This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new f9cef23cff2 (docs) add TME blog en & zh (#206)
f9cef23cff2 is described below
commit f9cef23cff2492fee1df442fc307f5d2cd8ef274
Author: Hu Yanjun <[email protected]>
AuthorDate: Tue Mar 7 16:06:59 2023 +0800
(docs) add TME blog en & zh (#206)
* (docs) add TME blog en & zh
---
blog/Tencent Music.md | 259 +++++++++++++++++
...274\224\350\277\233\345\256\236\350\267\265.md" | 312 +++++++++++++++++++++
static/images/TME/TME.png | Bin 0 -> 377215 bytes
static/images/TME/TME_1.png | Bin 0 -> 172574 bytes
static/images/TME/TME_10.png | Bin 0 -> 215308 bytes
static/images/TME/TME_11.png | Bin 0 -> 241435 bytes
static/images/TME/TME_2.png | Bin 0 -> 194071 bytes
static/images/TME/TME_3.png | Bin 0 -> 212900 bytes
static/images/TME/TME_4.png | Bin 0 -> 214629 bytes
static/images/TME/TME_5.png | Bin 0 -> 219907 bytes
static/images/TME/TME_6.png | Bin 0 -> 110378 bytes
static/images/TME/TME_7.png | Bin 0 -> 133921 bytes
static/images/TME/TME_8.png | Bin 0 -> 176926 bytes
static/images/TME/TME_9.png | Bin 0 -> 187956 bytes
14 files changed, 571 insertions(+)
diff --git a/blog/Tencent Music.md b/blog/Tencent Music.md
new file mode 100644
index 00000000000..bf649e35a17
--- /dev/null
+++ b/blog/Tencent Music.md
@@ -0,0 +1,259 @@
+---
+{
+ 'title': 'Tencent Data Engineer: Why We Go from ClickHouse to Apache
Doris?',
+ 'summary': "Evolution of the data processing architecture of Tencent Music
Entertainment towards better performance and simpler maintenance.",
+ 'date': '2023-03-07',
+ 'author': 'Jun Zhang & Kai Dai',
+ 'tags': ['Best Practice'],
+}
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+
+
+This article is co-written by me and my colleague Kai Dai. We are both data
platform engineers at Tencent Music (NYSE: TME), a music streaming service
provider with a whopping 800 million monthly active users. To drop the number
here is not to brag but to give a hint of the sea of data that my poor
coworkers and I have to deal with everyday.
+
+# What We Use ClickHouse For?
+
+The music library of Tencent Music contains data of all forms and types:
recorded music, live music, audios, videos, etc. As data platform engineers,
our job is to distill information from the data, based on which our teammates
can make better decisions to support our users and musical partners.
+
+Specifically, we do all-round analysis of the songs, lyrics, melodies, albums,
and artists, turn all this information into data assets, and pass them to our
internal data users for inventory counting, user profiling, metrics analysis,
and group targeting.
+
+
+
+We stored and processed most of our data in Tencent Data Warehouse (TDW), an
offline data platform where we put the data into various tag and metric systems
and then created flat tables centering each object (songs, artists, etc.).
+
+Then we imported the flat tables into ClickHouse for analysis and
Elasticsearch for data searching and group targeting.
+
+After that, our data analysts used the data under the tags and metrics they
needed to form datasets for different usage scenarios, during which they could
create their own tags and metrics.
+
+The data processing pipeline looked like this:
+
+
+
+# The Problems with ClickHouse
+
+When working with the above pipeline, we encountered a few difficulties:
+
+1. **Partial Update**: Partial update of columns was not supported. Therefore,
any latency from any one of the data sources could delay the creation of flat
tables, and thus undermine data timeliness.
+2. **High storage cost**: Data under different tags and metrics was updated at
different frequencies. As much as ClickHouse excelled in dealing with flat
tables, it was a huge waste of storage resources to just pour all data into a
flat table and partition it by day, not to mention the maintenance cost coming
with it.
+3. **High maintenance cost**: Architecturally speaking, ClickHouse was
characterized by the strong coupling of storage nodes and compute nodes. Its
components were heavily interdependent, adding to the risks of cluster
instability. Plus, for federated queries across ClickHouse and Elasticsearch,
we had to take care of a huge amount of connection issues. That was just
tedious.
+
+# Transition to Apache Doris
+
+[Apache Doris](https://github.com/apache/doris), a real-time analytical
database, boasts a few features that are exactly what we needed in solving our
problems:
+
+1. **Partial update**: Doris supports a wide variety of data models, among
which the Aggregate Model supports real-time partial update of columns.
Building on this, we can directly ingest raw data into Doris and create flat
tables there. The ingestion goes like this: Firstly, we use Spark to load data
into Kafka; then, any incremental data will be updated to Doris and
Elasticsearch via Flink. Meanwhile, Flink will pre-aggregate the data so as to
release burden on Doris and Elasticsearch.
+2. **Storage cost**: Doris supports multi-table join queries and federated
queries across Hive, Iceberg, Hudi, MySQL, and Elasticsearch. This allows us to
split the large flat tables into smaller ones and partition them by update
frequency. The benefits of doing so include a relief of storage burden and an
increase of query throughput.
+3. **Maintenance cost**: Doris is of simple architecture and is compatible
with MySQL protocol. Deploying Doris only involves two processes (FE and BE)
with no dependency on other systems, making it easy to operate and maintain.
Also, Doris supports querying external ES data tables. It can easily interface
with the metadata in ES and automatically map the table schema from ES so we
can conduct queries on Elasticsearch data via Doris without grappling with
complex connections.
+
+What’s more, Doris supports multiple data ingestion methods, including batch
import from remote storage such as HDFS and S3, data reads from MySQL binlog
and Kafka, and real-time data synchronization or batch import from MySQL,
Oracle, and PostgreSQL. It ensures service availability and data reliability
through a consistency protocol and is capable of auto debugging. This is great
news for our operators and maintainers.
+
+Statistically speaking, these features have cut our storage cost by 42% and
development cost by 40%.
+
+During our usage of Doris, we have received lots of support from the open
source Apache Doris community and timely help from the SelectDB team, which is
now running a commercial version of Apache Doris.
+
+
+
+# Further Improvement to Serve Our Needs
+
+## Introduce a Semantic Layer
+
+Speaking of the datasets, on the bright side, our data analysts are given the
liberty of redefining and combining the tags and metrics at their convenience.
But on the dark side, high heterogeneity of the tag and metric systems leads to
more difficulty in their usage and management.
+
+Our solution is to introduce a semantic layer in our data processing pipeline.
The semantic layer is where all the technical terms are translated into more
comprehensible concepts for our internal data users. In other words, we are
turning the tags and metrics into first-class citizens for data definement and
management.
+
+
+
+**Why would this help?**
+
+For data analysts, all tags and metrics will be created and shared at the
semantic layer so there will be less confusion and higher efficiency.
+
+For data users, they no longer need to create their own datasets or figure out
which one is applicable for each scenario but can simply conduct queries on
their specified tagset and metricset.
+
+## Upgrade the Semantic Layer
+
+Explicitly defining the tags and metrics at the semantic layer was not enough.
In order to build a standardized data processing system, our next goal was to
ensure consistent definition of tags and metrics throughout the whole data
processing pipeline.
+
+For this sake, we made the semantic layer the heart of our data management
system:
+
+
+
+**How does it work?**
+
+All computing logics in TDW will be defined at the semantic layer in the form
of a single tag or metric.
+
+The semantic layer receives logic queries from the application side, selects
an engine accordingly, and generates SQL. Then it sends the SQL command to TDW
for execution. Meanwhile, it might also send configuration and data ingestion
tasks to Doris and decide which metrics and tags should be accelerated.
+
+In this way, we have made the tags and metrics more manageable. A fly in the
ointment is that since each tag and metric is individually defined, we are
struggling with automating the generation of a valid SQL statement for the
queries. If you have any idea about this, you are more than welcome to talk to
us.
+
+# Give Full Play to Apache Doris
+
+As you can see, Apache Doris has played a pivotal role in our solution.
Optimizing the usage of Doris can largely improve our overall data processing
efficiency. So in this part, we are going to share with you what we do with
Doris to accelerate data ingestion and queries and reduce costs.
+
+## What We Want?
+
+
+
+Currently, we have 800+ tags and 1300+ metrics derived from the 80+ source
tables in TDW.
