+python -m pip install apache-dolphinscheduler
+
+This’ll install the latest version of PyDolphinScheduler.
+
+
+
+## Starting the Python Gateway Service
+Since PyDolphinScheduler is the Python API for Apache Dolphin Scheduler, you
need to install it before you can run workflows. You can define workflows and
task structures, though.
+
+Here’s a detailed guide to help you install Apache DolphinScheduler.
+
+## Task Dependencies and Types
+A task is a basic unit of execution in PyDolphinScheduler.
+
+In essence, tasks are the nodes of a Directed Acyclic Graph, i.e., they are
arranged into DAGs. Tasks have downstream and upstream dependencies set between
them, which helps express the order they should execute in.
+
+Tasks are declared using this command:
+
+pydolphinscheduler.tasks.Shell
+
+This command requires a parameter name and command.
+
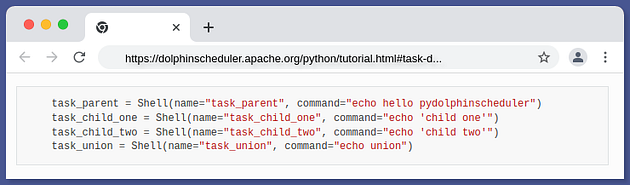
+Here are four examples of task declaration:
+
+
+
+PyDolphinScheduler has numerous task types:
+
+Python Function Wrapper
+Shell
+SQL
+Python
+HTTP
+Switch
+Condition
+Map Reduce
+Procedure
+Datax
+Sub Process
+Flink
+Task dependencies are the order in which tasks must be performed.
+
+One of the critical aspects of using tasks is defining how each task relates
to one another, specifically the upstream and downstream tasks.
+
+Firstly, you declare the tasks, and then you declare their dependencies.
+
+Setting task dependence is quite easy. You can use the following:
+
+set_downstream or >>
+set_upstream or <<
+Let’s take an example to illustrate the point.
+
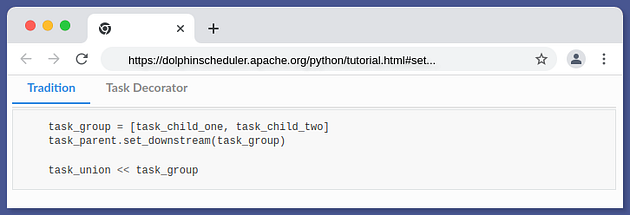
+In the following code, task_parent is the leading task of the entire workflow.
+task_child_one and task_child_two are the two downstream tasks
+The task called task_union will not run unless both the task_child_one and
task_child_two are done, as they are upstream.
+
+
+## Useful PyScheduler Documentation Links
+To learn more about PythonScheduler, refer to these links:
+
+PyDolphinScheduler homepage
+Installation guide for PyDolphinScheduler
+PyDolphinScheduler tutorials
+PyDolphinScheduler tasks
+## About AWS Support
+Let’s get straight to the point.
+
+Amazon Web Services offers a fully integrated portfolio of various
cloud-computing services to help developers and data engineers build, deploy,
and manage big data applications.
+
+The best thing about AWS?
+
+There’s no need to worry about hardware procurement or fret over
infrastructure maintenance. This helps you focus resources and time on building.
+
+
+
+So, why are we talking about AWS here?
+
+The success of Apache DolphinScheduler’s visual DAG interface heralded many
international users. While these users loved DolphinScheduler’s capabilities,
most of their projects involved overseas vendors such as AWS.
+
+Without dedicated support for AWS, many users were frustrated. This prompted
the developers at DolphinScheduler to implement support for the vendor.
+
+In the first quarter of 2022, developers added support for some of the most
popular tools and services. This proved to be one of the most significant
additions to Apache DolphnScheduler.
+
+Apache DolphinScheduler now supports Amazon EMR and Amazon Redshift. In
addition, there’s resource center support for Amazon S3, too.
+
+Let’s take a deep dive into these task types and look at how they have
dramatically changed the way developers use Apache DS.
