This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new d368a775b5d update two blogs (#264)
d368a775b5d is described below
commit d368a775b5d8c4f701e282e23bcfc77db6ca238a
Author: Hu Yanjun <[email protected]>
AuthorDate: Mon Jul 17 16:01:27 2023 +0800
update two blogs (#264)
---
blog/Moka.md | 14 +++++++-------
blog/Tianyancha.md | 22 +++++++++++-----------
static/images/Moka_1.png | Bin 0 -> 163117 bytes
static/images/Moka_2.png | Bin 0 -> 101298 bytes
static/images/Moka_3.png | Bin 0 -> 125885 bytes
static/images/Moka_4.png | Bin 0 -> 71536 bytes
static/images/Moka_5.png | Bin 0 -> 34206 bytes
static/images/Moka_6.png | Bin 0 -> 107745 bytes
static/images/Tianyancha_1.png | Bin 0 -> 175688 bytes
static/images/Tianyancha_10.png | Bin 0 -> 282789 bytes
static/images/Tianyancha_11.png | Bin 0 -> 70497 bytes
static/images/Tianyancha_2.png | Bin 0 -> 126302 bytes
static/images/Tianyancha_3.png | Bin 0 -> 154959 bytes
static/images/Tianyancha_4.png | Bin 0 -> 178209 bytes
static/images/Tianyancha_5.png | Bin 0 -> 199652 bytes
static/images/Tianyancha_6.png | Bin 0 -> 24594 bytes
static/images/Tianyancha_7.png | Bin 0 -> 78898 bytes
static/images/Tianyancha_8.png | Bin 0 -> 261317 bytes
static/images/Tianyancha_9.png | Bin 0 -> 249248 bytes
19 files changed, 18 insertions(+), 18 deletions(-)
diff --git a/blog/Moka.md b/blog/Moka.md
index 3222a610e8e..08d82ceeea2 100644
--- a/blog/Moka.md
+++ b/blog/Moka.md
@@ -35,13 +35,13 @@ Business intelligence (BI) tool is often the last stop of a
data processing pipe
I work as an engineer that supports a human resource management system. One
prominent selling point of our services is **self-service** **BI**. That means
we allow users to customize their own dashboards: they can choose the fields
they need and relate them to form the dataset as they want.
-
+
Join query is a more efficient way to realize self-service BI. It allows
people to break down their data assets into many smaller tables instead of
putting it all in a flat table. This would make data updates much faster and
more cost-effective, because updating the whole flat table is not always the
optimal choice when you have plenty of new data flowing in and old data being
updated or deleted frequently, as is the case for most data input.
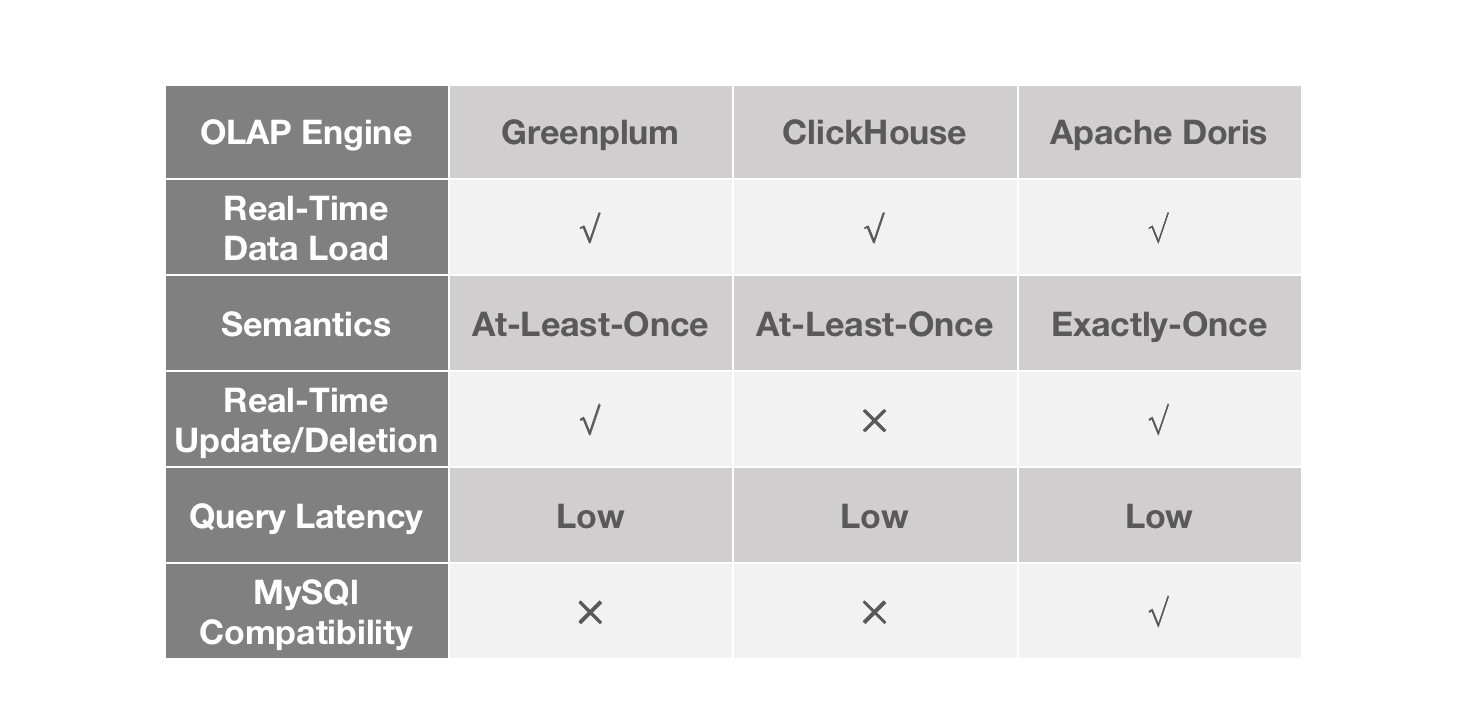
In order to maximize the time value of data, we need data updates to be
executed really quickly. For this purpose, we looked into three OLAP databases
on the market. They are all fast in some way but there are some differences.
-
+
Greenplum is really quick in data loading and batch DML processing, but it is
not good at handling high concurrency. There is a steep decline in performance
as query concurrency rises. This can be risky for a BI platform that tries to
ensure stable user experience. ClickHouse is mind-blowing in single-table
queries, but it only allows batch update and batch delete, so that's less
timely.