+
+When importing data from TDW to Doris, we hope to achieve:
+
+- **Real-time availability:** In addition to the traditional T+1 offline data
ingestion, we require real-time tagging.
+- **Partial update**: Each source table generates data through its own ETL
task at various paces and involves only part of the tags and metrics, so we
require the support for partial update of columns.
+- **High performance**: We need a response time of only a few seconds in group
targeting, analysis and reporting scenarios.
+- **Low costs**: We hope to reduce costs as much as possible.
+
+## What We Do?
+
+1. **Generate Flat Tables in Flink Instead of TDW**
+
+
+
+Generating flat tables in TDW has a few downsides:
+
+- **High storage cost**: TDW has to maintain an extra flat table apart from
the discrete 80+ source tables. That’s huge redundancy.
+- **Low real-timeliness**: Any delay in the source tables will be augmented
and retard the whole data link.
+- **High development cost**: To achieve real-timeliness would require extra
development efforts and resources.
+
+On the contrary, generating flat tables in Doris is much easier and less
expensive. The process is as follows:
+
+- Use Spark to import new data into Kafka in an offline manner.
+- Use Flink to consume Kafka data.
+- Create a flat table via the primary key ID.
+- Import the flat table into Doris.
+
+As is shown below, Flink has aggregated the five lines of data, of which
“ID”=1, into one line in Doris, reducing the data writing pressure on Doris.
+
+
+
+This can largely reduce storage costs since TDW no long has to maintain two
copies of data and KafKa only needs to store the new data pending for
ingestion. What’s more, we can add whatever ETL logic we want into Flink and
reuse lots of development logic for offline and real-time data ingestion.
+
+**2. Name the Columns Smartly**
+
+As we mentioned, the Aggregate Model of Doris allows partial update of
columns. Here we provide a simple introduction to other data models in Doris
for your reference:
+
+**Unique Model**: This is applicable for scenarios requiring primary key
uniqueness. It only keeps the latest data of the same primary key ID. (As far
as we know, the Apache Doris community is planning to include partial update of
columns in the Unique Model, too.)
+
+**Duplicate Model**: This model stores all original data exactly as it is
without any pre-aggregation or deduplication.
+
+After determining the data model, we had to think about how to name the
columns. Using the tags or metrics as column names was not a choice because:
+
+I. Our internal data users might need to rename the metrics or tags, but Doris
1.1.3 does not support modification of column names.
+
+II. Tags might be taken online and offline frequently. If that involves the
adding and dropping of columns, it will be not only time-consuming but also
detrimental to query performance.
+
+Instead, we do the following:
+
+- **For flexible renaming of tags and metrics**, we use MySQL tables to store
the metadata (name, globally unique ID, status, etc.). Any change to the names
will only happen in the metadata but will not affect the table schema in Doris.
For example, if a `song_name` is given an ID of 4, it will be stored with the
column name of a4 in Doris. Then if the `song_name`is involved in a query, it
will be converted to a4 in SQL.
+- **For the onlining and offlining of tags**, we sort out the tags based on
how frequently they are being used. The least used ones will be given an
offline mark in their metadata. No new data will be put under the offline tags
but the existing data under those tags will still be available.
+- **For real-time availability of newly added tags and metrics**, we prebuild
a few ID columns in Doris tables based on the mapping of name IDs. These
reserved ID columns will be allocated to the newly added tags and metrics.
Thus, we can avoid table schema change and the consequent overheads. Our
experience shows that only 10 minutes after the tags and metrics are added, the
data under them can be available.
+
+Noteworthily, the recently released Doris 1.2.0 supports Light Schema Change,
which means that to add or remove columns, you only need to modify the metadata
in FE. Also, you can rename the columns in data tables as long as you have
enabled Light Schema Change for the tables. This is a big trouble saver for us.
+
+**3. Optimize Date Writing**
+
+Here are a few practices that have reduced our daily offline data ingestion
time by 75% and our CUMU compaction score from 600+ to 100.
+
+- Flink pre-aggregation: as is mentioned above.
+- Auto-sizing of writing batch: To reduce Flink resource usage, we enable the
data in one Kafka Topic to be written into various Doris tables and realize the
automatic alteration of batch size based on the data amount.
+- Optimization of Doris data writing: fine-tune the the sizes of tablets and
buckets as well as the compaction parameters for each scenario:
+
+```
+max_XXXX_compaction_thread
+max_cumulative_compaction_num_singleton_deltas
+```
+
+- Optimization of the BE commit logic: conduct regular caching of BE lists,
commit them to the BE nodes batch by batch, and use finer load balancing
granularity.
+
+
+
+**4. Use Dori-on-ES in Queries**
+
+About 60% of our data queries involve group targeting. Group targeting is to
find our target data by using a set of tags as filters. It poses a few
requirements for our data processing architecture:
+
+- Group targeting related to APP users can involve very complicated logic.
That means the system must support hundreds of tags as filters simultaneously.
+- Most group targeting scenarios only require the latest tag data. However,
metric queries need to support historical data.
+- Data users might need to perform further aggregated analysis of metric data
after group targeting.
+- Data users might also need to perform detailed queries on tags and metrics
after group targeting.
+
+After consideration, we decided to adopt Doris-on-ES. Doris is where we store
the metric data for each scenario as a partition table, while Elasticsearch
stores all tag data. The Doris-on-ES solution combines the distributed query
planning capability of Doris and the full-text search capability of
Elasticsearch. The query pattern is as follows:
+
+```
+SELECT tag, agg(metric)
+ FROM Doris
+ WHERE id in (select id from Es where tagFilter)
+ GROUP BY tag
+```
+
+As is shown, the ID data located in Elasticsearch will be used in the
sub-query in Doris for metric analysis.
+
+In practice, we find that the query response time is related to the size of
the target group. If the target group contains over one million objects, the
query will take up to 60 seconds. If it is even larger, a timeout error might
occur.
+
+After investigation, we identified our two biggest time wasters:
+
+I. When Doris BE pulls data from Elasticsearch (1024 lines at a time by
default), for a target group of over one million objects, the network I/O
overhead can be huge.
+
+II. After the data pulling, Doris BE needs to conduct Join operations with
local metric tables via SHUFFLE/BROADCAST, which can cost a lot.
+
+
+
+Thus, we make the following optimizations:
+
+- Add a query session variable `es_optimize` that specifies whether to enable
optimization.
+- In data writing into ES, add a BK column to store the bucket number after
the primary key ID is hashed. The algorithm is the same as the bucketing
algorithm in Doris (CRC32).
+- Use Doris BE to generate a Bucket Join execution plan, dispatch the bucket
number to BE ScanNode and push it down to ES.
+- Use ES to compress the queried data; turn multiple data fetch into one and
reduce network I/O overhead.
+- Make sure that Doris BE only pulls the data of buckets related to the local
metric tables and conducts local Join operations directly to avoid data
shuffling between Doris BEs.
+
+
+
+As a result, we reduce the query response time for large group targeting from
60 seconds to a surprising 3.7 seconds.
+
+Community information shows that Doris is going to support inverted indexing
since version 2.0.0, which is soon to be released. With this new version, we
will be able to conduct full-text search on text types, equivalence or range
filtering of texts, numbers, and datetime, and conveniently combine AND, OR,
NOT logic in filtering since the inverted indexing supports array types. This
new feature of Doris is expected to deliver 3~5 times better performance than
Elasticsearch on the same task.
+
+**5. Refine the Management of Data**
+
+Doris’ capability of cold and hot data separation provides the foundation of
our cost reduction strategies in data processing.
+
+- Based on the TTL mechanism of Doris, we only store data of the current year
in Doris and put the historical data before that in TDW for lower storage cost.
+- We vary the numbers of copies for different data partitions. For example, we
set three copies for data of the recent three months, which is used frequently,
one copy for data older than six months, and two copies for data in between.
+- Doris supports turning hot data into cold data so we only store data of the
past seven days in SSD and transfer data older than that to HDD for less
expensive storage.
+
+# Conclusion
+
+Thank you for scrolling all the way down here and finishing this long read.
We’ve shared our cheers and tears, lessons learned, and a few practices that
might be of some value to you during our transition from ClickHouse to Doris.
We really appreciate the help from the Apache Doris community and the
[SelectDB](https://selectdb.com) team, but we might still be chasing them
around for a while since we attempt to realize auto-identification of cold and
hot data, pre-computation of frequentl [...]