+
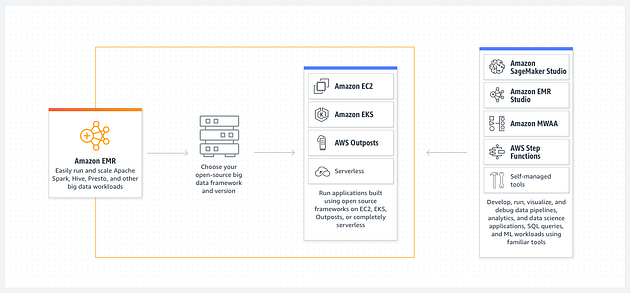
+### Amazon EMR
+Amazon EMR, formerly known as the Amazon Elastic MapReduce, is a managed
cluster platform that aims to simplify operating big data frameworks —
including Apache Spark and Apache Hadoop — on AWS to analyze copious amounts of
data.
+
+
+
+Furthermore, Amazon EMR offers the capability to transform and transfer large
volumes of data into and out of other AWS services, like Amazon S3 for data
stores and Amazon DynamoDB for databases.
+
+So how does Amazon EMR support help Apache DolphinScheduler users?
+
+AWS integration: Having support for Amazon EMR means users can get the best of
both worlds, with Amazon EMR’s flexibility, scalability, reliability, and quick
deployment. Users who have already used Amazon services can now easily define
and schedule their workflows on Apache DolphinScheduler.
+
+In addition, Amazon EMR offers robust security features by leveraging other
services such as IAM and Amazon VPC to help secure data and clusters.
+
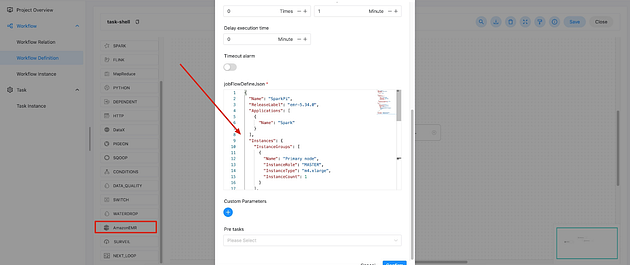
+Combining Apache DolphinScheduler’s error detection and handling features with
Amazon EMR’s management interfaces and log files can troubleshoot issues and
failures quickly.
+
+
+
+DS now has support for ‘RunJobFlow’ feature of Amazon EMR, which allows users
to submit multiple steps to the service and specify the number of resources to
be used.
+
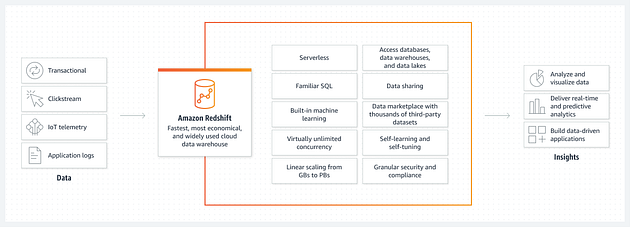
+### Amazon RedShift
+Amazon Redshift is a data warehouse that “uses SQL to analyze both structured
and semi-structured data lakes, operational databases, and data warehouses
through AWS-designed hardware and machine learning to deliver the best ROI at
all scales.
+
+
+
+It helps collaborate and share data, optimizes business intelligence, improves
demand forecast, and above all, increases developer productivity.
+
+Again, how does adding Amazon RedShift to DolphinScheduler benefit users?
+
+Amazon RedShift allows users to focus on getting insights from data within
seconds for various needs without worrying about managing the complete data
warehouse. It also helps run predictive analytics on complex and scaled data
across data lakes, databases, and even third-party data sets.
+
+In addition, users can get up to 3X better price performance compared to other
cloud data warehouses through RedShift’s automated optimizations aimed at
improving query speed.
+
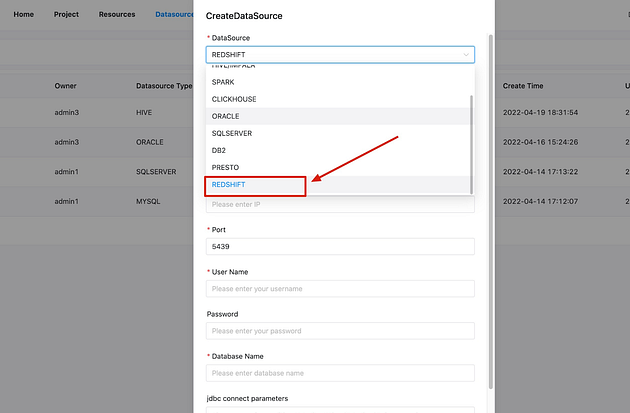
+And just like Amazon EMR, RedShift also benefits greatly from AWS’s
comprehensive security capabilities by providing data security out of the box
(without any additional cost).