@@ -51,7 +51,7 @@ JOIN, my old friend JOIN, is always a hassle. Join queries
are demanding for bot
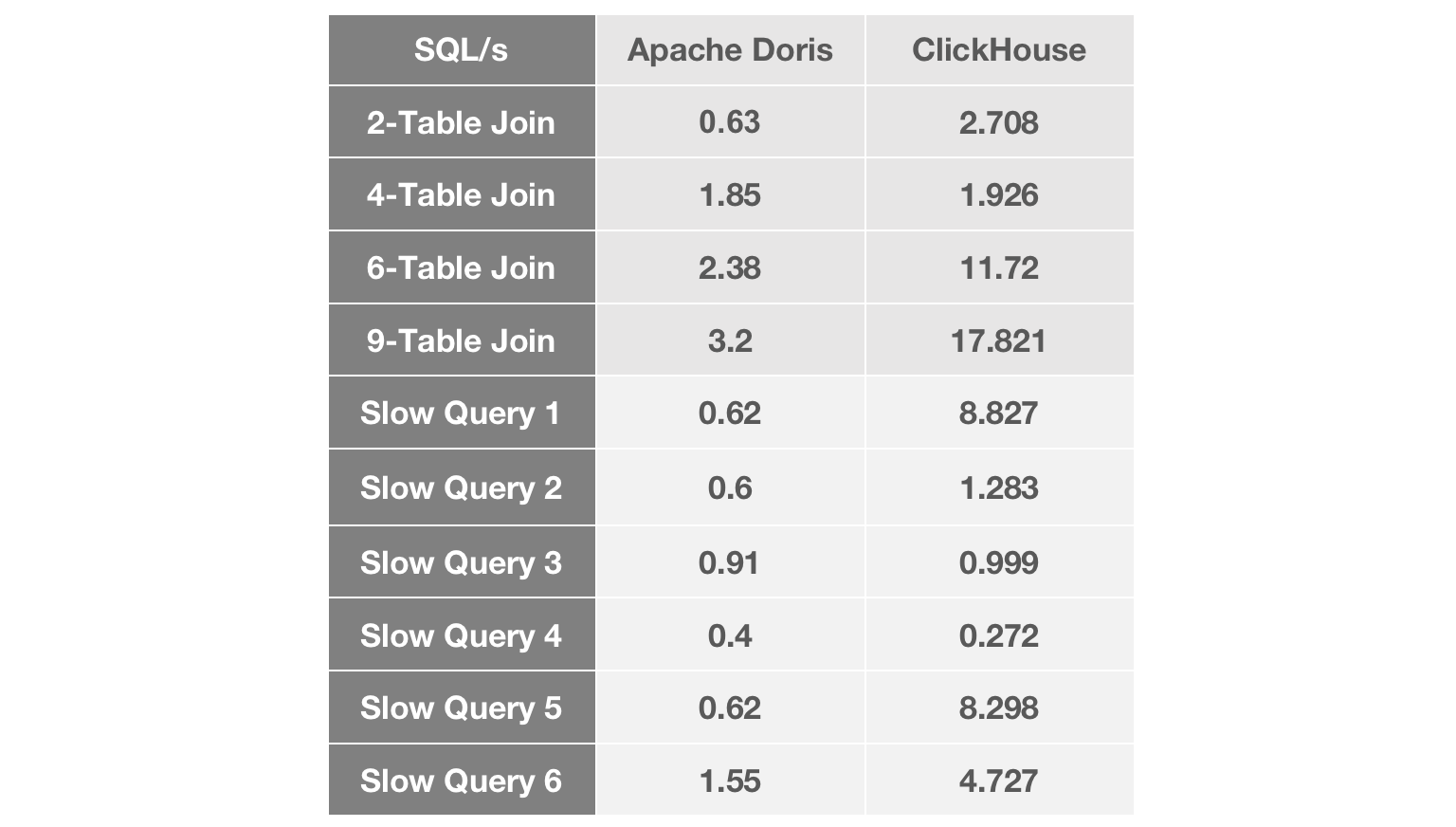
We tested our candidate OLAP engines with our common join queries and our most
notorious slow queries.
-
+
As the number of tables joined grows, we witness a widening performance gap
between Apache Doris and ClickHouse. In most join queries, Apache Doris was
about 5 times faster than ClickHouse. In terms of slow queries, Apache Doris
responded to most of them within less than 1 second, while the performance of
ClickHouse fluctuated within a relatively large range.
@@ -79,15 +79,15 @@ Human resource data is subject to very strict and
fine-grained access control po
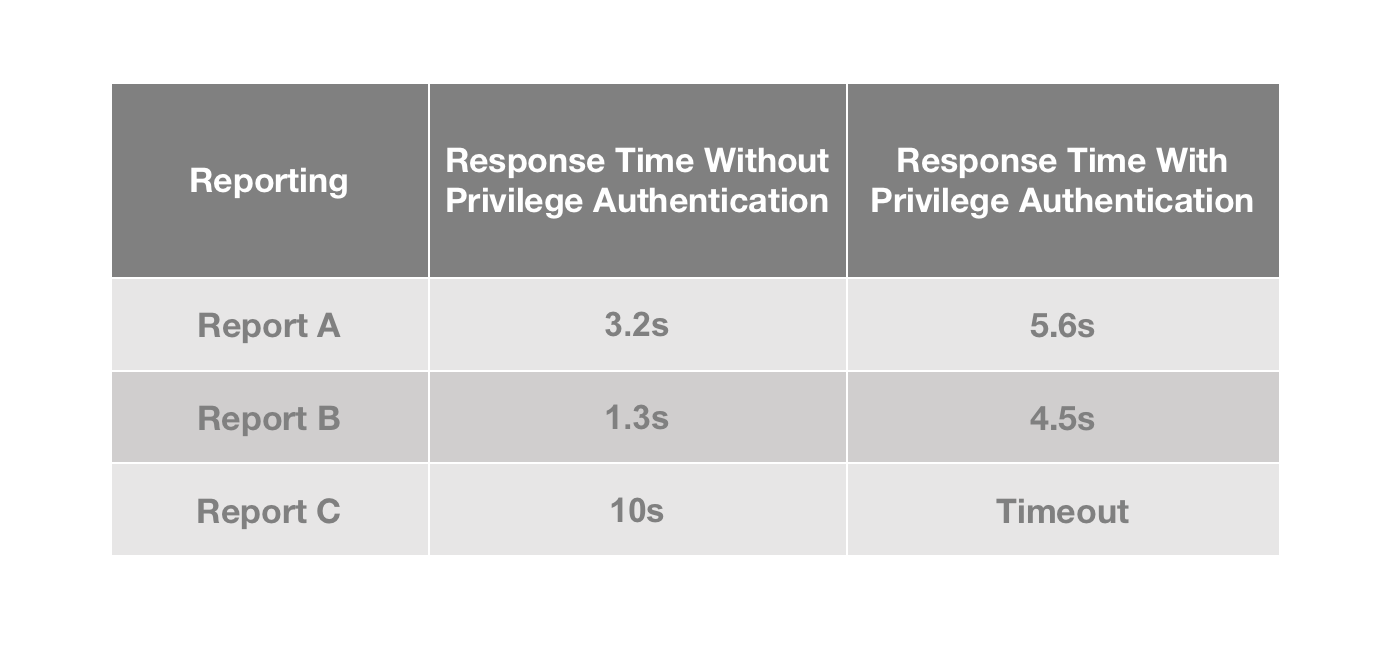
How does all this add to complexity in engineering? Any user who inputs a
query on our BI platform must go through multi-factor authentication, and the
authenticated information will all be inserted into the SQL via `in` and then
passed on to the OLAP engine. Therefore, the more fine-grained the privilege
controls are, the longer the SQL will be, and the more time the OLAP system
will spend on ID filtering. That's why our users are often tortured by high
latency.