+
+
+
+**# Links**
+
+**SelectDB**:
+
+https://selectdb.com
+
+**Apache Doris**:
+
+http://doris.apache.org
+
+**Apache Doris Github**:
+
+https://github.com/apache/doris
diff --git "a/i18n/zh-CN/docusaurus-plugin-content-blog/\344\273\216 ClickHouse
\345\210\260 Apache
Doris\357\274\214\350\205\276\350\256\257\351\237\263\344\271\220\345\206\205\345\256\271\345\272\223\346\225\260\346\215\256\345\271\263\345\217\260\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\350\267\265.md"
"b/i18n/zh-CN/docusaurus-plugin-content-blog/\344\273\216 ClickHouse
\345\210\260 Apache
Doris\357\274\214\350\205\276\350\256\257\351\237\263\344\271\220\345\206\205\
[...]
new file mode 100644
index 00000000000..9a4ebac2d19
--- /dev/null
+++ "b/i18n/zh-CN/docusaurus-plugin-content-blog/\344\273\216 ClickHouse
\345\210\260 Apache
Doris\357\274\214\350\205\276\350\256\257\351\237\263\344\271\220\345\206\205\345\256\271\345\272\223\346\225\260\346\215\256\345\271\263\345\217\260\346\236\266\346\236\204\346\274\224\350\277\233\345\256\236\350\267\265.md"
@@ -0,0 +1,312 @@
+---
+{
+ 'title': '从 ClickHouse 到 Apache Doris,腾讯音乐内容库数据平台架构演进实践',
+ 'summary':
"腾讯音乐内容库数据平台旨在为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务,高效为业务赋能。目前,内容库数据平台的数据架构已经从 1.0
演进到了 4.0 ,经历了分析引擎从 ClickHouse 到 [Apache Doris](https://github.com/apache/doris)
的替换、经历了数据架构语义层的初步引入到深度应用,有效提高了数据时效性、降低了运维成本、解决了数据管理割裂等问题,收益显著。本文将为大家分享腾讯音乐内容库数据平台的数据架构演进历程与实践思考,希望所有读者从文章中有所启发。",
+ 'date': '2023-03-07',
+ 'author': '张俊 & 代凯',
+ 'tags': ['最佳实践'],
+}
+---
+
+
+---
+
+<!--
+Licensed to the Apache Software Foundation (ASF) under one
+or more contributor license agreements. See the NOTICE file
+distributed with this work for additional information
+regarding copyright ownership. The ASF licenses this file
+to you under the Apache License, Version 2.0 (the
+"License"); you may not use this file except in compliance
+with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing,
+software distributed under the License is distributed on an
+"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+KIND, either express or implied. See the License for the
+specific language governing permissions and limitations
+under the License.
+-->
+
+
+
+作者:腾讯音乐内容库数据平台 张俊、代凯
+
+腾讯音乐娱乐集团(简称“腾讯音乐娱乐”)是中国在线音乐娱乐服务开拓者,提供在线音乐和以音乐为核心的社交娱乐两大服务。腾讯音乐娱乐在中国有着广泛的用户基础,拥有目前国内市场知名的四大移动音乐产品:QQ音乐、酷狗音乐、酷我音乐和全民K歌,总月活用户数超过8亿。
+
+
+
+# 业务需求
+
+腾讯音乐娱乐拥有海量的内容曲库,包括录制音乐、现场音乐、音频和视频等多种形式。通过技术和数据的赋能,腾讯音乐娱乐持续创新产品,为用户带来更好的产品体验,提高用户参与度,也为音乐人和合作伙伴在音乐的制作、发行和销售方面提供更大的支持。
+