+
+
+
+Apache DolphinScheduler has now extended support for Amazon RedShift data
sources for SQL task types. Users can run RedShift tasks by selecting the
“RedShift” data source in the SQL task type. For a quick recap, SQL task type
is used to connect to databases and execute SQL commands.
+
+### Amazon S3
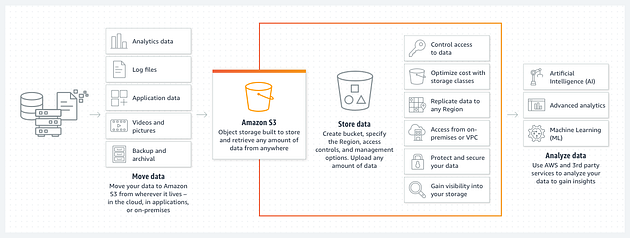
+Amazon S3, or Amazon Simple Storage Service, is an object storage service that
offers powerful scalability, performance, and security. Users can leverage
Amazon S3 to store and protect large amounts of data for multiple use cases,
including data lakes, websites, mobile applications, big data analytics, and
more.
+
+
+
+Let’s pose the same question: How do Apache DolphinScheduler users benefit
from this support addition?
+
+Amazon S3 is one of the cutting-edge technologies in cloud data storage and
offers numerous benefits at a very low cost. Coupled with the ease of migration
and simplicity in management, users can gather and store copious amounts of
data reliably and securely.
+
+
+
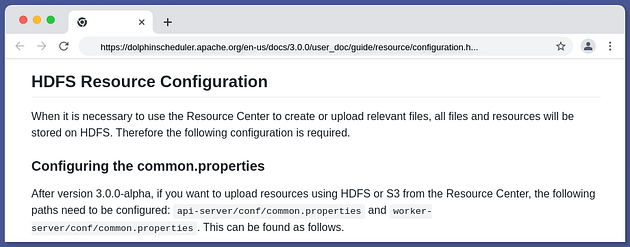
+Apache DolphinScheduler’s resource center now supports Amazon S3 for uploading
resources, adding to its already impressive support for local and HDFS resource
storage.
+
+Here’s a brief guide on how to use DolphinScheduler’s resource center:
+
+The resource center is used for uploading files, UDF functions, and task group
management.
+
+
+
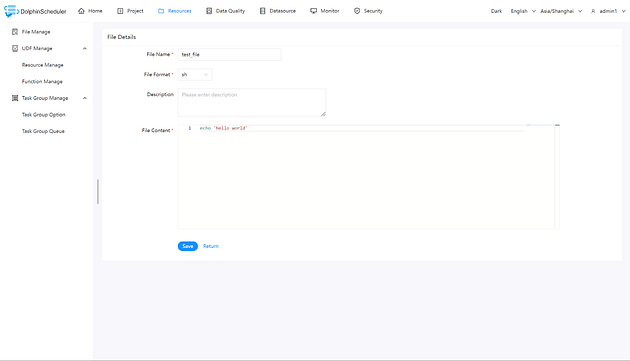
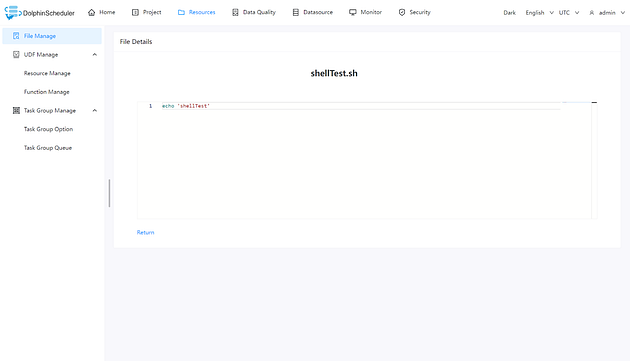
+Creating files: You can create files — supported file formats include txt, py,
sql, xml, and more.
+
+
+
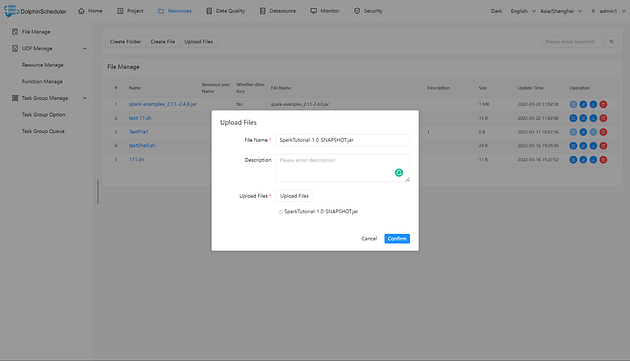
+Uploading files: Users can click the “Upload file” button or even
drag-and-drop files.
