This is an automated email from the ASF dual-hosted git repository.
jiafengzheng pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-doris.git
The following commit(s) were added to refs/heads/master by this push:
new b260bcba22 Modify some documents in the English version of doris
(#9064)
b260bcba22 is described below
commit b260bcba222c7f8e0183dc7331cc1f41474a0efc
Author: caoliang-web <[email protected]>
AuthorDate: Mon Apr 18 08:25:21 2022 +0800
Modify some documents in the English version of doris (#9064)
Modify some documents in the English version of doris
---
.../en/admin-manual/cluster-management/elastic-expansion.md | 4 ++--
new-docs/en/admin-manual/maint-monitor/metadata-operation.md | 2 +-
new-docs/en/advanced/alter-table/schema-change.md | 4 ++--
new-docs/en/advanced/partition/table-temp-partition.md | 2 +-
new-docs/en/advanced/resource.md | 2 +-
new-docs/en/advanced/variables.md | 10 +++++-----
new-docs/en/data-operate/export/export-manual.md | 5 +++++
.../en/data-operate/import/import-way/binlog-load-manual.md | 12 +++++++-----
.../en/data-operate/import/import-way/routine-load-manual.md | 2 +-
.../en/data-operate/import/import-way/spark-load-manual.md | 2 +-
new-docs/en/data-table/index/bitmap-index.md | 2 +-
new-docs/en/get-starting/get-starting.md | 1 +
new-docs/en/install/install-deploy.md | 6 +++---
13 files changed, 31 insertions(+), 23 deletions(-)
diff --git a/new-docs/en/admin-manual/cluster-management/elastic-expansion.md
b/new-docs/en/admin-manual/cluster-management/elastic-expansion.md
index fc3d69595e..bbfd122df9 100644
--- a/new-docs/en/admin-manual/cluster-management/elastic-expansion.md
+++ b/new-docs/en/admin-manual/cluster-management/elastic-expansion.md
@@ -102,7 +102,7 @@ You can also view the BE node through the front-end page
connection: ``http://fe
All of the above methods require Doris's root user rights.
-The expansion and scaling process of BE nodes does not affect the current
system operation and the tasks being performed, and does not affect the
performance of the current system. Data balancing is done automatically.
Depending on the amount of data available in the cluster, the cluster will be
restored to load balancing in a few hours to a day. For cluster load, see the
[Tablet Load Balancing
Document](../administrator-guide/operation/tablet-repair-and-balance.md).
+The expansion and scaling process of BE nodes does not affect the current
system operation and the tasks being performed, and does not affect the
performance of the current system. Data balancing is done automatically.
Depending on the amount of data available in the cluster, the cluster will be
restored to load balancing in a few hours to a day. For cluster load, see the
[Tablet Load Balancing Document](../maint-monitor/tablet-meta-tool.html).
### Add BE nodes
@@ -136,7 +136,7 @@ DECOMMISSION clause:
> ```CANCEL ALTER SYSTEM DECOMMISSION BACKEND
"be_host:be_heartbeat_service_port";```
> The order was cancelled. When cancelled, the data on the BE
will maintain the current amount of data remaining. Follow-up Doris re-load
balancing
-**For expansion and scaling of BE nodes in multi-tenant deployment
environments, please refer to the [Multi-tenant Design Document]
(./administrator-guide/operation/multi-tenant.md).**
+**For expansion and scaling of BE nodes in multi-tenant deployment
environments, please refer to the [Multi-tenant Design
Document](../multi-tenant.html).**
## Broker Expansion and Shrinkage
diff --git a/new-docs/en/admin-manual/maint-monitor/metadata-operation.md
b/new-docs/en/admin-manual/maint-monitor/metadata-operation.md
index fd1a774b5a..12977a7091 100644
--- a/new-docs/en/admin-manual/maint-monitor/metadata-operation.md
+++ b/new-docs/en/admin-manual/maint-monitor/metadata-operation.md
@@ -136,7 +136,7 @@ Single node FE is the most basic deployment mode. A
complete Doris cluster requi
### Add FE
-Adding FE processes is described in detail in the [Elastic Expansion
Documents](../elastic-expansion.html) and will not be repeated. Here are some
points for attention, as well as common problems.
+Adding FE processes is described in detail in the [Elastic Expansion
Documents](../../admin-manual/cluster-management/elastic-expansion.html) and
will not be repeated. Here are some points for attention, as well as common
problems.