+在业务运营过程中我们需要对包括歌曲、词曲、专辑、艺人在内的内容对象进行全方位分析,高效为业务赋能,**内容库数据平台旨在集成各数据源的数据,整合形成内容数据资产(以指标和标签体系为载体),为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务。**
+
+
+
+# 数据架构演进
+
+TDW
是腾讯最大的离线数据处理平台,公司内大多数业务的产品报表、运营分析、数据挖掘等的存储和计算都是在TDW中进行,内容库数据平台的数据加工链路同样是在腾讯数据仓库
TDW 上构建的。截止目前,内容库数据平台的数据架构已经从 1.0 演进到了 4.0 ,**经历了分析引擎从 ClickHouse 到 Apache
Doris
的替换、经历了数据架构语义层的初步引入到深度应用**,有效提高了数据时效性、降低了运维成本、解决了数据管理割裂等问题,收益显著。接下来将为大家分享腾讯音乐内容库数据平台的数据架构演进历程与实践思考。
+
+## 数据架构 1.0
+
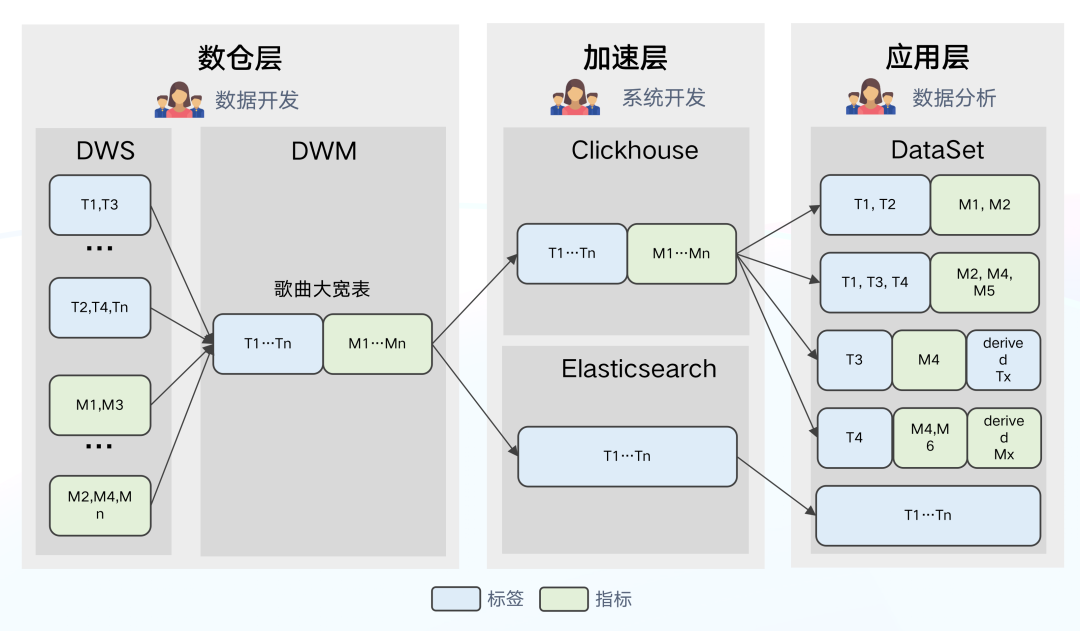
+
+
+如图所示为数据架构 1.0 架构图,分为数仓层、加速层、应用层三部分,数据架构 1.0 是一个相对主流的架构,简单介绍一下各层的作用及工作原理:
+
+- 数仓层:通过 ODS-DWD-DWS 三层将数据整合为不同主题的标签和指标体系, DWM 集市层围绕内容对象构建大宽表,从不同主题域 DWS
表中抽取字段。
+- 加速层:在数仓中构建的大宽表导入到加速层中,Clickhouse 作为分析引擎,Elasticsearch 作为搜索/圈选引擎。
+- 应用层:根据场景创建 DataSet,作为逻辑视图从大宽表选取所需的标签与指标,同时可以二次定义衍生的标签与指标。
+
+**存在的问题:**
+
+- 数仓层:不支持部分列更新,当上游任一来源表产生延迟,均会造成大宽表延迟,进而导致数据时效性下降。
+- 加速层:不同的标签跟指标特性不同、更新频率也各不相同。由于 ClickHouse
目前更擅长处理宽表场景,无区别将所有数据导入大宽表生成天的分区将造成存储资源的浪费,维护成本也将随之升高。
+- 应用层:ClickHouse
采用的是计算和存储节点强耦合的架构,架构复杂,组件依赖严重,牵一发而动全身,容易出现集群稳定性问题,对于我们来说,同时维护 ClickHouse 和
Elasticsearch 两套引擎的连接与查询,成本和难度都比较高。
+
+除此之外,ClickHouse
由国外开源,交流具有一定的语言学习成本,遇到问题无法准确反馈、无法快速获得解决,与社区沟通上的阻塞也是促进我们进行架构升级的因素之一。
+
+
+## 数据架构 2.0
+
+
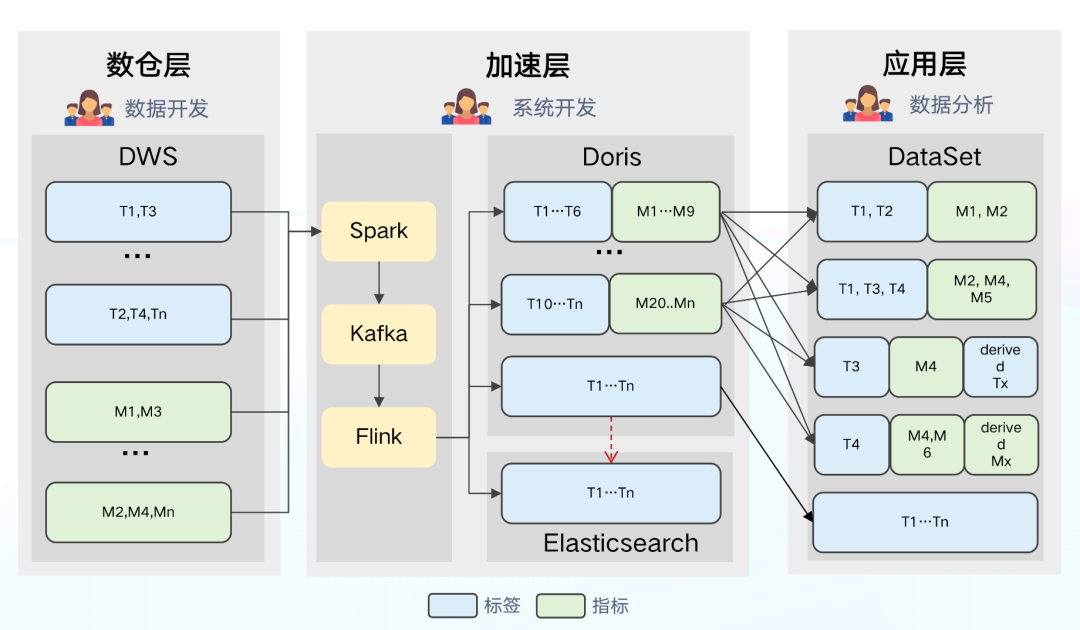
+
+
+
+基于架构 1.0 存在的问题和 ClickHouse 的局限性,我们尝试对架构进行优化升级,**将分析引擎 ClickHouse 切换为
Doris**,Doris 具有以下的优势:
+
+**Apache Doris 的优势:**
+
+- Doris 架构极简易用,部署只需两个进程,不依赖其他系统,运维简单;兼容 MySQL 协议,并且使用标准 SQL。
+- 支持丰富的数据模型,可满足多种数据更新方式,支持部分列更新。
+- 支持对 Hive、Iceberg、Hudi 等数据湖和 MySQL、Elasticsearch 等数据库的联邦查询分析。
+- 导入方式多样,支持从 HDFS/S3 等远端存储批量导入,也支持读取 MySQL Binlog 以及订阅消息队列 Kafka 中的数据,还可以通过
Flink Connector 实时/批次同步数据源(MySQL,Oracle,PostgreSQL 等)到 Doris。
+- 社区目前 Apache Doris 社区活跃、技术交流更多,SelectDB 针对社区有专职的技术支持团队,在使用过程中遇到问题均能快速得到响应解决。
+
+**同时我们也利用 Doris 的特性,解决了架构 1.0 中较为突出的问题。**
+
+- 数仓层:Apache Doris 的 Aggregate 数据模型可支持部分列实时更新,因此我们去掉了 DWM 集市层的构建,直接增量到 Doris
/ ES 中构建宽表,**解决了架构 1.0 中上游数据更新延迟导致整个宽表延迟的问题,进而提升了数据的时效性**。数据(指标、标签等)通过 Spark
统一离线加载到 Kafka 中,使用 Flink 将数据增量更新到 Doris 和 ES 中(利用 Flink 实现进一步的聚合,减轻了 Doris 和 ES
的更新压力)。
+- 加速层:该层主要将大宽表拆为小宽表,根据更新频率配置不同的分区策略,减小数据冗余带来的存储压力,提高查询吞吐量。**Doris
具备多表查询和联邦查询性能特性,可以利用多表关联特性实现组合查询。**
+- 应用层:DataSet 统一指向 Doris,**Doris 支持外表查询**,利用该特性可对 ES 引擎直接查询。
+
+**架构 2.0 存在的问题:**
+
+- DataSet
灵活度较高,数据分析师可对指标和标签自由组合和定义,但是不同的分析师对同一数据的定义不尽相同、定义口径不一致,导致指标和标签缺乏统一管理,这使得数据管理和使用的难度都变高。
+- Dataset 与物理位置绑定,应用层无法进行透明优化,如果 Doris 引擎出现负载较高的情况,无法通过降低用户查询避免集群负载过高报错的问题。
+
+## 数据架构 3.0
+
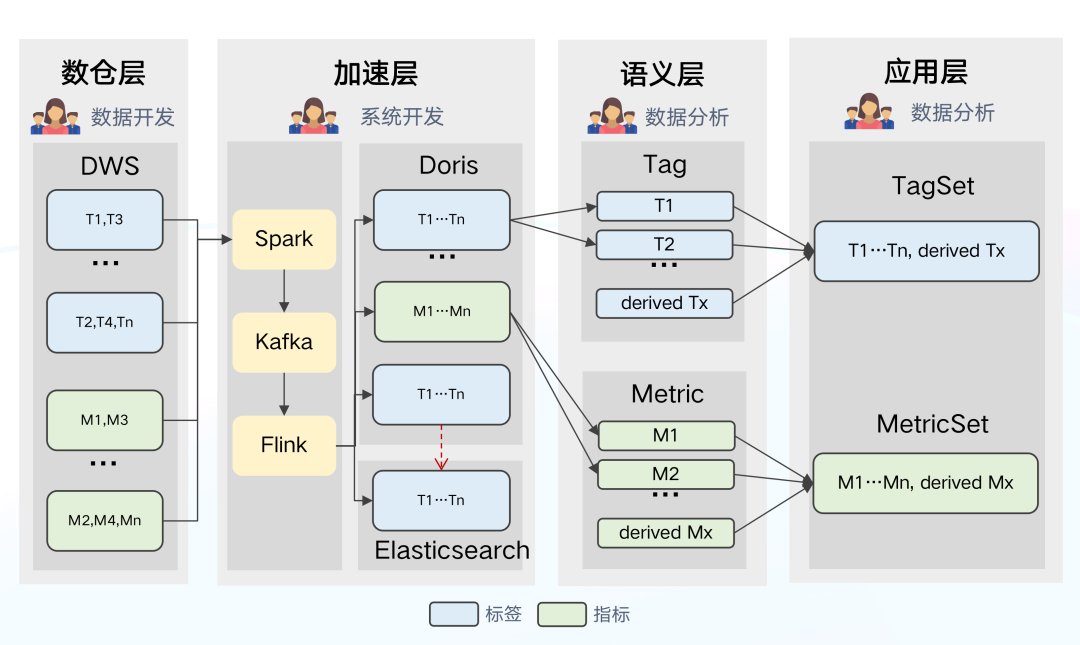
+针对指标和标签定义口径不统一,数据使用和管理难度较高的问题,我们继续对架构进行升级。数据架构 3.0
主要的变化是引入了专门的语义层,语义层的主要作用是将技术语言转换为业务部门更容易理解的概念,目的是将标签
(tag)与指标(metric)变为“一等公民”,作为数据定义与管理的基本对象。
