eldenmoon opened a new issue, #12246: URL: https://github.com/apache/doris/issues/12246
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-doris/issues?q=is%3Aissue) and found no similar issues. ### Description Currently we record length of array in a seperate column writer called `_length_writer`, but I think recording length of array could lead to bad seek performance.Below is the performance issue i encountered: I have a table which is ``` CREATE TABLE `nested` ( `qid` bigint(20) NULL COMMENT "", `tag` ARRAY<text> NULL COMMENT "", `creationDate` datetime NULL COMMENT "", `title` text NULL COMMENT "", `user` text NULL COMMENT "", `answers.user` ARRAY<text> NULL COMMENT "", `answers.date` ARRAY<datetime> NULL COMMENT "", INDEX tag_idx (`tag`) USING INVERTED COMMENT '', INDEX creation_date_idx (`creationDate`) USING INVERTED COMMENT '', INDEX title_idx (`title`) USING INVERTED COMMENT '', INDEX user_idx (`user`) USING INVERTED(NONE) COMMENT '', INDEX answers_user_idx (`answers.user`) USING INVERTED COMMENT '', INDEX answers_date_idx (`answers.date`) USING INVERTED COMMENT '', ... ) ENGINE=OLAP DUPLICATE KEY(`qid`) COMMENT "OLAP" DISTRIBUTED BY HASH(`qid`) BUCKETS 18 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2", "compression" = "ZSTD" ); ``` As the sql above, I created inverted index(which is similar to bitmap index) on some columns. this is the data sample ``` {"title": "Display Progress Bar at the Time of Processing", "qid": "1000000", "answers": [{"date": "2009-06-16T09:55:57.320", "user": "Micha\u0142 Niklas (22595)"}, {"date": "2009-06-17T12:34:22.643", "user": "Jack Njiri (77153)"}], "tag": ["vb6", "progress-bar"], "user": "Jash", "creationDate": "2009-06-16T07:28:42.770"} ``` Then I run a benchmark with sql like `select * from {}.{} where title match '{}' limit 10`(We have a special sql word `match` which will filter rows when `title` contains this word by inverted index). Then I found that the sql could be slow due to ` ArrayFileColumnIterator::seek_to_ordinal` 