-
+
So how did we fix that? We use the [Bloom Filter
index](https://doris.apache.org/docs/dev/data-table/index/bloomfilter/) in
Apache Doris.
-
+
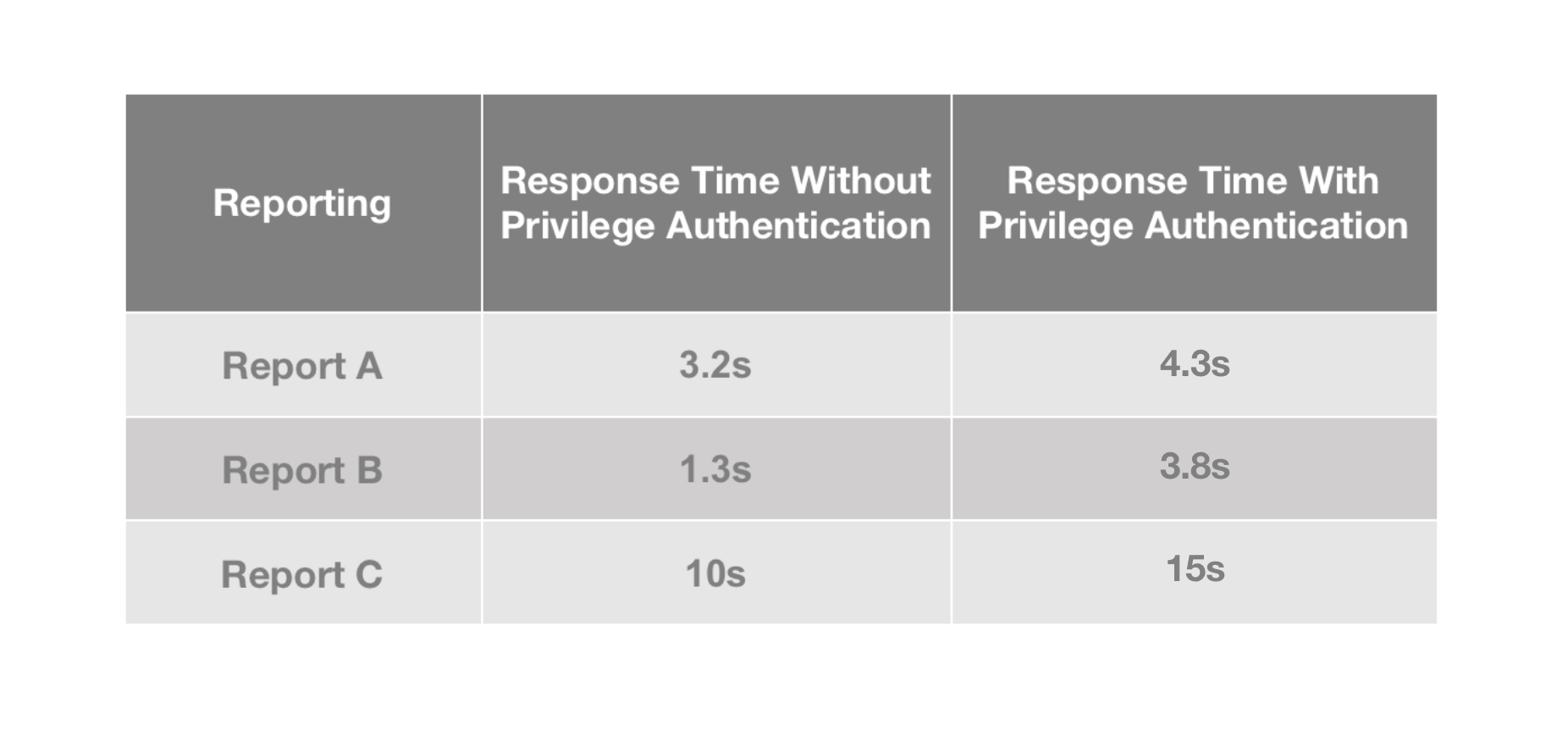
By adding Bloom Filter indexes to the relevant ID fields, we improve the speed
of privileged queries by 30% and basically eliminate timeout errors.
-
+
Tips on when you should use the Bloom Filter index:
@@ -101,4 +101,4 @@ We believe self-service BI is the future in the BI
landscape, just like AGI is t
-Find the Apache Doris developers on [Slack](https://t.co/ZxJuNJHXb2)
\ No newline at end of file
+Find the Apache Doris developers on [Slack](https://t.co/ZxJuNJHXb2)
diff --git a/blog/Tianyancha.md b/blog/Tianyancha.md
index 22e52fd08c5..e2c1678725b 100644
--- a/blog/Tianyancha.md
+++ b/blog/Tianyancha.md
@@ -37,15 +37,15 @@ Our old data warehouse consisted of the most popular
components of the time, inc