+
+
+
+**引入语义层的优势有:**
+
+- 对于技术来说,应用层不再需要创建 DataSet,从语义层可直接获取特定内容对象的标签集 (tagset)和指标集(metricset) 来发起查询。
+- 对于数据分析师来说,可统一在语义层定义和创建衍生的指标和标签,解决了定义口径不一致、管理和使用难度较高的问题。
+- 对于业务来说,无需耗费过长时间考虑什么场景应选择哪个数据集使用,语义层对标签和指标透明统一的定义提升了工作效率、降低了使用成本。
+
+**存在的问题:**
+
+从架构图可知,标签和指标等数据均处于下游位置,虽然标签与指标在语义层被显式定义,但仍然无法影响上游链路,数仓层有自己的语义逻辑,加速层有自己的导入配置,**这样就造成了数据管理机制的割裂**。
+
+## 数据架构 4.0
+
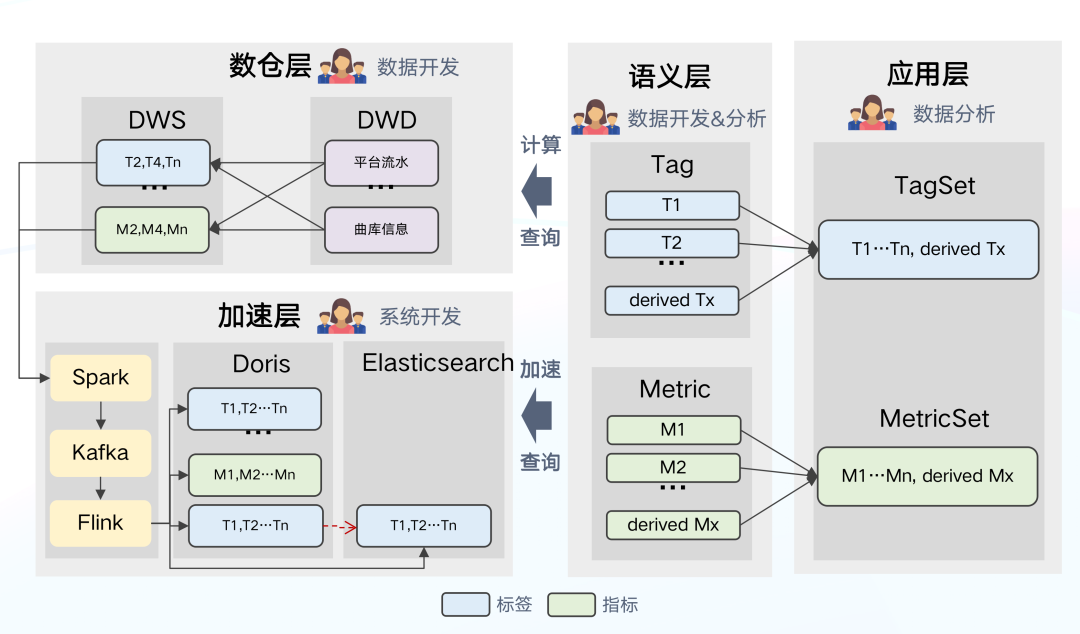
+在数据架构 3.0 的基础上,我们对语义层进行更深层次的应用,在数据架构 4.0
中,我们将语义层变为架构的中枢节点,目标是对所有的指标和标签统一定义,从计算-加速-查询实现中心化、标准化管理,解决数据管理机制割裂的问题。
+
+
+
+语义层作为架构中枢节点所带来的变化:
+
+- 数仓层:语义层接收 SQL 触发计算或查询任务。数仓从 DWD 到 DWS
的计算逻辑将在语义层中进行定义,且以单个指标和标签的形式进行定义,之后由语义层来发送命令,生成 SQL 命令给数仓层执行计算。
+- 加速层:从语义层接收配置、触发导入任务,比如加速哪些指标与标签均由语义层指导。
+- 应用层:向语义层发起逻辑查询,由语义层选择引擎,生成物理 SQL。
+
+**架构优势:**
+
+- 可以形成统一视图,对于核心指标和标签的定义进行统一查看及管理。
+- 应用层与物理引擎完成解耦,可进一步对更加灵活易用的架构进行探索:如何对相关指标和标签进行加速,如何在时效性和集群的稳定性之间平衡等。
+
+**存在的问题:**
+
+因为当前架构是对单个标签和指标进行了定义,因此如何在查询计算时自动生成一个准确有效的 SQL
语句是非常有难度的。如果你有相关的经验,期待有机会可以一起探索交流。
+
+
+# 优化经验
+
+从上文已知,为更好地实现业务需求,数据架构演进到 4.0 版本,其中 **Apache Doris
作为分析加速场景的解决方案在整个系统中发挥着重要的作用**。接下来将从场景需求、数据导入、查询优化以及成本优化四个方面出发,分享基于 Doris
的读写优化经验,希望给读者带来一些参考。
+
+## 场景需求
+
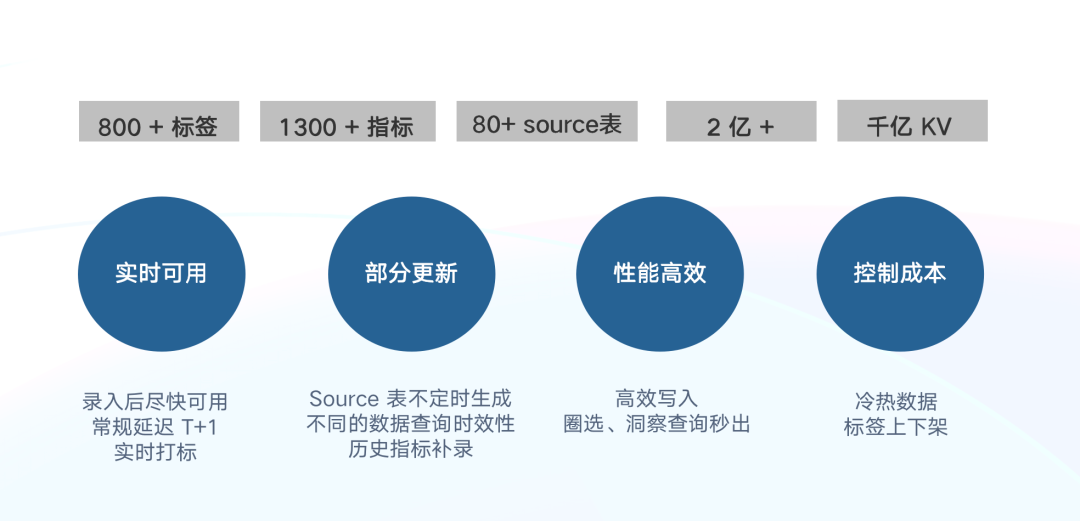
+
+
+目前我们有 800+ 标签, 1300+ 指标,对应 TDW 中有 80 + Source 表,单个标签、指标的最大基数达到了 2
亿+。我们希望将这些数据从 TDW 加速到 Doris 中完成标签画像和指标的分析。**从业务的角度,需要满足以下要求:**
+
+- **实时可用**:标签/指标导入以后,需实现数据尽快可用。不仅要支持常规离线导入 T+1 ,同时也要支持实时打标场景。
+- **部分更新**:因每个 Source 表由各自 ETL
任务产出对应的数据,其产出时间不一致,并且每个表只涉及部分指标或标签,不同数据查询对时效性要求也不同,因此架构需要支持部分列更新。
+- **性能高效**:具备高效的写入能力,且在圈选、洞察、报表等场景可以实现秒级响应。
+- **控制成本**:在满足业务需求的前提下,最大程度地降低成本;支持冷热数据精细化管理,支持标签灵活上下架。
+
+## 数据导入方案
+
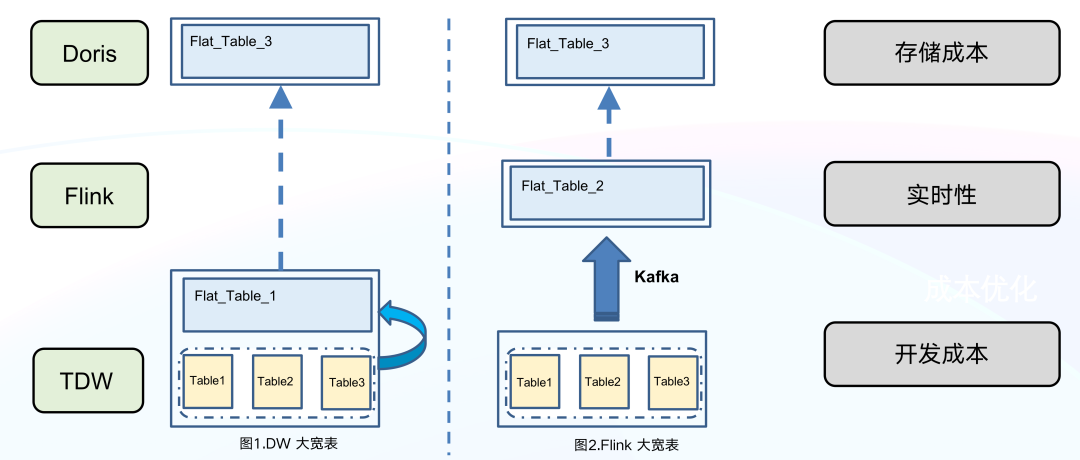
+
+
+为了减轻 Doris 写入压力,我们考虑在数据写入 Doris 之前,尽量将数据生成宽表,再写入到 Doris
中。**针对宽表的生成,我们有两个实现思路**:第一个是在 TDW 数仓中生成宽表;第二个是 Flink
中生成宽表。我们对这两个实现思路进行了实践对比,最终决定选择第二个实现思路,原因如下:
+
+在 TDW 中生成宽表,虽然链路简单,但是弊端也比较明显。
+
+- 存储成本较高, TDW 除了要维护离散的 80 +个 Source 表外,还需维护 1 个大宽表、2 份冗余的数据。
+- 实时性比较差,由于每个 Source 表产出的时间不一样,往往会因为某些延迟比较大的 Source 表导致整个数据链路延迟增大。
+- 开发成本较高,该方案只能作为离线方式,若想实现实时方式则需要投入开发资源进行额外的开发。
+
+而**在 Flink 中生成宽表,链路简单、成本低也容易实现**,主要流程是:首先用 Spark 将相关 Source 表最新数据离线导入到 Kafka
中, 接着使用 Flink 来消费 Kafka,并通过主键 ID 构建出一张大宽表,最后将大宽表导入到 Doris 中。如下图所示,来自数仓 N 个表中
ID=1 的 5 条数据,经过 Flink 处理以后,只有一条 ID=1 的数据写入 Doris 中,大大减少 Doris 写入压力。
+
+
+
+通过以上导入优化方案,**极大地降低了存储成本**, TDW 无需维护两份冗余的数据,Kafka
也只需保存最新待导入的数据。同时该方案**整体实时性更好且可控**,并且大宽表聚合在 Flink 中执行,可灵活加入各种 ETL
逻辑,离线和实时可对多个开发逻辑进行复用,**灵活度较高**。
+
+### **数据模型选择**
+
+目前我们生产环境所使用的版本为 Apache Doris 1.1.3,我们对其所支持的 Unique 主键模型、Aggregate 聚合模型和
Duplicate 明细模型进行了对比 ,相较于 Unique 模型和 Duplicate 模型,**Aggregate