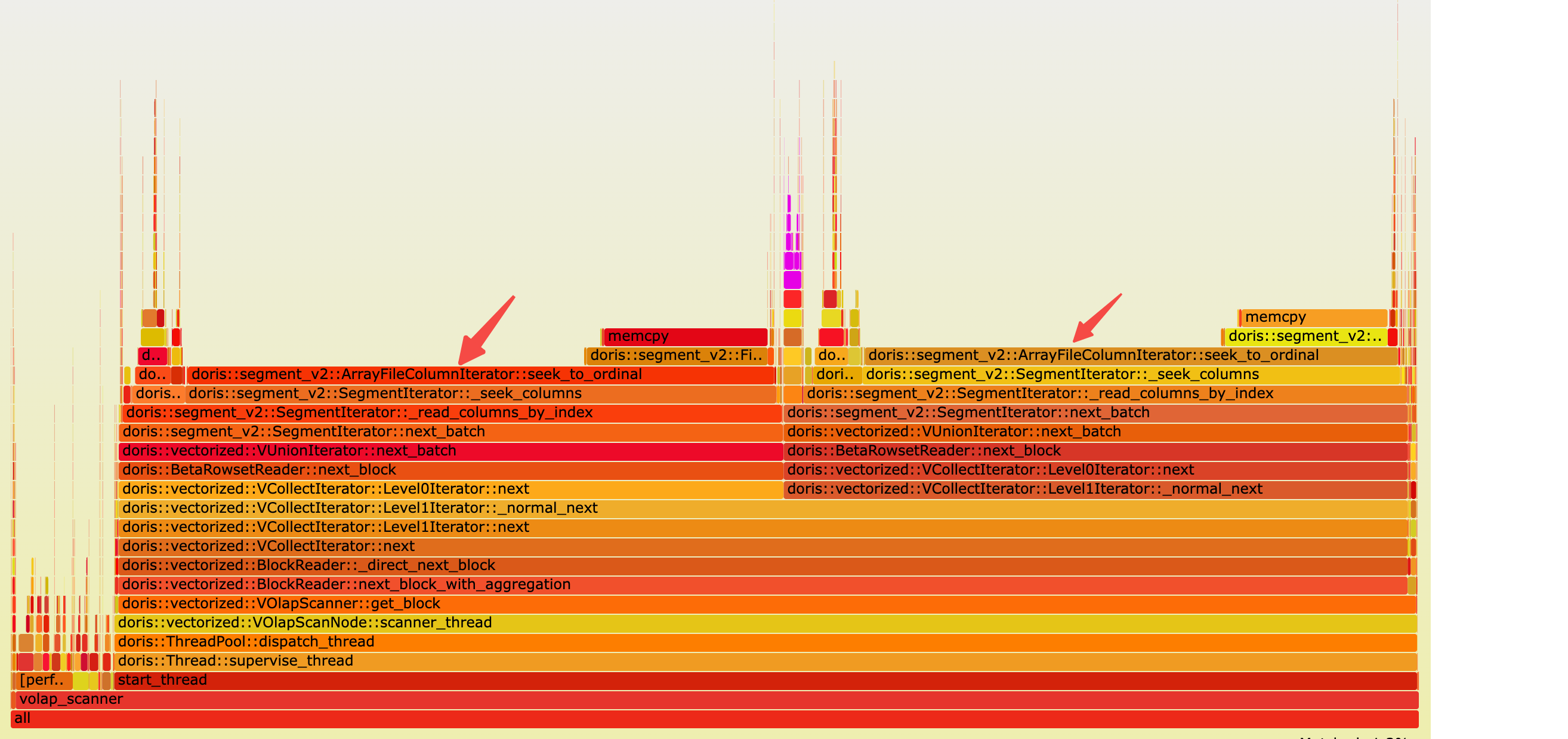 The reason is that: 1. Filtered row_ids from index is very discrete and we need do lots of column seek_to_ordinal 2. The compute of ArrayFileColumnIterator::seek_to_ordinal is very slow. We need to caculate ordinal of specified ordinal_id by read from _length_iterator and needs lots of memory copy and then sum massive items read from _length_iterator to get the specified ordinal_id.The length_iterator's page could contains thousands of length items(which I saw more than 50000), caculate them could lead to very bad performance 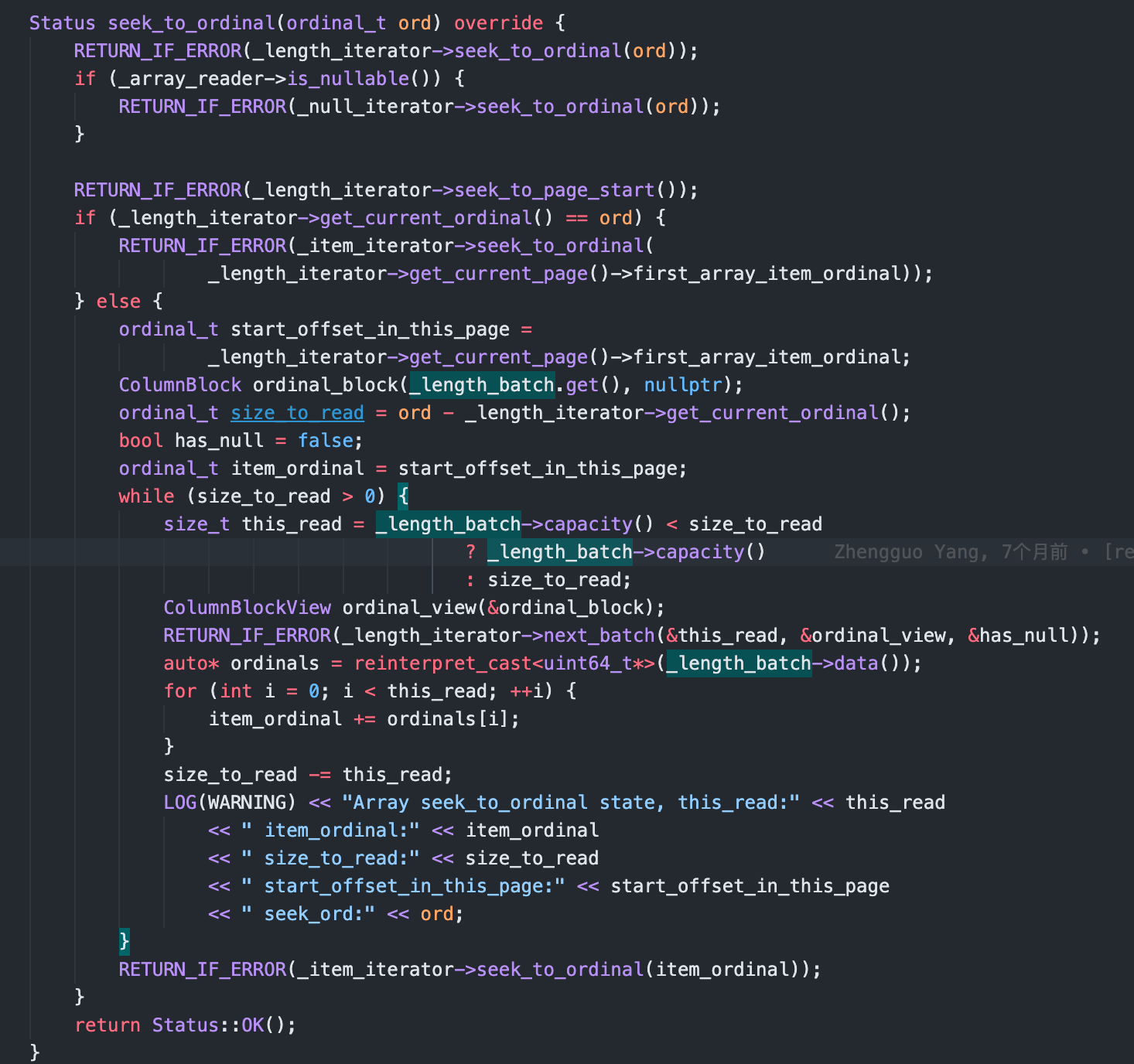 ### Solution We could change `_length_writer` to `_offset_writer`, then seek_to_ordinal could be very fast(could directly get the ordinal of _item_iterator by read only 1 item from _offset_writer) after I modified related code, the performace is as below 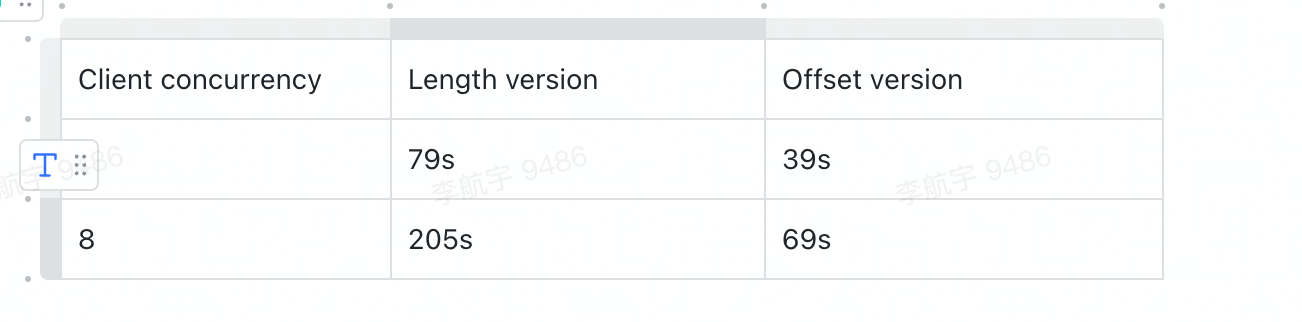 ### Are you willing to submit PR? - [X] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}