+
+
+
+Viewing files: Users can click on files that are viewable and check out the
file details.
+
+For more information about the resource center, please visit this link.
+
+Future Support
+Apache DolphinScheduler also has two more future additions in their pipelines:
Amazon Athena and AWS DataSync.
+
+These exciting additions will add more functionalities to the robust scheduler
platform, paving the way for more inclusive projects and business processes.
+
+
+
+Useful AWS Support Documentation Links
+To learn more about AWS in DolphinScheduler, refer to these links:
+
+* Amazon EMR
+* Amazon RedShift
+* Amazon S3
+
+Conclusion
+Apache DolphinScheduler makes scheduling workflows a breeze with its DAG
interface, multiple task types, no-code workflows, and more. PyDolphinScheduler
streamlines the process of defining tasks, and the recent support for AWS
platforms immensely boosts the scheduler’s capabilities.
+
+
+Apache DolphinScheduler’s popularity grew as it is used by tech giants,
including Lenovo, IBM China, and Dell.
+
+This exhaustive guide covered the basics to help you gain a brief
understanding of PyDolphinScheduler and AWS components. We hope this article
prompts you to go out and experiment with the features for yourself.
+
+Adios!
+
+Join the Community
+There are numerous ways and channels to participate and contribute to the
growing DolphinScheduler community. Some ways you can do so: Documentation,
translation, testing, Q&A, keynote speeches, articles, and more.
+
+Check out the comprehensive guide explaining how to participate in the
contribution.
+
+Check these links for issues compiled by the community:
+
+For novices
+For experts/non-newbies
+Useful links:
+
+Github repository
+Official website
+Youtube
+Slack
+Mailing list: dev@[email protected]
+Twitter handle: @DolphinSchedule
diff --git a/blog/zh-cn/YouZan-case-study.md b/blog/zh-cn/YouZan-case-study.md
deleted file mode 100644
index 16546c2c7..000000000
--- a/blog/zh-cn/YouZan-case-study.md
+++ /dev/null
@@ -1,240 +0,0 @@
-
-## 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
-
-编者按:在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统从
Airflow 迁移到 Apache DolphinScheduler 的方案设计思考和生产环境实践。
-
-这位来自浙江杭州的 90 后年轻人自 2019 年 9 月加入有赞,在这里从事数据开发平台、调度系统和数据同步组件的研发工作。刚入职时,有赞使用的还是同为
Apache 开源项目的 Airflow,但经过调研和生产环境测试,有赞决定切换到 DolphinScheduler。
-
-有赞大数据开发平台如何利用调度系统?为什么决定重新选型为 Apache DolphinScheduler ?让我们跟着他的分享来一探究竟。
-
-## 有赞大数据开发平台(DP平台)
-
-作为一家零售科技 SaaS
服务商,有赞的使命是助力线上商家开店,通过社交营销和拓展全渠道零售业务,搭建数据产品和数字化解决方案,为驱动商家数字增长提供更好的 SaaS 能力。