聚合模型满足我们部分列更新的场景需求**:
+
+Aggregate 聚合模型可以支持多种预聚合模式,可以通过`REPLACE_IF_NOT_NULL`的方式实现部分列更新。数据写入过程中,Doris
会将多次写入的数据进行聚合,最终用户查询时,返回一份聚合后的完整且正确的数据。
+
+另外两种数据模型适用的场景,这里也进行简单的介绍:
+
+- Unique 模型适用于需要保证 Key 唯一性场景,同一个主键 ID 多次导入之后,会以 append
的方式进行行级数据更新,仅保留最后一次导入的数据。在与社区进行沟通后,确定**后续版本 Unique 模型也将支持部分列更新**。
+- Duplicate 模型区别于 Aggregate 和 Unique
模型,数据完全按照导入的明细数据进行存储,不会有任何预聚合或去重操作,即使两行数据完全相同也都会保留,因此 Duplicate
模型适用于既没有聚合需求,又没有主键唯一性约束的原始数据存储。
+
+确定数据模型之后,我们在建表时如何对列进行命名呢?可以直接使用指标或者是标签的名称吗?
+
+在使用场景中通常会有以下几个需求:
+
+- 为了更好地表达数据的意义,业务方会有少量修改标签、指标名称的需求。
+- 随着业务需求的变动,标签经常存在上架、下架的情况。
+- 实时新增的标签和指标,用户希望数据尽快可用。
+
+Doris 1.1.3 是不支持对列名进行修改的,如果直接使用指标/标签名称作为列名,则无法满足上述标签或指标更名的需求。而对于上下架标签的需求,如果直接以
drop/add column 的方式实现,则会涉及数据文件的更改,该操作耗时耗力,甚至会影响线上查询的性能。
+
+那么,有没有更轻量级的方式来满足需求呢?接下来将为大家分享相关解决方案及收益:****
+
+- **为了实现少量标签、指标名称修改**,我们用 MySQL 表存储相应的元数据,包括名称、全局唯一的 ID
和上下架状态等信息,比如标签歌曲名称`song_name`的 ID 为 4,在 Doris 中存储命名为
a4,用户使用更具有业务含义`song_name`进行查询。在查询 Doris 前,我们会在查询层将 SQL 改写成具体的列名
a4。这样名称的修改只是修改其元数据,底层 Doris 的表结构可以保持不变。
+-
**为了实现标签灵活上下架**,我们通过统计标签的使用情况来分析标签的价值,将低价值的标签进入下架流程。下架指的是对元信息进行状态标注,在下架标签重新上架之前,不会继续导入其数据,元信息中数据可用时间也不会发生变化。
+- **对于实时新增标签/指标**,我们基于名称 ID 的映射在 Doris 表中预先创建适量 ID 列,当标签/指标完成元信息录入后,直接将预留的
ID 分配给新录入的标签/指标,避免在查询高峰期因新增标签/指标所引起的 Schema Change 开销对集群产生的影响。经测试,用户在元信息录入后 10
分钟内就可以使用相应的数据。
+
+值得关注的是,**在社区近期发布的 1.2.0 版本中,增加了 Light Schema Change 功能,
对于增减列的操作不需要修改数据文件,只需要修改 FE 中的元数据,从而可以实现毫秒级的 Schame Change 操作**。同时开启 Light
Schema Change 功能的数据表也可以支持列名的修改,这与我们的需求十分匹配,后续我们也会及时升级到最新版本。
+
+### **写入优化**
+
+接着我们在数据写入方面也进行了调整优化,这里几点小经验与大家分享:
+
+- Flink 预聚合:通过主键 ID 预聚合,减少写入压力。(前文已说明,此处不再赘述)
+- 写入 Batch 大小自适应变更:为了不占用过多 Flink 资源,我们实现了从同一个 Kafka Topic 中消费数据写入到不同 Doris
表中的功能,并且可以根据数据的大小自动调整写入的批次,尽量做到攒批低频写入。
+- Doris 写入调优:针对- 235 报错进行相关参数的调优。比如设置合理的分区和分桶(Tablet 建议1-10G),同时结合场景对
Compaction 参数调优:
+
+```
+max_XXXX_compaction_thread
+max_cumulative_compaction_num_singleton_deltas
+```
+
+- 优化 BE 提交逻辑:定期缓存 BE 列表,按批次随机提交到 BE 节点,细化负载均衡粒度。
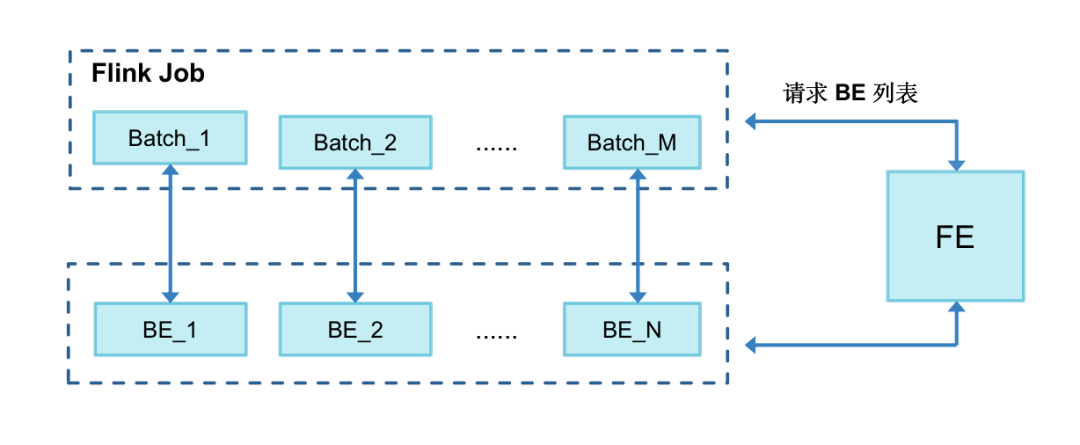
+
+> 优化背景:在写入时发现某一个 BE负载会远远高于其他的 BE,甚至出现 OOM。结合源码发现:作业启动后会获取一次 BE 地址列表,从中随机选出一个
BE 作为 Coordinator 协调者,该节点主要负责接收数据、并分发到其他的 BE 节点,除非作业异常报错,否则该节点不会发生切换。
+>
+> 对于少量 Flink 作业大数据场景会导致选中的 BE 节点负载较高,因此我们尝试对 BE 提交逻辑进行优化,设置每 1 小时缓存一次 BE
列表,每写入一个批次都随机从 BE 缓存列表中获取一个进行提交,这样负载均衡的粒度就从 job 级别细化到每次提交的批次,使得 BE
间负载更加的均衡,这部分实现我们已经贡献到社区,欢迎大家一起使用并反馈。
+>
+> - https://github.com/apache/doris-spark-connector/pull/59
+> - https://github.com/apache/doris-spark-connector/pull/60
+> - https://github.com/apache/doris-spark-connector/pull/61
+
+
+
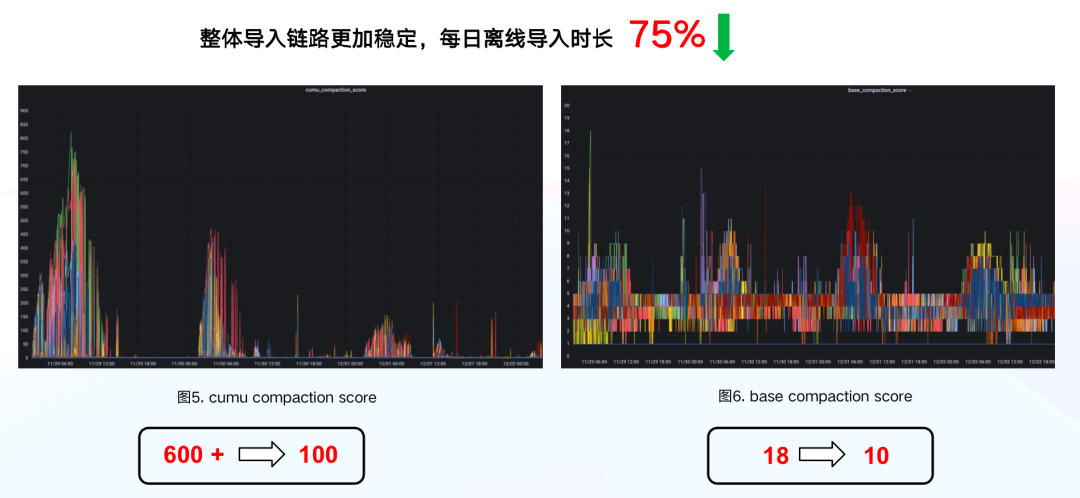