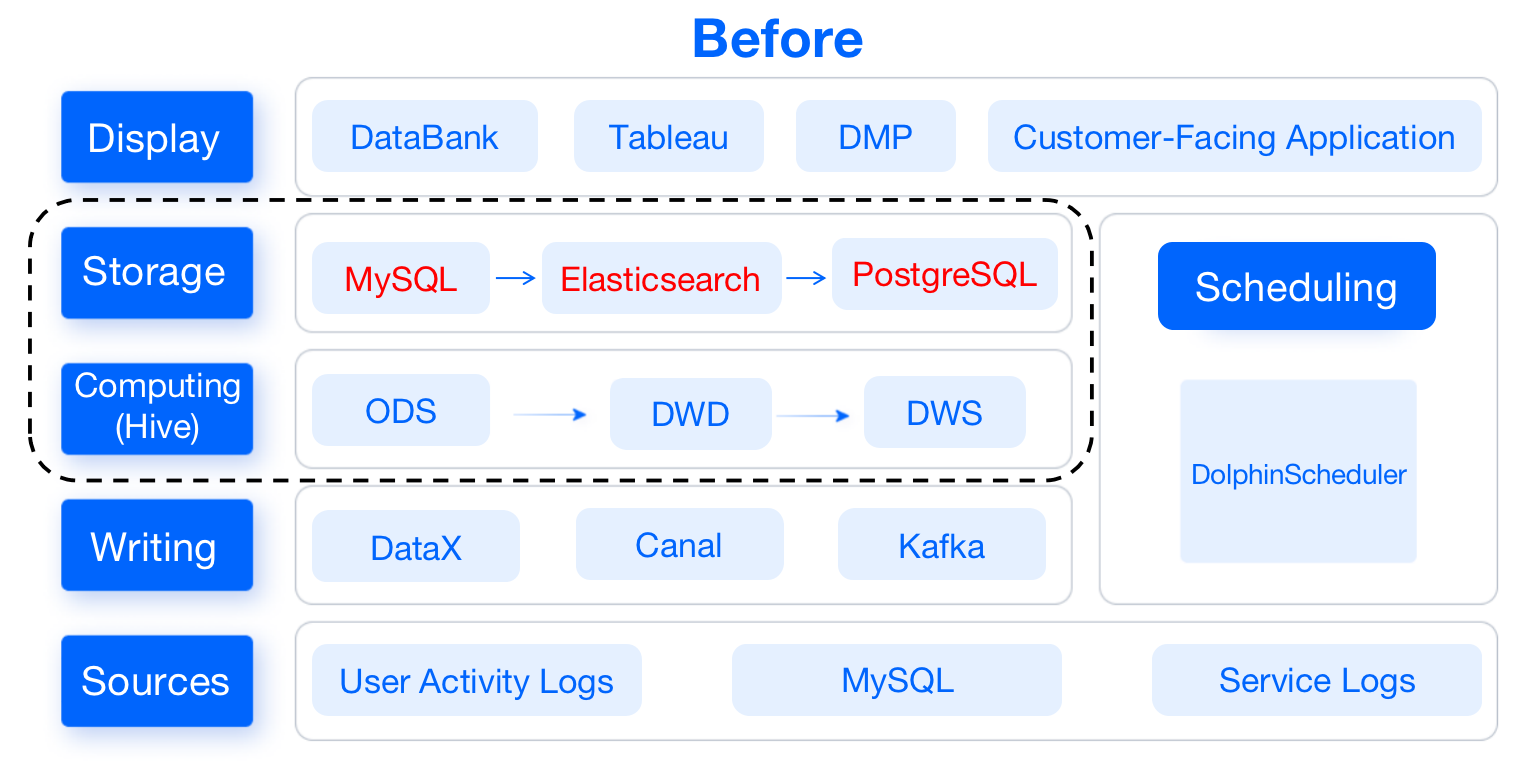
As you can imagine, a long and complicated data pipeline is high-maintenance
and detrimental to development efficiency. Moreover, they are not capable of
ad-hoc queries. So as an upgrade to our data warehouse, we replaced most of
these components with [Apache Doris](https://github.com/apache/doris), a
unified analytic database.
-
+
-
+
## Data Flow
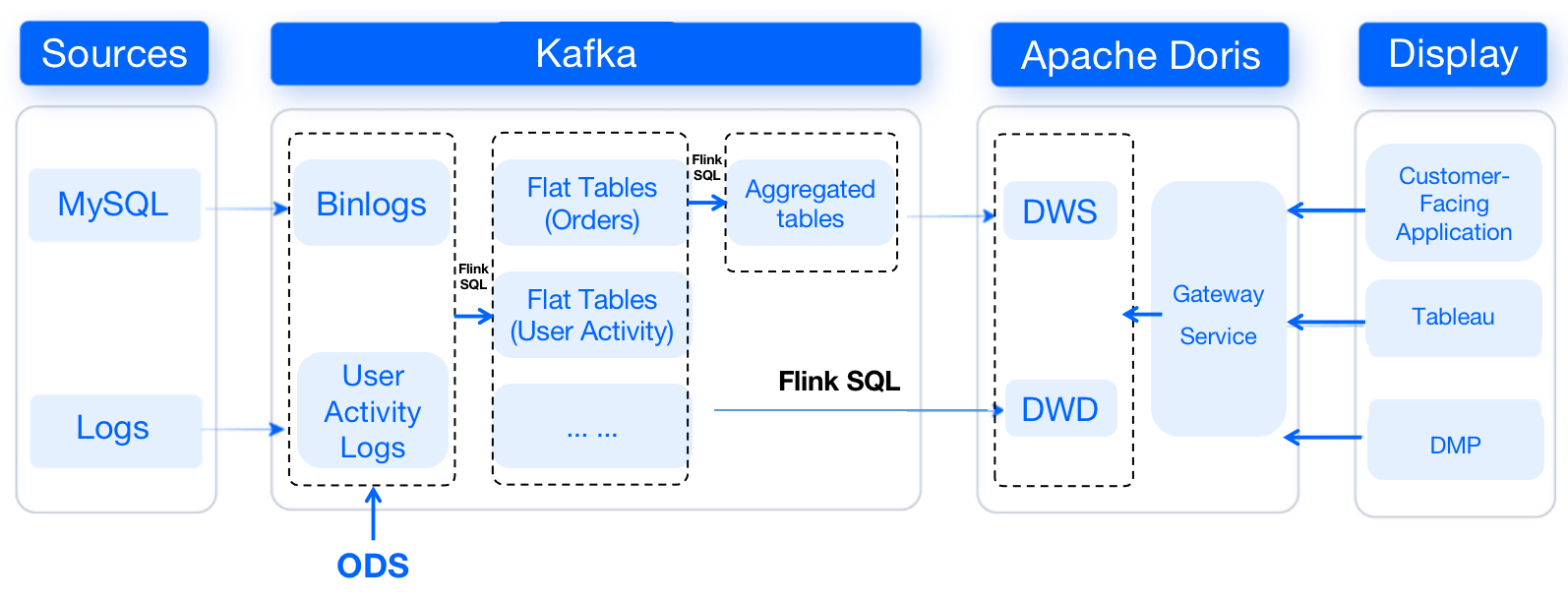
This is a lateral view of our data warehouse, from which you can see how the
data flows.
-
+
For starters, binlogs from MySQL will be ingested into Kafka via Canal, while
user activity logs will be transferred to Kafka via Apache Flume. In Kafka,
data will be cleaned and organized into flat tables, which will be later turned
into aggregated tables. Then, data will be passed from Kafka to Apache Doris,
which serves as the storage and computing engine.