-
-目前,有赞在数据中台的支撑下已经建立了比较完整的数字产品矩阵:
-
-[](https://imgpp.com/image/ZbGED)
-
-为了支持日益增长的数据处理业务需求,有赞建立了大数据开发平台(以下简称 DP
平台)。这是一个大数据离线开发平台,提供用户大数据任务开发所需的环境、工具和数据。
-
-[](https://imgpp.com/image/ZbZbN)
-
-有赞大数据开发平台架构
-
-有赞大数据开发平台主要由基础组件层、任务组件层、调度层、服务层和监控层五个模块组成。其中,服务层主要负责作业的生命周期管理,基础组件层和任务组件层主要包括大数据开发平台依赖的中间件及大数据组件等基础环境。DP
平台的服务部署主要采用主从模式,Master 节点支持 HA。调度层是在 Airflow 的基础上进行二次开发,监控层对调度集群进行全方位监控和预警。
-
-### 1 调度层架构设计
-
-
-[](https://imgpp.com/image/ZbiQL)
-
-有赞大数据开发平台调度层架构设计
-
-2017 年,我们团队在17年的时候调研了当时的主流的调度系统,最终决定采用 Airflow(1.7)作为 DP
的任务调度模块。根据业务场景实际需求,架构设计方面,我们采用了Airflow + Celery + Redis + MySQL的部署方案,Redis
作为调度队列,通过 Celery 实现任意多台 worker 分布式部署。
-
-在调度节点 HA 设计上,众所周知,Airflow 在 schedule 节点上存在单点问题,为了实现调度的高可用,DP 平台采用了 Airflow
Scheduler Failover Controller 这个开源组件,新增了一个 Standby 节点,会周期性地监听 Active
节点的健康情况,一旦发现 Active 节点不可用,则 Standby 切换为 Active,从而保证 schedule 的高可用。
-
-### 2 Worker节点负载均衡策略
-
-另外,由于不同任务占据资源不同,为了更有效地利用资源,DP 平台按照 CPU 密集/内存密集区分任务类型,并安排在不同的 celery 队列配置不同的
slot,保证每台机器 CPU/ 内存使用率保持在合理范围内。
-
-
-## 调度系统升级选型
-
-
-自 2017 年有赞大数据平台 1.0 版本正式上线以来,我们已经在 2018 年 100% 完成了数据仓库迁移的计划,2019 年日调度任务量达
30000+,到 2021 年,平台的日调度任务量已达到 60000+。伴随着任务量的剧增,DP 的调度系统也面临了许多挑战与问题。
-
-### 1 Airflow 的痛点
-
-1. 深度二次开发,脱离社区版本,升级成本高;
-2. Python 技术栈,维护迭代成本高;
-3. 性能问题:
-
-[](https://imgpp.com/image/Zb8yu)
-
-Airflow 的 schedule loop 如上图所示,本质上是对 DAG 的加载解析,将其生成 DAG round 实例执行任务调度。Airflow
2.0 之前的版本是单点 DAG 扫描解析到数据库,这就导致业务增长 Dag 数量较多时,scheduler loop 扫一次 Dag folder
会存在较大延迟(超过扫描频率),甚至扫描时间需要 60-70 秒,严重影响调度性能。
-
-4. 稳定性问题:
-
-Airflow Scheduler Failover Controller 本质还是一个主从模式,standby 节点通过监听
active进程是否存活来判断是否切换,如之前遇到 deadlock
阻塞进程的情况,则会被忽略,进而导致调度故障发生。在生产环境中发生过类似问题后,我们经过排查后发现了问题所在,虽然 Airflow 1.10
版本已经修复了这个问题,但在主从模式下,这个在生产环境下不可忽视的问题依然会存在。
-
-考虑到以上几个痛点问题,我们决定对 DP 平台的调度系统进行重新选型。
-
-在调研对比过程中,Apache DolphinScheduler 进入了我们的视野。同样作为 Apache
顶级开源调度组件项目,我们性能、部署、功能、稳定性和可用性、社区生态等角度对原调度系统和 DolphinScheduler 进行了综合对比。
-
-以下为对比分析结果:
-
-[](https://imgpp.com/image/ZbaBs)
-
-Airflow VS DolphinScheduler
-
-
-### 1 DolphinScheduler 价值评估
-
-[](https://imgpp.com/image/ZbVrt)
-
-如上图所示,经过对 DolphinScheduler 价值评估,我们发现其在相同的条件下,吞吐性能是原来的调度系统的 2 倍,而 2.0 版本后
DolphinScheduler 的性能还会有更大幅度的提升,这一点让我们非常兴奋。
-
-此外,在部署层面,DolphinScheduler 采用的 Java
技术栈有利于ops标准化部署流程,简化发布流程、解放运维人力,且支持Kubernetes、Docker 部署,扩展性更强。
-
-在功能新增上,因为我们在使用过程中比较注重任务依赖配置,而 DolphinScheduler
有更灵活的任务依赖配置,时间配置粒度细化到了时、天、周、月,使用体验更好。另外,DolphinScheduler 的调度管理界面易用性更好,同时支持
worker group 隔离。作为一个分布式调度,DolphinScheduler
整体调度能力随集群规模线性增长,而且随着新特性任务插件化的发布,可自定义任务类型这一点也非常吸引人。
-
-从稳定性与可用性上来说,DolphinScheduler 实现了高可靠与高可扩展性,去中心化的多 Master 多 Worker