+通过以上数据导入的优化措施,使得整体导入链路更加稳定,每日离线**导入时长下降了 75%** ,数据版本累积情况也有所改善,其中 cumu
compaction 的**合并分数更是从 600+直降到 100 左右**,优化效果十分明显。
+
+
+
+## 查询优化
+
+目前我们的场景指标数据是以分区表的形式存储在 Doris 中, ES 保留一份全量的标签数据。在我们的使用场景中,标签圈选的使用率很高,大约有 60%
的使用场景中用到了标签圈选,在标签圈选场景中,通常需要满足以下几个要求:
+
+- 用户圈选逻辑比较复杂,数据架构需要支持同时有上百个标签做圈选过滤条件。
+- 大部分圈选场景只需要最新标签数据,但是在指标查询时需要支持历史的数据的查询。
+- 基于圈选结果,需要进行指标数据的聚合分析。
+- 基于圈选结果,需要支持标签和指标的明细查询。
+
+经过调研,我们最终采用了 **Doris on ES 的解决方案**来实现以上要求,将 Doris 的分布式查询规划能力和 ES
的全文检索能力相结合。Doris on ES 主要查询模式如下所示:
+
+```
+SELECT tag, agg(metric)
+ FROM Doris
+ WHERE id in (select id from Es where tagFilter)
+ GROUP BY tag
+```
+
+在 ES 中圈选查询出的 ID 数据,以子查询方式在 Doris 中进行指标分析。
+
+我们在实践中发现,查询时长跟圈选的群体大小相关。如果从 ES 中圈选的群体规模超过 100 万时,查询时长会达到 60
秒,圈选群体再次增大甚至会出现超时报错。经排查分析,主要的耗时包括两方面:
+
+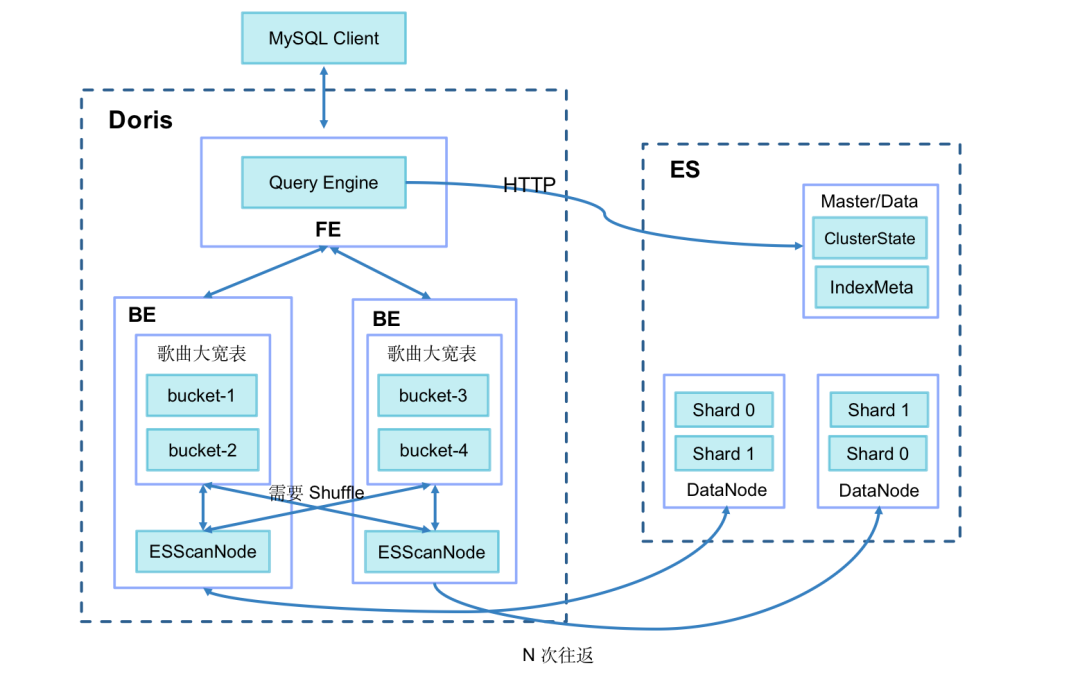
+
+- BE 从 ES 中拉取数据(默认一次拉取 1024 行),对于 100 万以上的群体,网络 IO 开销会很大。
+- BE 数据拉取完成以后,需要和本地的指标表做 Join,一般以 SHUFFLE/BROADCAST 的方式,成本较高。
+
+**针对这两点,我们进行了以下优化:**
+
+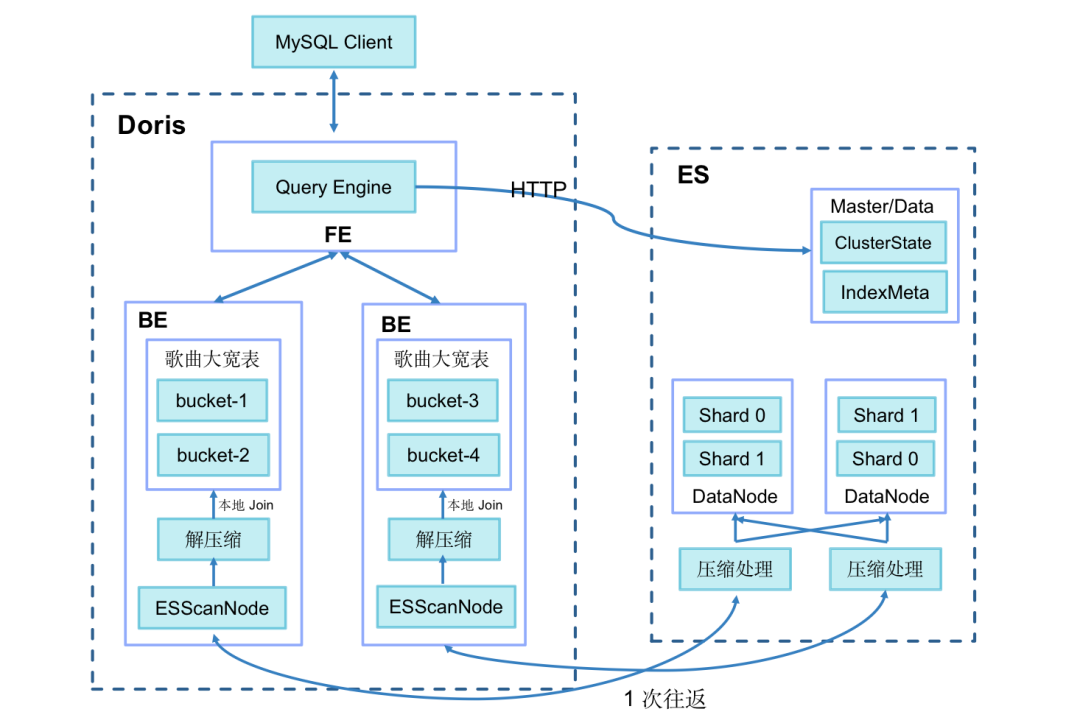
+
+- 增加了查询会话变量`es_optimize`,以开启优化开关;
+- 数据写入 ES 时,新增 BK 列用来存储主键 ID Hash 后的分桶序号,算法和 Doris 的分桶算法相同(CRC32);
+- BE 生成 Bucket Join 执行计划,将分桶序号下发到 BE ScanNode 节点,并下推到 ES;
+- ES 对查询出的数据进行 Bitmap 压缩,并将数据的多批次获取优化为一次获取,减少网络 IO 开销;
+- Doris BE 只拉取和本地 Doris 指标表相关 Bucket 的数据,直接进行本地 Join,避免 Doris BE 间数据再
Shuffle 的过程。
+
+通过以上优化措施,**百万分群圈选洞察查询时间从最初的 60 秒缩短到 3.7 秒**,性能显著提升!
+
+经过与社区沟通交流,**Apache Doris 从 2.0.0
版本开始,将支持倒排索引**。可进行文本类型的全文检索;支持中文、英文分词;支持文本、数值日期类型的等值和范围过滤;倒排索引对数组类型也提供了支持,多个过滤条件可以任意进行
AND OR NOT 逻辑组合。由于高性能的向量化实现和面向 AP 数据库的精简优化,**Doris 的倒排索引相较于 ES 会有 3~5
倍性价比提升**,即将在 2 月底发布的 2.0 preview 版本中可用于功能评估和性能测试,相信在这个场景使用后会有进一步的性能提升。
+
+## 成本优化
+
+在当前大环境下,降本提效成为了企业的热门话题,**如何在保证服务质量的同时降低成本开销**,是我们一直在思考的问题。在我们的场景中,**成本优化主要得益于
Doris 自身优秀的能力**,这里为大家分享两点:
+
+**1、冷热数据进行精细化管理。**
+
+- 利用 Doris TTL 机制,在 Doris 中只存储近一年的数据,更早的数据放到存储代价更低的 TDW 中;
+- 支持分区级副本设置,3 个月以内的数据高频使用,分区设置为 3 副本 ;3-6 个月数据分区调整为 2 副本;6 个月之前的数据分区调整为1 副本;
+- 支持数据转冷, 在 SSD 中仅存储最近 7 天的数据,并将 7 天之前的数据转存到到 HDD 中,以降低存储成本;
+- 标签上下线,将低价值标签和指标下线处理后,后续数据不再写入,减少写入和存储代价。
+
+**2、降低数据链路成本。**
+
+Doris 架构非常简单,只有FE 和 BE 两类进程,不依赖其他组件,并通过一致性协议来保证服务的高可用和数据的高可靠,自动故障修复,运维起来比较容易;
+
+- 高度兼容 MySQL 语法,支持标准 SQL,极大降低开发人员接入使用成本;
+- 支持多种联邦查询方式,支持对 Hive、MySQL、Elasticsearch 、Iceberg 等组件的联邦查询分析,降低多数据源查询复杂度。
+
+通过以上的方式,**使得存储成本降低 42%,开发与时间成本降低了 40%** ,成功实现降本提效,后续我们将继续探索!
+
+
+# 未来规划
+
+未来我们还将继续进行迭代和优化,我们计划在以下几个方向进行探索:
+
+- 实现自动识别冷热数据,用 Apache Doris 存储热数据,Iceberg 存储冷数据,利用 Doris 湖仓一体化能力简化查询。
+- 对高频出现的标签/指标组合,通过 Doris 的物化视图进行预计算,提升查询的性能。
+- 探索 Doris 应用于数仓计算任务,利用物化视图简化代码逻辑,并提升核心数据的时效性。
+
+最后,感谢 Apache Doris 社区和 [SelectDB](https://selectdb.com)
