duspring opened a new issue, #13282: URL: https://github.com/apache/dolphinscheduler/issues/13282
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/dolphinscheduler/issues?q=is%3Aissue) and found no similar feature requirement. ### Description When the data volume reaches more than 30 million, the task execution is slow and the following error will be reported: 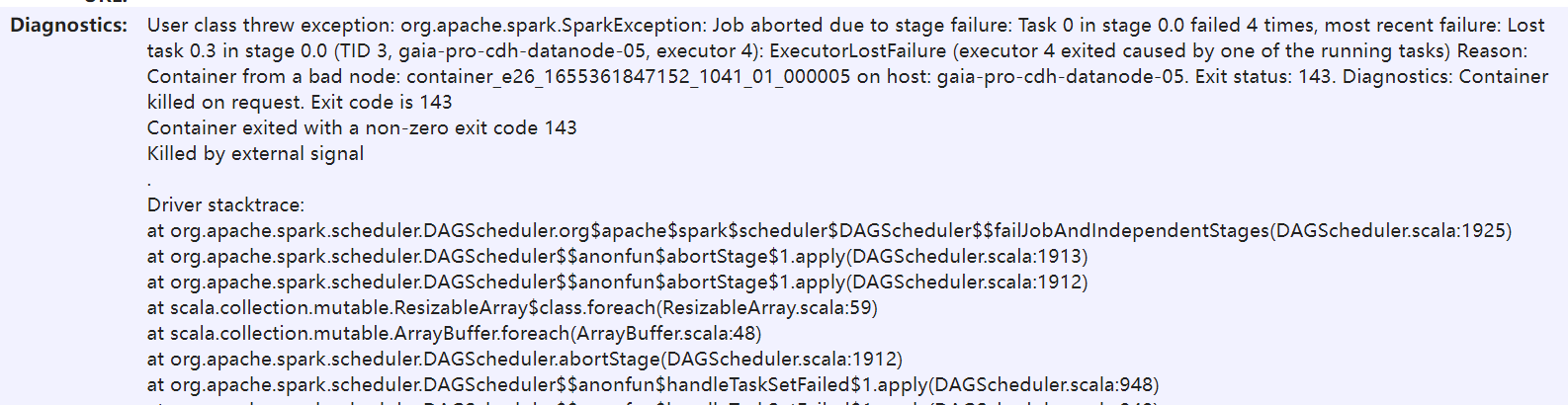 After checking the data quality execution process, it is found that the code does not filter the data in the read phase, but loads all the data into memory, which will result in the inability to run even adjust the Spark tuning parameters when the data volume is huge (billions or billions) 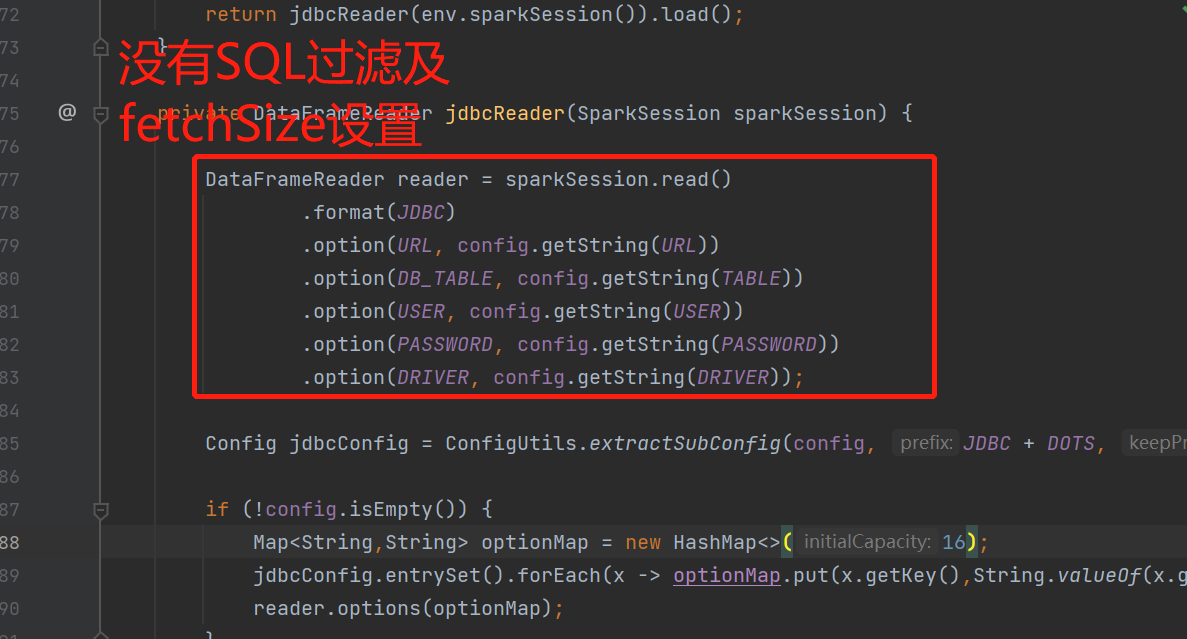 ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}