@@ -59,7 +59,7 @@ This is how Apache Doris replaces the roles of Hive,
Elasticsearch, and PostgreS
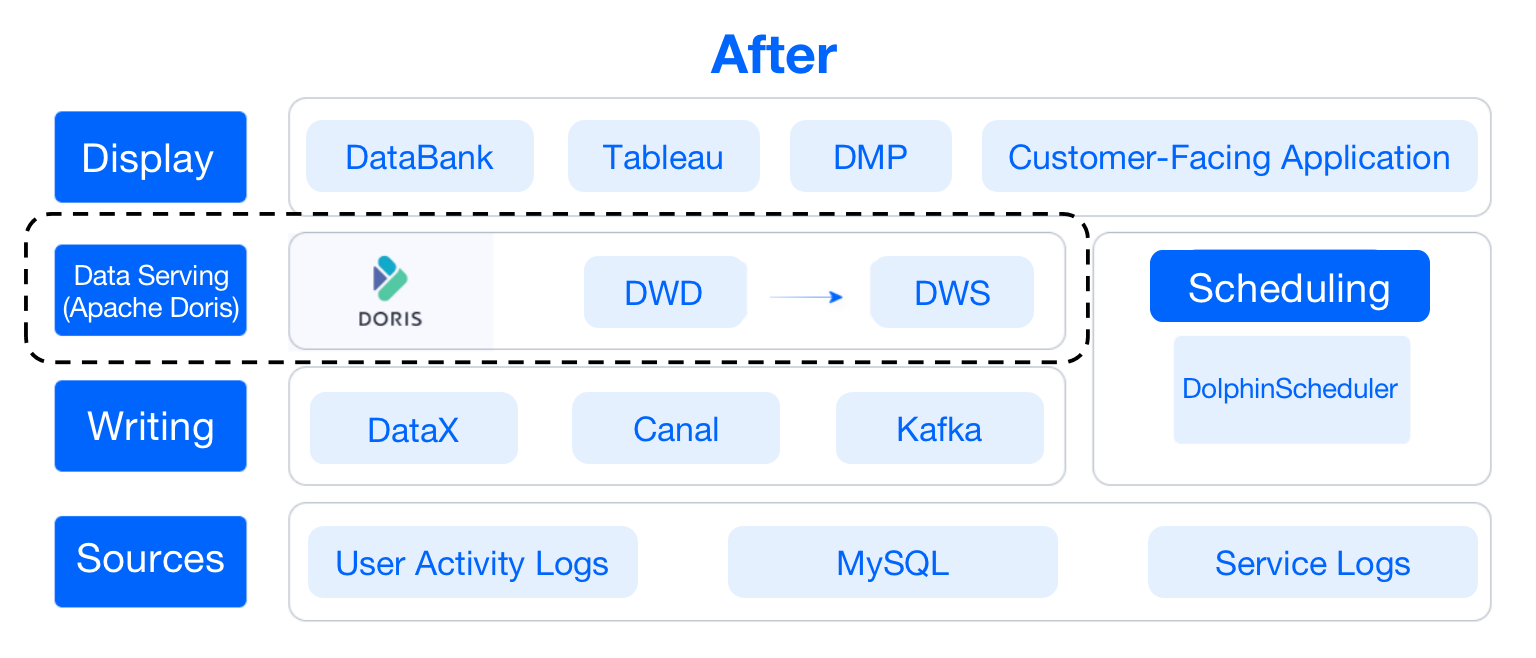
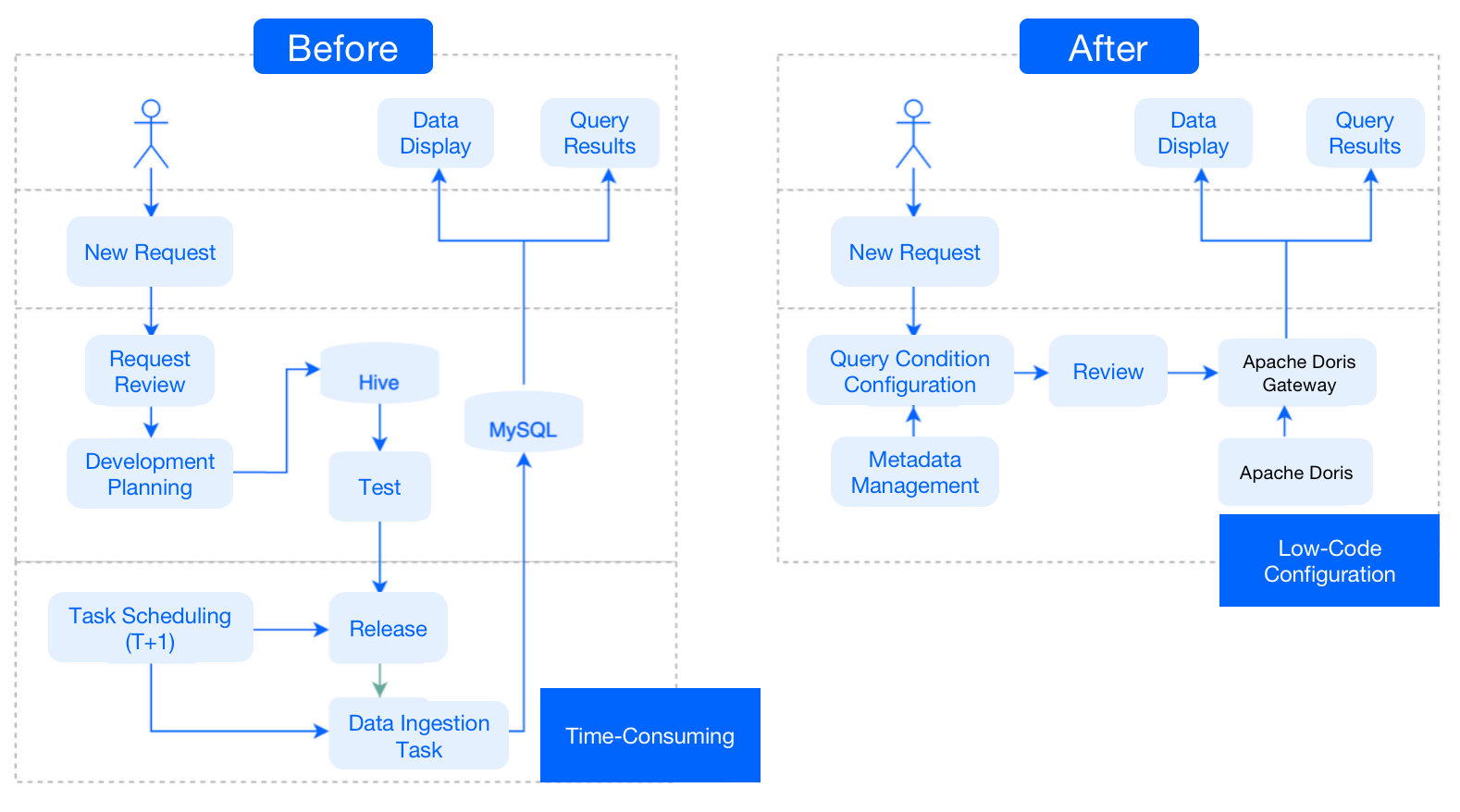
**After**: Since Apache Doris has all the itemized data, whenever it is faced
with a new request, it can simply pull the metadata and configure the query
conditions. Then it is ready for ad-hoc queries. In short, it only requires
low-code configuration to respond to new requests.
