hou-rong opened a new issue, #12185: URL: https://github.com/apache/doris/issues/12185
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-doris/issues?q=is%3Aissue) and found no similar issues. ### Description # 简介 通过 Spark Load 进行数据导入,发现当前瓶颈在 SparkDPP 中的 processRDDAggregate 中的 reduceByKey 的分区数太低导致数据量大的情况下 ETL 执行速度慢 # 测试过程 ## 数据集和导入方案 ### 【数据源】Hive 数据表 - 数据集 1.2 TB parquet 数据。 - 高表,1200 亿行数据。 ``` SQL drop table if exists hive_testing; CREATE TABLE hive_testing ( `tag_group_id` varchar(1024) COMMENT '', `member_id` bigint COMMENT '', `tag_value_id` string COMMENT '', `tag_range` int COMMENT '', `confidence` int COMMENT '', `tag_id` varchar(1024) COMMENT '', `bucket` bigint COMMENT '' ) ENGINE=hive PROPERTIES ( -- hive 相关配置 ); ``` ### 【目标】Doris 数据表 ``` SQL drop table if exists `testing`; CREATE TABLE `testing` ( `tag_group_id` bigint(20) NULL COMMENT "", `tag_value_id` varchar(64) NULL COMMENT "", `tag_range` int(11) NOT NULL DEFAULT "0" COMMENT "", `confidence` tinyint(4) NULL