1. Notes
diff --git a/new-docs/en/advanced/alter-table/schema-change.md
b/new-docs/en/advanced/alter-table/schema-change.md
index 76c6232ed3..cda62024be 100644
--- a/new-docs/en/advanced/alter-table/schema-change.md
+++ b/new-docs/en/advanced/alter-table/schema-change.md
@@ -68,7 +68,7 @@ The basic process of executing a Schema Change is to generate
a copy of the inde
Before starting the conversion of historical data, Doris will obtain a latest
transaction ID. And wait for all import transactions before this Transaction ID
to complete. This Transaction ID becomes a watershed. This means that Doris
guarantees that all import tasks after the watershed will generate data for
both the original Index and the new Index. In this way, when the historical
data conversion is completed, the data in the new Index can be guaranteed to be
complete.
## Create Job
-The specific syntax for creating a Schema Change can be found in the help
[ALTER TABLE
COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md)
for the description of the Schema Change section .
+The specific syntax for creating a Schema Change can be found in the help
[ALTER TABLE
COLUMN](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md)
for the description of the Schema Change section .
The creation of Schema Change is an asynchronous process. After the job is
submitted successfully, the user needs to view the job progress through the
`SHOW ALTER TABLE COLUMN` command.
## View Job
@@ -237,5 +237,5 @@ At the same time, columns that already exist in the Base
table are not allowed t
## More Help
-For more detailed syntax and best practices used by Schema Change, see [ALTER
TABLE
COLUMN](../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md
) command manual, you can also enter `HELP ALTER TABLE COLUMN` in the MySql
client command line for more help information.
+For more detailed syntax and best practices used by Schema Change, see [ALTER
TABLE
COLUMN](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-COLUMN.md
) command manual, you can also enter `HELP ALTER TABLE COLUMN` in the MySql
client command line for more help information.
diff --git a/new-docs/en/advanced/partition/table-temp-partition.md
b/new-docs/en/advanced/partition/table-temp-partition.md
index 94e735d36b..838b604736 100644
--- a/new-docs/en/advanced/partition/table-temp-partition.md
+++ b/new-docs/en/advanced/partition/table-temp-partition.md
@@ -277,7 +277,7 @@ Users can load data into temporary partitions or specify
temporary partitions fo
1. Atomic overwrite
- In some cases, the user wants to be able to rewrite the data of a certain
partition, but if it is dropped first and then loaded, there will be a period
of time when the data cannot be seen. At this moment, the user can first create
a corresponding temporary partition, load new data into the temporary
partition, and then replace the original partition atomically through the
`REPLACE` operation to achieve the purpose. For atomic overwrite operations of
non-partitioned tables, please re [...]
+ In some cases, the user wants to be able to rewrite the data of a certain
partition, but if it is dropped first and then loaded, there will be a period
of time when the data cannot be seen. At this moment, the user can first create
a corresponding temporary partition, load new data into the temporary
partition, and then replace the original partition atomically through the
`REPLACE` operation to achieve the purpose. For atomic overwrite operations of
non-partitioned tables, please re [...]
2. Modify the number of buckets
diff --git a/new-docs/en/advanced/resource.md b/new-docs/en/advanced/resource.md
index d49f4be07b..109b0fff59 100644
--- a/new-docs/en/advanced/resource.md
+++ b/new-docs/en/advanced/resource.md
@@ -132,7 +132,7 @@ PROPERTIES
`driver`: Indicates the driver dynamic library used by the ODBC external table.
The ODBC external table referring to the resource is required. The old MySQL
external table referring to the resource is optional.
-For the usage of ODBC resource, please refer to [ODBC of
Doris](../extending-doris/odbc-of-doris.html)
+For the usage of ODBC resource, please refer to [ODBC of
Doris](../ecosystem/external-table/odbc-of-doris.html)
#### Example
diff --git a/new-docs/en/advanced/variables.md
b/new-docs/en/advanced/variables.md
index 2bcef948a8..0d58e7ea65 100644
--- a/new-docs/en/advanced/variables.md
+++ b/new-docs/en/advanced/variables.md
@@ -160,11 +160,11 @@ Note that the comment must start with /*+ and can only
follow the SELECT.
* `disable_colocate_join`
- Controls whether the [Colocation
Join](./join-optimization/colocation-join.html) function is enabled. The
default is false, which means that the feature is enabled. True means that the
feature is disabled. When this feature is disabled, the query plan will not
attempt to perform a Colocation Join.
+ Controls whether the [Colocation
Join](../advanced/join-optimization/colocation-join.html) function is enabled.
The default is false, which means that the feature is enabled. True means that
the feature is disabled. When this feature is disabled, the query plan will not
attempt to perform a Colocation Join.