-
+
## User Segmentation
@@ -71,7 +71,7 @@ Tables in Elasticsearch and PostgreSQL were unreusable,
making this architecture
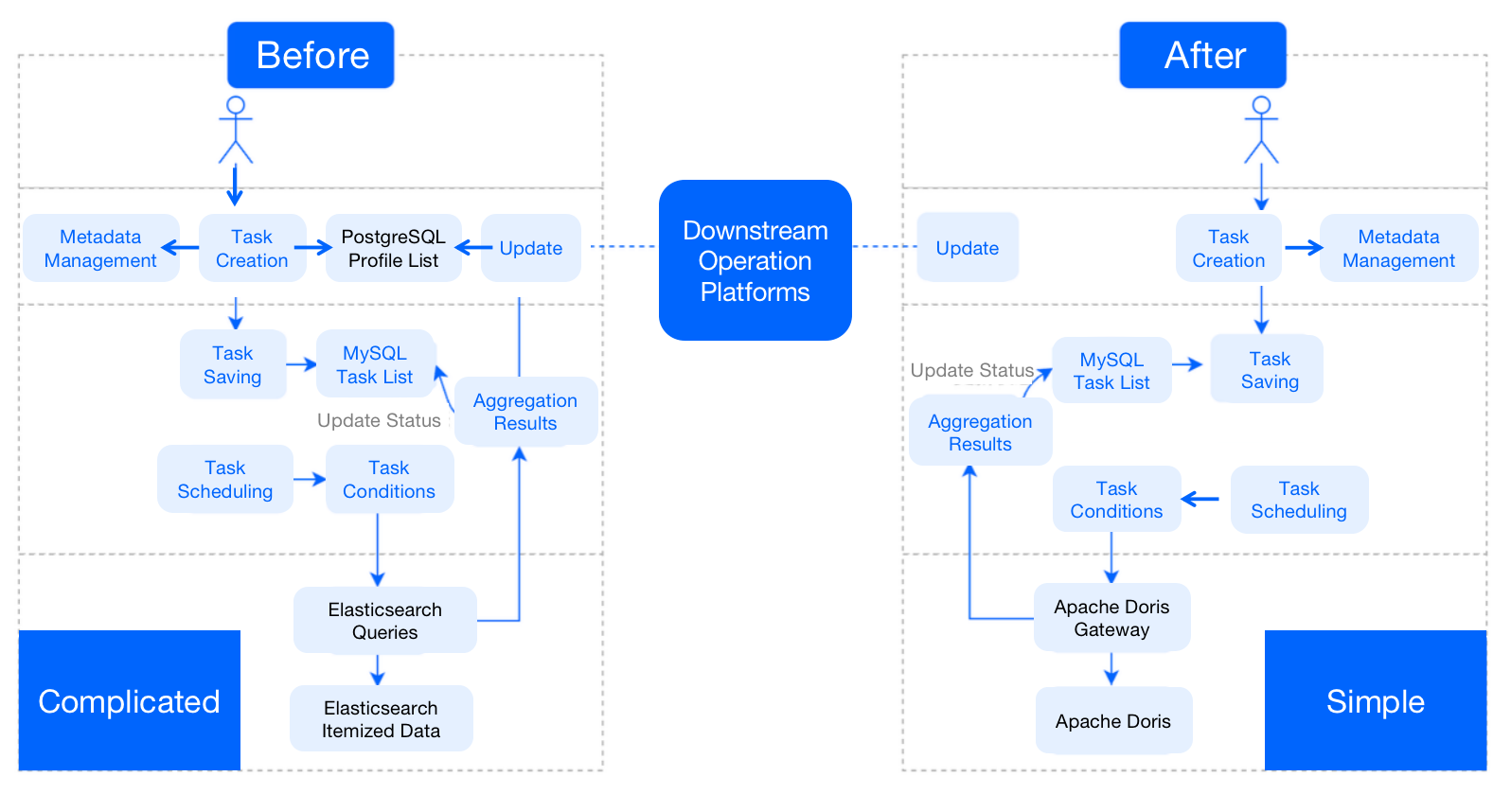
In this Doris-centered user segmentation process, we don't have to pre-define
new tags. Instead, tags can be auto-generated based on the task conditions. The
processing pipeline has the flexibility that can make our user-group-based A/B
testing easier. Also, as both the itemized data and user group packets are in
Apache Doris, we don't have to attend to the read and write complexity between
multiple components.
-
+
## Trick to Speed up User Segmentation by 70%
@@ -79,9 +79,9 @@ Due to risk aversion reasons, random generation of `user_id`
is the choice for m
To solve that, we created consecutive and dense mappings for these user IDs.
**In this way, we decreased our user segmentation latency by 70%.**
-
+
-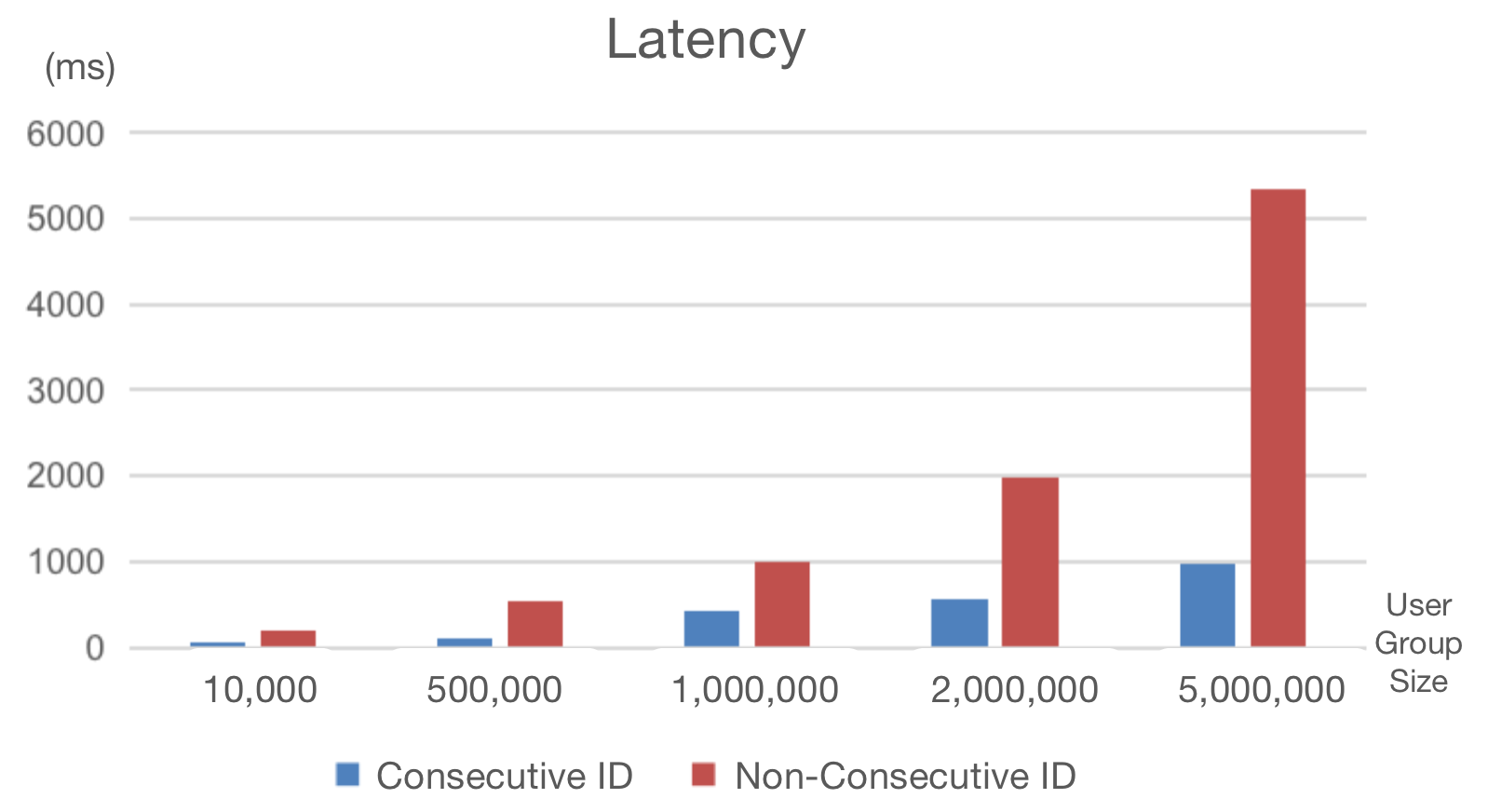
+
### Example
@@ -89,13 +89,13 @@ To solve that, we created consecutive and dense mappings
for these user IDs. **I
We adopt the Unique model for user ID mapping tables, where the user ID is the
unique key. The mapped consecutive IDs usually start from 1 and are strictly
increasing.