DEFAULT "100" COMMENT "", `bucket` bigint(20) NULL COMMENT "", `member_id` bitmap BITMAP_UNION NULL COMMENT "" ) ENGINE=OLAP AGGREGATE KEY(`tag_group_id`, `tag_value_id`, `tag_range`, `confidence`, `bucket`) COMMENT "testing" DISTRIBUTED BY HASH(`bucket`) BUCKETS 512 PROPERTIES ( -- doris 相关配置 ); ``` ### 【过程】导入语句 spark 集群配置 - 动态 executor,400 - 2000. - executor 4 核 16 内存 ``` SQL LOAD LABEL test_db.testing_label ( DATA FROM TABLE hive_testing INTO TABLE testing SET(member_id=to_bitmap(member_id)) ) WITH RESOURCE "your resource" ( -- 资源配置 ) PROPERTIES ( -- load 配置 ); ``` ## 性能差异 ### 【修改前】reduceByKey 中传入写死的 200 限制了分区数 - Stage 2 处理数据时间 1 小时 30 分 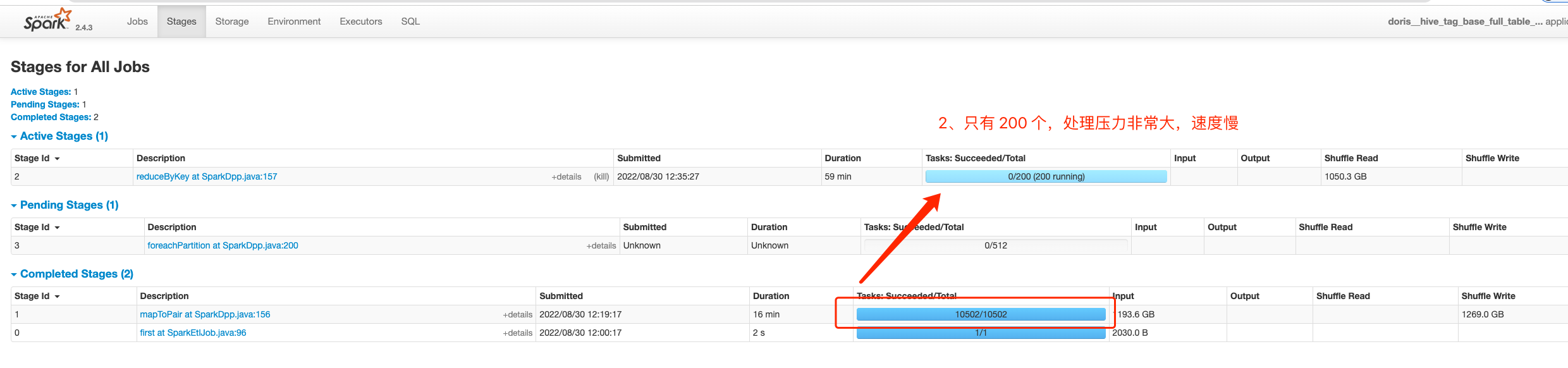  ###【修改后】reduceByKey 过程使用前置节点的分区数 - Stage 2 处理数据时间 1.8 分 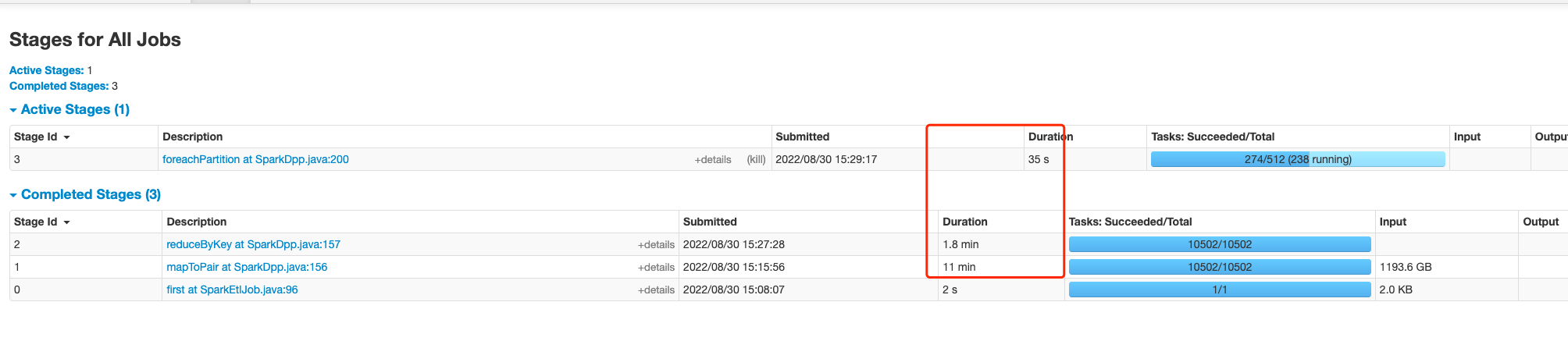  ### Solution # 修改方式 - 删除如图所示的 aggregateConcurrency - reduceByKey 删除指定的分区数,使用 Stage 1 的分区数来进行计算 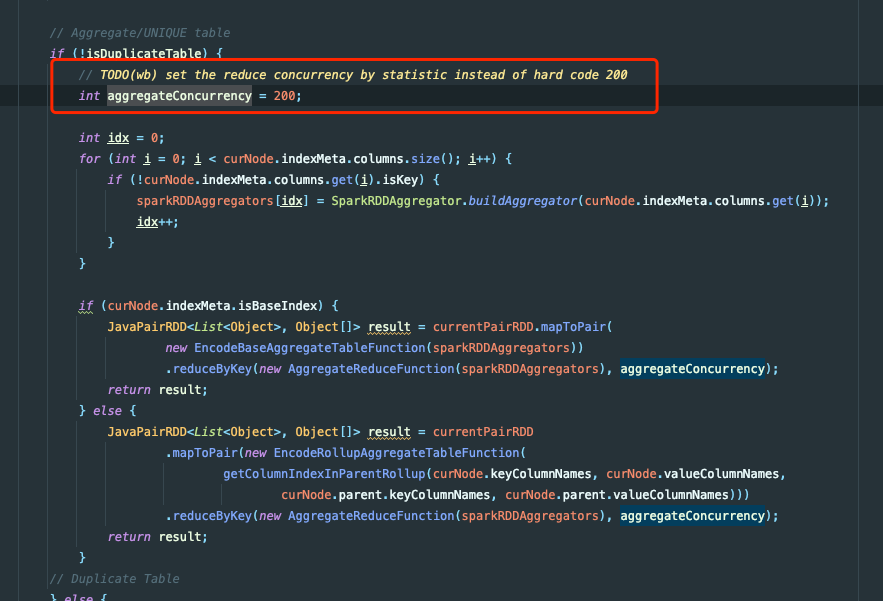 ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}