* `enable_bucket_shuffle_join`
- Controls whether the [Bucket Shuffle
Join](./join-optimization/bucket-shuffle-join.html) function is enabled. The
default is true, which means that the feature is enabled. False means that the
feature is disabled. When this feature is disabled, the query plan will not
attempt to perform a Bucket Shuffle Join.
+ Controls whether the [Bucket Shuffle
Join](../advanced/join-optimization/bucket-shuffle-join.html) function is
enabled. The default is true, which means that the feature is enabled. False
means that the feature is disabled. When this feature is disabled, the query
plan will not attempt to perform a Bucket Shuffle Join.
* `disable_streaming_preaggregations`
@@ -294,11 +294,11 @@ Translated with www.DeepL.com/Translator (free version)
* `max_pushdown_conditions_per_column`
- For the specific meaning of this variable, please refer to the description
of `max_pushdown_conditions_per_column` in [BE
Configuration](./config/be_config.md). This variable is set to -1 by default,
which means that the configuration value in `be.conf` is used. If the setting
is greater than 0, the query in the current session will use the variable
value, and ignore the configuration value in `be.conf`.
+ For the specific meaning of this variable, please refer to the description
of `max_pushdown_conditions_per_column` in [BE
Configuration](../admin-manual/config/be-config.html). This variable is set to
-1 by default, which means that the configuration value in `be.conf` is used.
If the setting is greater than 0, the query in the current session will use the
variable value, and ignore the configuration value in `be.conf`.
* `max_scan_key_num`
- For the specific meaning of this variable, please refer to the description
of `doris_max_scan_key_num` in [BE Configuration](./config/be_config.md). This
variable is set to -1 by default, which means that the configuration value in
`be.conf` is used. If the setting is greater than 0, the query in the current
session will use the variable value, and ignore the configuration value in
`be.conf`.
+ For the specific meaning of this variable, please refer to the description
of `doris_max_scan_key_num` in [BE
Configuration](../admin-manual/config/be-config.html). This variable is set to
-1 by default, which means that the configuration value in `be.conf` is used.
If the setting is greater than 0, the query in the current session will use the
variable value, and ignore the configuration value in `be.conf`.
* `net_buffer_length`
@@ -350,7 +350,7 @@ Translated with www.DeepL.com/Translator (free version)
* `sql_mode`
- Used to specify SQL mode to accommodate certain SQL dialects. For the SQL
mode, see [here](./sql-mode.md).
+ Used to specify SQL mode to accommodate certain SQL dialects. For the SQL
mode, see
[here](https://doris.apache.org/zh-CN/administrator-guide/sql-mode.html).
* `sql_safe_updates`
diff --git a/new-docs/en/data-operate/export/export-manual.md
b/new-docs/en/data-operate/export/export-manual.md
index 0a90961300..2dfb2f30a5 100644
--- a/new-docs/en/data-operate/export/export-manual.md
+++ b/new-docs/en/data-operate/export/export-manual.md
@@ -95,6 +95,11 @@ Among them, `c69fcf2b6db5420f-a96b94c1ff8bccef` is the query
ID of the query pla
When all data is exported, Doris will rename these files to the user-specified
path.
+### Broker parameter
+
+Export needs to use the Broker process to access remote storage. Different
brokers need to provide different parameters. For details, please refer to
[Broker documentation](../../advanced/broker.html)
+
+
## Start Export
For detailed usage of Export, please refer to [SHOW
EXPORT](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-EXPORT.html).
diff --git a/new-docs/en/data-operate/import/import-way/binlog-load-manual.md
b/new-docs/en/data-operate/import/import-way/binlog-load-manual.md
index 843a9e5d6b..5a891b31c2 100644
--- a/new-docs/en/data-operate/import/import-way/binlog-load-manual.md
+++ b/new-docs/en/data-operate/import/import-way/binlog-load-manual.md
@@ -306,7 +306,7 @@ Instance parses binlog logs through the parser module, and
the parsed data is ca
The store is actually a ring queue. Users can configure its length and storage
space by themselves.