-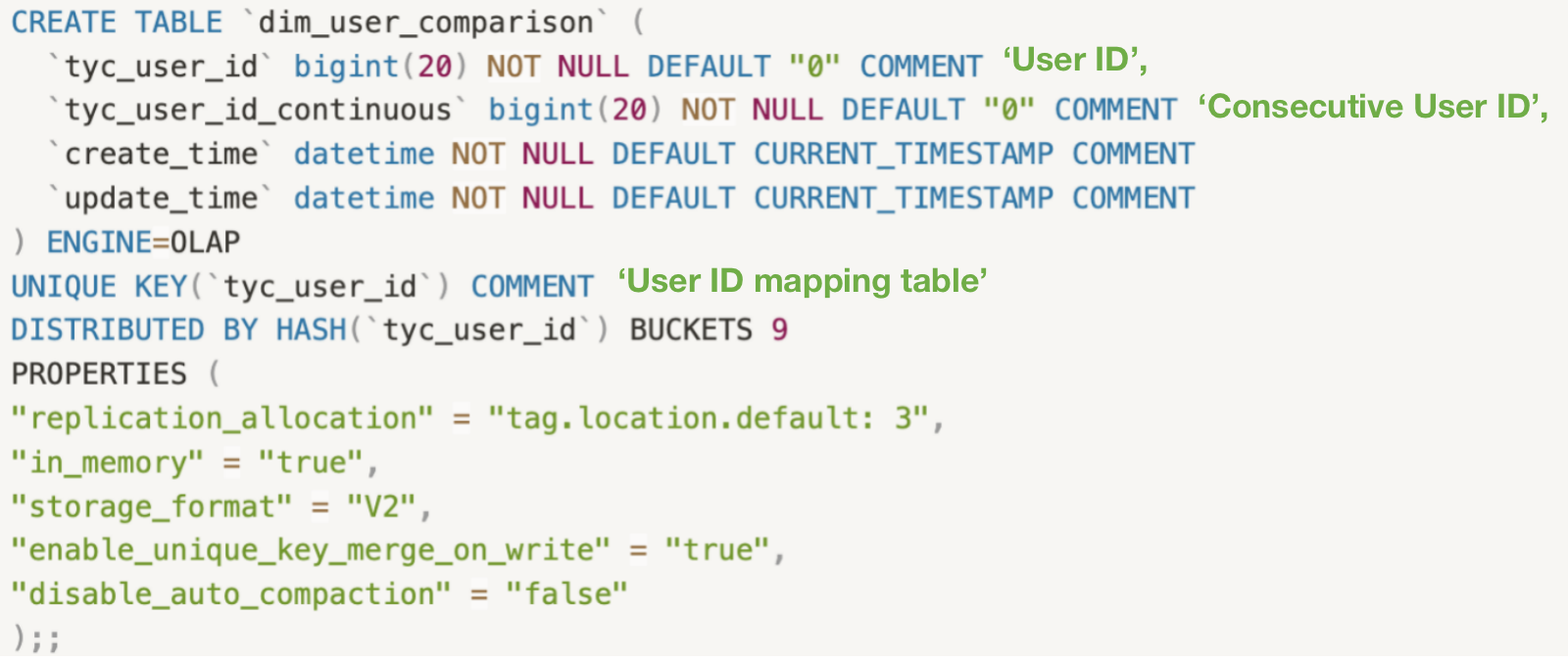
+
**Step 2: Create a user group table:**
We adopt the Aggregate model for user group tables, where user tags serve as
the aggregation keys.