设计架构,支持服务动态上下线,自我容错与调节能力更强。
-
-另外一个重要的点是,经过数月的接触,我们发现 DolphinScheduler 社区整体活跃度较高,经常会有技术交流,技术文档比较详细,版本迭代速度也较快。
-
-综上所述,我们决定转向 DolphinScheduler。
-
-
-## DolphinScheduler 接入方案设计
-
-
-决定接入 DolphinScheduler 之后,我们梳理了平台对于新调度系统的改造需求。
-
-总结起来,最重要的是要满足以下几点:
-
-1. 用户使用无感知,平台目前的用户数有 700-800,使用密度大,希望可以降低用户切换成本;
-2. 调度系统可动态切换,生产环境要求稳定性大于一切,上线期间采用线上灰度的形式,希望基于工作流粒度,实现调度系统动态切换;
-3. 测试与发布的工作流配置需隔离,目前任务测试和发布有两套配置文件通过
GitHub维护,线上调度任务配置需要保证数据整个确性和稳定性,需要两套环境进行隔离。
-
-针对以上三点,我们对架构进行了重新设计。
-
-### 1 架构设计
-
-1. 保留现有前端界面与DP API;
-2. 重构调度管理界面,原来是嵌入 Airflow 界面,后续将基于 DolphinScheduler 进行调度管理界面重构;
-3. 任务生命周期管理/调度管理等操作通过 DolphinScheduler API 交互;
-利用 Project 机制冗余工作流配置,实现测试、发布的配置隔离。
-
-[](https://imgpp.com/image/Zbsda)
-
-改造方案设计
-
-架构设计完成之后,进入改造阶段。我们对 DolphinScheduler 的工作流定义、任务执行流程、工作流发布流程都进行了改造,并进行了一些关键功能补齐。
-
-- 工作流定义状态梳理
-
-
-[](https://imgpp.com/image/Zbvzd)
-
-我们首先梳理了 DolphinScheduler 工作流的定义状态。因为 DolphinScheduler 工作的定义和定时管理会区分为上下线状态, 但
DP平台上两者的状态是统一的,因此在任务测试和工作流发布流程中,需要对 DP到DolphinScheduler 的流程串联做相应的改造。
-
-- 任务执行流程改造
-
-首先是任务测试流程改造。在切换到 DolphinScheduler 之后,所有的交互都是基于DolphinScheduler API 来进行的,当在 DP
启动任务测试时,会在 DolphinScheduler 侧生成对应的工作流定义配置,上线之后运行任务,同时调用 DolphinScheduler
的日志查看结果,实时获取日志运行信息。
-
-[](https://imgpp.com/image/Zb6Q0)
-
-- 工作流发布流程改造
-
-其次,针对工作流上线流程,切换到 DolphinScheduler 之后,主要是对工作流定义配置和定时配置,以及上线状态进行了同步。
-
-[](https://imgpp.com/image/Zbx2b)
-
-通过这两个核心流程的改造。工作流的原数据维护和配置同步其实都是基于 DP master来管理,只有在上线和任务运行时才会到调度系统进行交互,基于这点,DP
平台实现了工作流维度下的系统动态切换,以便于后续的线上灰度测试。
-
-### 2 功能补全
-
-此外,DP 平台还进行了一些功能补齐。首先是任务类型的适配。
-
-- 任务类型适配
-
-目前,DolphinScheduler 平台已支持的任务类型主要包含数据同步类和数据计算类任务,如Hive SQL 任务、DataX 任务、Spark
任务等。因为任务的原数据信息是在 DP 侧维护的,因此 DP 平台的对接方案是在 DP 的 master 构建任务配置映射模块,将 DP 维护的 task
信息映射到 DP 侧的 task,然后通过 DolphinScheduler 的 API 调用来实现任务配置信息传递。
-
-[](https://imgpp.com/image/Z8fNH)
-
-因为 DolphinScheduler 已经支持部分任务类型 ,所以只需要基于 DP 平台目前的实际使用场景对 DolphinScheduler
相应任务模块进行定制化改造。而对于 DolphinScheduler 未支持的任务类型,如Kylin任务、算法训练任务、DataY任务等,DP
平台也计划后续通过 DolphinScheduler 2.0 的插件化能力来补齐。
-
-### 3 改造进度
-
-因为 DP 平台上 SQL 任务和同步任务占据了任务总量的 80% 左右,因此改造重点都集中在这几个任务类型上,目前已基本完成 Hive SQL
任务、DataX 任务以及脚本任务的适配改造以及迁移工作。
-
-[](https://imgpp.com/image/Z8dgm)
-
-
-### 4 功能补齐
-
-- Catchup 机制实现调度自动回补
-
-DP 在实际生产环境中还需要一个核心能力,即基于 Catchup 的自动回补和全局补数能力。
-
-Catchup 机制在 DP 的使用场景,是在调度系统异常或资源不足,导致部分任务错过当前调度出发时间,当恢复调度后,会通过Catchup
自动补齐未被触发的调度执行计划。
-
-以下三张图是一个小时级的工作流调度执行的信息实例。
-
-在图 1 中,工作流在 6 点准时调起,每小时调一次,可以看到在 6 点任务准时调起并完成任务执行,当前状态也是正常调度状态。
-
-[](https://imgpp.com/image/Z8IkI)
- 图1
-
-图 2 显示在 6 点完成调度后,一直到 8 点期间,调度系统出现异常,导致 7 点和 8点该工作流未被调起。
-
-[](https://imgpp.com/image/Z8X64)
- 图2
-