-
+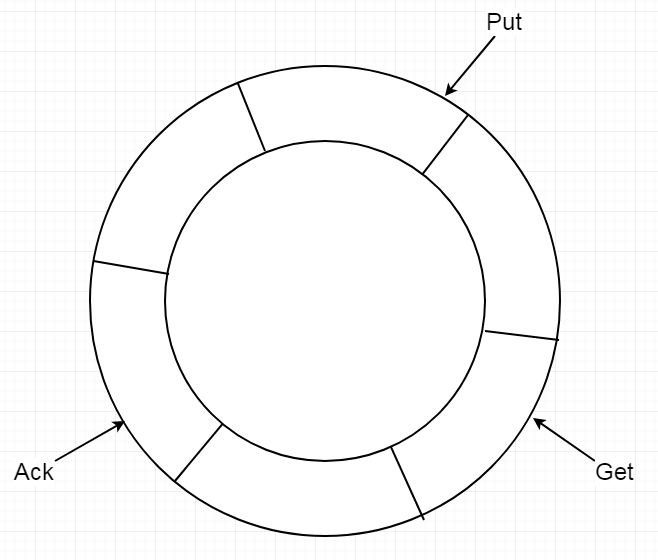
Store manages the data in the queue through three pointers:
@@ -342,6 +342,8 @@ User needs to first create the target table which is
corresponding to the MySQL
Binlog Load can only support unique target tables from now, and the batch
delete feature of the target table must be activated.
+For the method of enabling Batch Delete, please refer to the batch delete
function in [ALTER TABLE
PROPERTY](../../../sql-manual/sql-reference-v2/Data-Definition-Statements/Alter/ALTER-TABLE-PROPERTY.html).
+
Example:
```
@@ -360,7 +362,7 @@ ALTER TABLE canal_test.test1 ENABLE FEATURE "BATCH_DELETE";
### Create SyncJob
-The detailed syntax of creating a SyncJob can be viewd in `help create sync
job` command. Here we mainly introduce the precautions when creating a SyncJob.
+The detailed syntax for creating a data synchronization job can be connected
to Doris and [CREATE SYNC
JOB](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/CREATE-SYNC-JOB.html)
to view the syntax help. Here is a detailed introduction to the precautions
when creating a job.
* job_name
@@ -393,7 +395,7 @@ The detailed syntax of creating a SyncJob can be viewd in
`help create sync job`
### Show Job Status
-Specific commands and examples for viewing job status can be viewed through
the [SHOW SYNC
JOB](../../../sql-manual/sql-reference-v2/show/SHOW-SYNC-JOB.html) command.
+Specific commands and examples for viewing job status can be viewed through
the [SHOW SYNC
JOB](../../../sql-manual/sql-reference-v2/Show-Statements/SHOW-SYNC-JOB.html)
command.
The parameters in the result set have the following meanings:
@@ -443,7 +445,7 @@ The parameters in the result set have the following
meanings:
Users can control the status of jobs through `stop/pause/resume` commands.
-You can use `HELP STOP SYNC JOB;`, `HELP PAUSE SYNC JOB`; And `HELP RESUME
SYNC JOB;` commands to view help and examples.
+You can use [STOP SYNC
JOB](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/STOP-SYNC-JOB.html)
; [PAUSE SYNC
JOB](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/PAUSE-SYNC-JOB.html);
And [RESUME SYNC
JOB](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/RESUME-SYNC-JOB.html);
commands to view help and examples.
## Case Combat
@@ -519,4 +521,4 @@ The following configuration belongs to the system level
configuration of SyncJob
## More Help
-For more detailed syntax and best practices used by Binlog Load, see [Binlog
Load](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/BINLOG-
LOAD.html) command manual, you can also enter `HELP BINLOG` in the MySql
client command line for more help information.
\ No newline at end of file
+For more detailed syntax and best practices used by Binlog Load, see [Binlog
Load](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/CREATE-SYNC-JOB.html)
command manual, you can also enter `HELP BINLOG` in the MySql client command
line for more help information.
\ No newline at end of file
diff --git a/new-docs/en/data-operate/import/import-way/routine-load-manual.md
b/new-docs/en/data-operate/import/import-way/routine-load-manual.md
index 9d6e845490..e989c8ce20 100644
--- a/new-docs/en/data-operate/import/import-way/routine-load-manual.md
+++ b/new-docs/en/data-operate/import/import-way/routine-load-manual.md
@@ -240,7 +240,7 @@ You can only view tasks that are currently running, and
tasks that have ended an
### Alter job
-Users can modify jobs that have been created. Specific instructions can be
viewed through the `HELP ALTER ROUTINE LOAD;` command. Or refer to [ALTER
ROUTINE
LOAD](../../sql-reference/sql-statements/Data%20Manipulation/alter-routine-load.md).
+Users can modify jobs that have been created. Specific instructions can be
viewed through the `HELP ALTER ROUTINE LOAD;` command. Or refer to [ALTER
ROUTINE
LOAD](../../../sql-manual/sql-reference-v2/Data-Manipulation-Statements/Load/ALTER-ROUTINE-LOAD.html).