的同学,感谢其快速响应和积极支持,未来我们也会持续将相关成果贡献到社区,希望 Apache Doris 飞速发展,越来越好!
+
+**# 相关链接:**
+
+**SelectDB 官网**:
+
+https://selectdb.com
+
+**Apache Doris 官网**:
+
+http://doris.apache.org
+
+**Apache Doris Github**:
+
+https://github.com/apache/doris
diff --git a/static/images/TME/TME.png b/static/images/TME/TME.png
new file mode 100644
index 00000000000..fb914354e1a
Binary files /dev/null and b/static/images/TME/TME.png differ
diff --git a/static/images/TME/TME_1.png b/static/images/TME/TME_1.png
new file mode 100644
index 00000000000..421659387cf
Binary files /dev/null and b/static/images/TME/TME_1.png differ
diff --git a/static/images/TME/TME_10.png b/static/images/TME/TME_10.png
new file mode 100644
index 00000000000..3c5e72e0a72
Binary files /dev/null and b/static/images/TME/TME_10.png differ
diff --git a/static/images/TME/TME_11.png b/static/images/TME/TME_11.png
new file mode 100644
index 00000000000..1d1725a2de1
Binary files /dev/null and b/static/images/TME/TME_11.png differ
diff --git a/static/images/TME/TME_2.png b/static/images/TME/TME_2.png
new file mode 100644
index 00000000000..78e8b561330
Binary files /dev/null and b/static/images/TME/TME_2.png differ
diff --git a/static/images/TME/TME_3.png b/static/images/TME/TME_3.png
new file mode 100644
index 00000000000..d7c6efa4cc1
Binary files /dev/null and b/static/images/TME/TME_3.png differ
diff --git a/static/images/TME/TME_4.png b/static/images/TME/TME_4.png
new file mode 100644
index 00000000000..7e5a6a78404
Binary files /dev/null and b/static/images/TME/TME_4.png differ
diff --git a/static/images/TME/TME_5.png b/static/images/TME/TME_5.png
new file mode 100644
index 00000000000..ef83b930cfc
Binary files /dev/null and b/static/images/TME/TME_5.png differ
diff --git a/static/images/TME/TME_6.png b/static/images/TME/TME_6.png
new file mode 100644
index 00000000000..0b59f8d8ae2
Binary files /dev/null and b/static/images/TME/TME_6.png differ
diff --git a/static/images/TME/TME_7.png b/static/images/TME/TME_7.png
new file mode 100644
index 00000000000..f28e7fea88e
Binary files /dev/null and b/static/images/TME/TME_7.png differ
diff --git a/static/images/TME/TME_8.png b/static/images/TME/TME_8.png
new file mode 100644
index 00000000000..4488813656d
Binary files /dev/null and b/static/images/TME/TME_8.png differ
diff --git a/static/images/TME/TME_9.png b/static/images/TME/TME_9.png
new file mode 100644
index 00000000000..faeb65adb18
Binary files /dev/null and b/static/images/TME/TME_9.png differ
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]