-图 3 表示当 9 点恢复调度之后,因为 具有 Catchup 机制,调度系统会自动回补之前丢失的执行计划,实现调度的自动回补。
-
-[](https://imgpp.com/image/Z8tq8)
-图3
-
-此机制在任务量较大时作用尤为显著,当 Schedule
节点异常或核心任务堆积导致工作流错过调度出发时间时,因为系统本身的容错机制可以支持自动回补调度任务,所以无需人工手动补数重跑。
-
-同时,这个机制还应用在了 DP 的全局补数能力中。
-
-- 跨 Dag 全局补数
-
-[](https://imgpp.com/image/Z8BtU)
-DP 平台跨 Dag 全局补数流程
-
-全局补数在有赞的主要使用场景,是用在核心上游表产出中出现异常,导致下游商家展示数据异常时。这种情况下,一般都需要系统能够快速重跑整个数据链路下的所有任务实例。
-
-DP 平台目前是基于 Clear
的功能,通过原数据的血缘解析获取到指定节点和当前调度周期下的所有下游实例,再通过规则剪枝策略过滤部分无需重跑的实例。获取到这些实际列表之后,启动 clear
down stream 的清除任务实例功能,再利用 Catchup 进行自动回补。
-
-这个流程实际上是通过 Clear 实现上游核心的全局重跑,自动补数的优势就在于可以解放人工操作。
-
-因为跨 Dag 全局补数能力在生产环境中是一个重要的能力,我们计划在 DolphinScheduler 中进行补齐。
-
-## 现状&规划&展望
-
-
-### 1 DolphinScheduler 接入现状
-
-DP 平台目前已经在测试环境中部署了部分 DolphinScheduler 服务,并迁移了部分工作流。
-
-对接到 DolphinScheduler API 系统后,DP 平台在用户层面统一使用 admin 用户,因为其用户体系是直接在 DP master
上进行维护,所有的工作流信息会区分测试环境和正式环境。
-
-[](https://imgpp.com/image/Zb7rA)
-DolphinScheduler 工作流定义列表
-
-[](https://imgpp.com/image/ZbQlk)
-
-[](https://imgpp.com/image/ZbodC)
-DolphinScheduler 2.0工作流任务节点展示
-
-DolphinScheduler 2.0 整体的 UI 交互看起来更加简洁,可视化程度更高,我们计划直接升级至 2.0 版本。
-
-### 2 接入规划
-
-目前 ,DP 平台还处于接入 DolphinScheduler 的灰度测试阶段,计划于今年 12
月进行工作流的全量迁移,同时会在测试环境进行分阶段全方位测试或调度性能测试和压力测试。确定没有任何问题后,我们会在来年 1 月进行生产环境灰度测试,并计划在
3 月完成全量迁移。
-
-[](https://imgpp.com/image/Zb0z6)
-
-
-### 3 对 DolphinScheduler 的期待
-
-
-未来,我们对 DolphinScheduler 最大的期待是希望 2.0 版本可以实现任务插件化。
-
-[](https://imgpp.com/image/Z8Oae)
-
-目前,DP 平台已经基于 DolphinScheduler 2.0实现了告警组件插件化,可在后端定义表单信息,并在前端自适应展示。
-
-“ 希望 DolphinScheduler 插件化的脚步可以更快一些,以更好地快速适配我们的定制化任务类型。
-——有赞大数据开发平台负责人 宋哲琦”
-
-
-
-
-
-
-
diff --git a/img/ourusers/[email protected] b/img/ourusers/[email protected]
index 79c531c1a..4d95c9955 100644
Binary files a/img/ourusers/[email protected] and b/img/ourusers/[email protected]
differ
diff --git a/img/ourusers/[email protected] b/img/ourusers/[email protected]
index 4c2f227cf..a20a4f2e9 100644
Binary files a/img/ourusers/[email protected] and b/img/ourusers/[email protected] differ
diff --git a/img/ourusers/[email protected] b/img/ourusers/[email protected]
index 9fc42cec7..b0cbee32b 100644
Binary files a/img/ourusers/[email protected] and b/img/ourusers/[email protected]
differ
diff --git a/img/ourusers/[email protected] b/img/ourusers/[email protected]
index 32698a2f8..e3290d39c 100644
Binary files a/img/ourusers/[email protected] and b/img/ourusers/[email protected]
differ
diff --git a/img/ourusers/[email protected] b/img/ourusers/[email protected]
index d0f68d930..8113b199f 100644
Binary files a/img/ourusers/[email protected] and