-
+
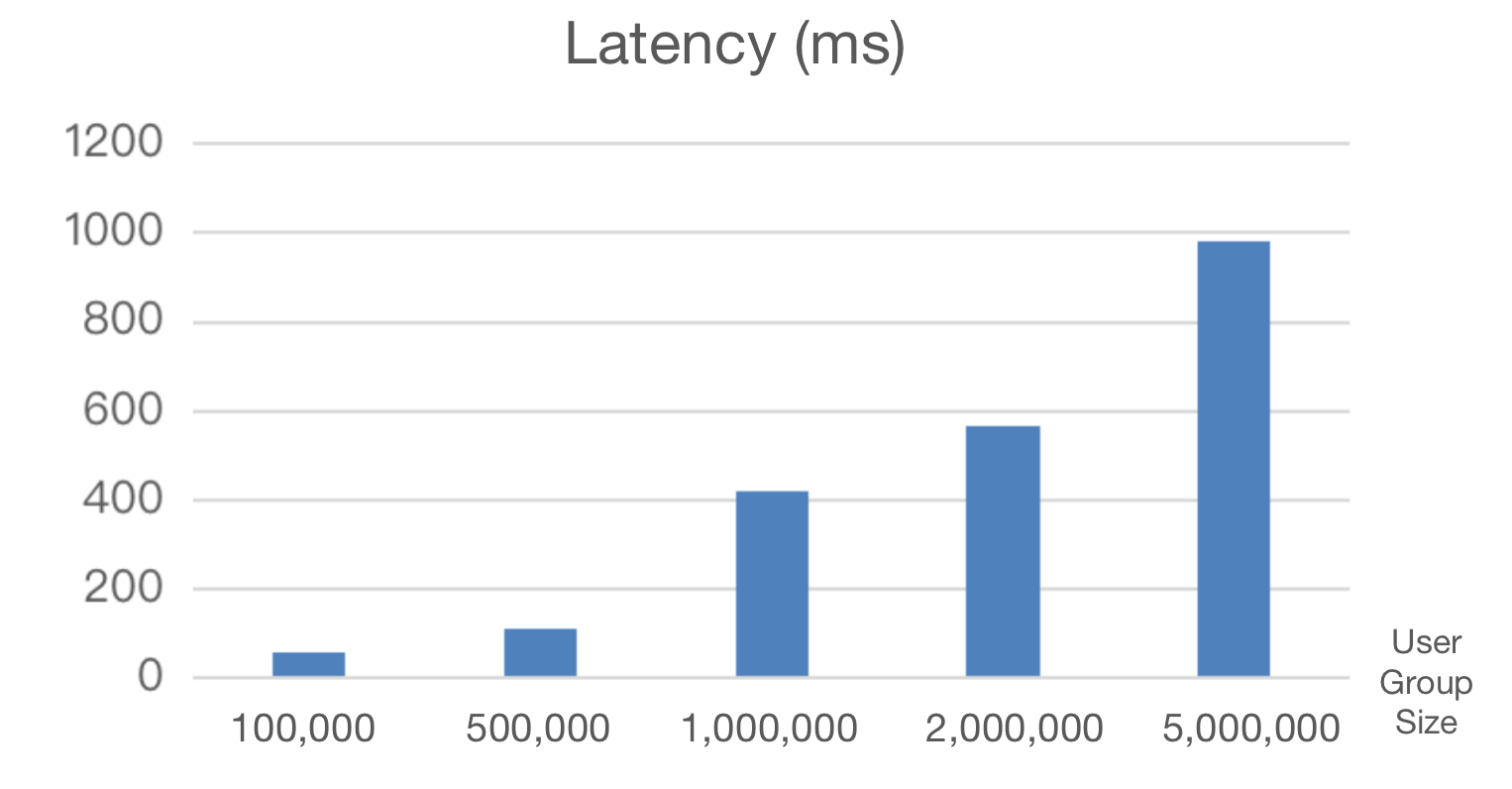
Supposing that we need to pick out the users whose IDs are between 0 and
2000000.
@@ -104,13 +104,13 @@ The following snippets use non-consecutive
(`tyc_user_id`) and consecutive (`tyc
- Non-Consecutive User IDs: **1843ms**
- Consecutive User IDs: **543ms**
-
+
## Conclusion
We have 2 clusters in Apache Doris accommodating tens of TBs of data, with
almost a billion new rows flowing in every day. We used to witness a steep
decline in data ingestion speed as data volume expanded. But after upgrading
our data warehouse with Apache Doris, we increased our data writing efficiency
by 75%. Also, in user segmentation with a result set of less than 5 million, it
is able to respond within milliseconds. Most importantly, our data warehouse
has been simpler and friendli [...]
-
+
Lastly, I would like to share with you something that interested us most when
we first talked to the [Apache Doris community](https://t.co/KcxAtAJZjZ):
diff --git a/static/images/Moka_1.png b/static/images/Moka_1.png
new file mode 100644
index 00000000000..67e086218cc
Binary files /dev/null and b/static/images/Moka_1.png differ
diff --git a/static/images/Moka_2.png b/static/images/Moka_2.png
new file mode 100644
index 00000000000..498fba4191f
Binary files /dev/null and b/static/images/Moka_2.png differ
diff --git a/static/images/Moka_3.png b/static/images/Moka_3.png
new file mode 100644
index 00000000000..02aafccbca8
Binary files /dev/null and b/static/images/Moka_3.png differ
diff --git a/static/images/Moka_4.png b/static/images/Moka_4.png
new file mode 100644
index 00000000000..1341e2a6416
Binary files /dev/null and b/static/images/Moka_4.png differ
diff --git a/static/images/Moka_5.png b/static/images/Moka_5.png
new file mode 100644
index 00000000000..0f4d0dfc8f2
Binary files /dev/null and b/static/images/Moka_5.png differ
diff --git a/static/images/Moka_6.png b/static/images/Moka_6.png
new file mode 100644
index 00000000000..9092c8e6f26
Binary files /dev/null and b/static/images/Moka_6.png differ
diff --git a/static/images/Tianyancha_1.png b/static/images/Tianyancha_1.png
new file mode 100644
index 00000000000..d21f10e51f8
Binary files /dev/null and b/static/images/Tianyancha_1.png differ
diff --git a/static/images/Tianyancha_10.png b/static/images/Tianyancha_10.png
new file mode 100644
index 00000000000..254fb17fe39
Binary files /dev/null and b/static/images/Tianyancha_10.png differ
diff --git a/static/images/Tianyancha_11.png b/static/images/Tianyancha_11.png
new file mode 100644
index 00000000000..1c6f06e0781
Binary files /dev/null and b/static/images/Tianyancha_11.png differ
diff --git a/static/images/Tianyancha_2.png b/static/images/Tianyancha_2.png
new file mode 100644
index 00000000000..ba008d1313f
Binary files /dev/null and b/static/images/Tianyancha_2.png differ
diff --git a/static/images/Tianyancha_3.png b/static/images/Tianyancha_3.png
new file mode 100644
index 00000000000..a2c9fc70f42
Binary files /dev/null and b/static/images/Tianyancha_3.png differ
diff --git a/static/images/Tianyancha_4.png b/static/images/Tianyancha_4.png
new file mode 100644
index 00000000000..87454f465e7
Binary files /dev/null and b/static/images/Tianyancha_4.png differ
diff --git a/static/images/Tianyancha_5.png b/static/images/Tianyancha_5.png
new file mode 100644
index 00000000000..7f076f21c64
Binary files /dev/null and b/static/images/Tianyancha_5.png differ
diff --git a/static/images/Tianyancha_6.png b/static/images/Tianyancha_6.png
new file mode 100644
index 00000000000..a8112823f6d
Binary files /dev/null and b/static/images/Tianyancha_6.png differ
diff --git a/static/images/Tianyancha_7.png b/static/images/Tianyancha_7.png
new file mode 100644
index 00000000000..33187b8aa5c
Binary files /dev/null and b/static/images/Tianyancha_7.png differ
diff --git a/static/images/Tianyancha_8.png b/static/images/Tianyancha_8.png
new file mode 100644
index 00000000000..55e05561950
Binary files /dev/null and b/static/images/Tianyancha_8.png differ
diff --git a/static/images/Tianyancha_9.png b/static/images/Tianyancha_9.png
new file mode 100644
index 00000000000..41aec4df0fd
Binary files /dev/null and b/static/images/Tianyancha_9.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]