### Job Control
diff --git a/new-docs/en/data-operate/import/import-way/spark-load-manual.md
b/new-docs/en/data-operate/import/import-way/spark-load-manual.md
index a536efae9e..2f4f1d956a 100644
--- a/new-docs/en/data-operate/import/import-way/spark-load-manual.md
+++ b/new-docs/en/data-operate/import/import-way/spark-load-manual.md
@@ -128,7 +128,7 @@ In the existing Doris import process, the data structure of
global dictionary is
## Hive Bitmap UDF
-Spark supports loading hive-generated bitmap data directly into Doris, see
[hive-bitmap-udf
documentation](../../ecosystem/external-table/hive-bitmap-udf.html)
+Spark supports loading hive-generated bitmap data directly into Doris
## Basic operation
diff --git a/new-docs/en/data-table/index/bitmap-index.md
b/new-docs/en/data-table/index/bitmap-index.md
index 09fd5db7bf..853f1ad63c 100644
--- a/new-docs/en/data-table/index/bitmap-index.md
+++ b/new-docs/en/data-table/index/bitmap-index.md
@@ -33,7 +33,7 @@ This document focuses on how to create an index job, as well
as some considerati
## Basic Principles
Creating and dropping index is essentially a schema change job. For details,
please refer to
-[Schema Change](alter-table-schema-change.html).
+[Schema Change](../../advanced/alter-table/schema-change.html).
## Syntax
### Create index
diff --git a/new-docs/en/get-starting/get-starting.md
b/new-docs/en/get-starting/get-starting.md
index bfbda2b793..a0b714dcdf 100644
--- a/new-docs/en/get-starting/get-starting.md
+++ b/new-docs/en/get-starting/get-starting.md
@@ -228,6 +228,7 @@ FE splits the query plan into fragments and sends them to
BE for task execution.
For a complete parameter comparison table, please go to [Profile parameter
analysis](../admin-manual/query-profile.html) View Details
+
#### Library table operations
- View database list
diff --git a/new-docs/en/install/install-deploy.md
b/new-docs/en/install/install-deploy.md
index 3cb4cd17b0..ce8fdab2e9 100644
--- a/new-docs/en/install/install-deploy.md
+++ b/new-docs/en/install/install-deploy.md
@@ -158,7 +158,7 @@ BROKER does not currently have, nor does it need,
priority\_networks. Broker's s
By default, doris is case-sensitive. If there is a need for case-insensitive
table names, you need to set it before cluster initialization. The table name
case sensitivity cannot be changed after cluster initialization is completed.
-See the section on `lower_case_table_names` variables in
[Variables](../administrator-guide/variables.md) for details.
+See the section on `lower_case_table_names` variables in
[Variables](../advanced/variables.html#variable-setting-and-viewing) for
details.
## Cluster deployment
@@ -351,7 +351,7 @@ You can also view the BE node through the front-end page
connection: ``http://fe
All of the above methods require Doris's root user rights.
-The expansion and scaling process of BE nodes does not affect the current
system operation and the tasks being performed, and does not affect the
performance of the current system. Data balancing is done automatically.
Depending on the amount of data available in the cluster, the cluster will be
restored to load balancing in a few hours to a day. For cluster load, see the
[Tablet Load Balancing
Document](../administrator-guide/operation/tablet-repair-and-balance.md).
+The expansion and scaling process of BE nodes does not affect the current
system operation and the tasks being performed, and does not affect the
performance of the current system. Data balancing is done automatically.
Depending on the amount of data available in the cluster, the cluster will be
restored to load balancing in a few hours to a day. For cluster load, see the
[Tablet Load Balancing
Document](../admin-manual/maint-monitor/tablet-meta-tool.html).
#### Add BE nodes
@@ -385,7 +385,7 @@ DECOMMISSION clause:
> ```CANCEL ALTER SYSTEM DECOMMISSION BACKEND
> "be_host:be_heartbeat_service_port";```
> The order was cancelled. When cancelled, the data on the BE will
> maintain the current amount of data remaining. Follow-up Doris re-load
> balancing
-**For expansion and scaling of BE nodes in multi-tenant deployment
environments, please refer to the [Multi-tenant Design Document]
(./administrator-guide/operation/multi-tenant.md).**
+**For expansion and scaling of BE nodes in multi-tenant deployment
environments, please refer to the [Multi-tenant Design
Document](../admin-manual/maint-monitor/multi-tenant.html).**
### Broker Expansion and Shrinkage
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}