b/img/ourusers/[email protected] differ
diff --git a/site_config/blog.js b/site_config/blog.js
index 8d5abcd79..51a05d5eb 100644
--- a/site_config/blog.js
+++ b/site_config/blog.js
@@ -4,7 +4,14 @@ export default {
postsTitle: 'All posts',
list: [
{
- title: 'Three scenarios and five optimizations of Apache
DolphinScheduler in XWBank for processing of task instances\n',
+ title: 'pache DolphinScheduler Extends Capabilities Through
Python API and AWS Support',
+ author: 'Debra Chen',
+ dateStr: '2022-8-26',
+ desc: 'In the ever-changing world of technology, data is
abundant. ... ',
+ link: '/en-us/blog/Python_API_and_AWS_Support.html',
+ },
+ {
+ title: 'Three scenarios and five optimizations of Apache
DolphinScheduler in XWBank for processing of task instances',
author: 'Debra Chen',
dateStr: '2022-5-25',
desc: 'At XWBank, a large number of task instances are
generated every day... ',
@@ -404,13 +411,6 @@ export default {
desc: 'Apache DolphinScheduler 2.0.1',
link: '/zh-cn/blog/Apache-DolphinScheduler-2.0.1.html',
},
- {
- title: '从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进',
- author: 'Debra Chen',
- dateStr: '2021-12-10',
- desc: 'YouZan case study',
- link: '/zh-cn/blog/YouZan-case-study.html',
- },
{
title: '荔枝机器学习平台与大数据调度系统“双剑合璧”,打造未来数据处理新模式!',
author: 'Debra Chen',
diff --git a/site_config/home.jsx b/site_config/home.jsx
index 2e34ca7f4..79945c250 100644
--- a/site_config/home.jsx
+++ b/site_config/home.jsx
@@ -558,6 +558,13 @@ export default {
events: {
title: 'Events & News',
list: [
+ {
+ img: 'https://miro.medium.com/max/630/0*Ep9rZFSTviU8SjmP',
+ title: 'Apache DolphinScheduler Extends Capabilities Through Python
API and AWS Support',
+ content: 'In the ever-changing world of technology, data is
abundant. In fact,....',
+ dateStr: '2022-8-26',
+ link: '/en-us/blog/Python_API_and_AWS_Support.html',
+ },
{
img: '/img/2022-05-25/en/1.jpg',
title: 'Three scenarios and five optimizations of Apache
DolphinScheduler in XWBank for processing of task instances',
@@ -572,13 +579,7 @@ export default {
dateStr: '2022-3-10',
link: '/en-us/blog/Apache_dolphinScheduler_3.0.0_alpha.html',
},
- {
- img: '/img/2022-03-29/En/1.png',
- title: 'Fast Task Type Expanding On Apache DolphinScheduler |
Tutorial',
- content: 'At present, the scheduler plays an indispensable role in
big data ecology....',
- dateStr: '2022-4-14',
- link:
'/en-us/blog/Fast_Task_Type_Expanding_On_Apache_DolphinScheduler_Tutorial.html',
- },
+
],
},
userreview: {
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}