BePPPower opened a new issue, #17974: URL: https://github.com/apache/doris/issues/17974
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/doris/issues?q=is%3Aissue) and found no similar issues. ### Description This is a tutorial on how to add a new Metadata TVF. This tutorial takes `backends` TVF as an example. The implemention of `backends` TVF is in pr #17667. # Concepts 1. What is table-valued-function(tvf)? #10217 2. What is Metadata tvf? As mentioned above, a TVF is a function that can be used in the 'from' clause. A Metadata TVF is a TVF that BE needs to get data from FE. # Introduction The sql `show backends` can return the information of backends in the cluster. Now we need implement a TVF called `backend()` which can return the same result as sql `show backends`. Because `show` statements can not be used with `where` or `join` clauses, we can use `backends` TVF for analysis. The result of `show backends` : ```sql mysql> show backends\G *************************** 1. row *************************** BackendId: 10003 Cluster: default_cluster IP: 172.21.0.101 HeartbeatPort: 9159 BePort: 9169 HttpPort: 8149 BrpcPort: 8169 LastStartTime: 2023-03-09 11:21:16 LastHeartbeat: 2023-03-09 11:34:04 Alive: true SystemDecommissioned: false ClusterDecommissioned: false TabletNum: 21 DataUsedCapacity: 0.000 AvailCapacity: 193.080 GB TotalCapacity: 502.964 GB UsedPct: 61.61 % MaxDiskUsedPct: 61.61 % RemoteUsedCapacity: 0.000 Tag: {"location" : "default"} ErrMsg: Version: doris-0.0.0-trunk-dee41d106b Status: {"lastSuccessReportTabletsTime":"2023-03-09 11:33:58","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false} HeartbeatFailureCounter: 0 NodeRole: mix 1 row in set (0.00 sec) ``` We hope `backends` TVF gets the same result. Param is `cluster_name`: ```sql mysql> select * from backends("cluster_name" = "default")\G *************************** 1. row *************************** BackendId: 10003 Cluster: default_cluster IP: 172.21.0.101 HeartbeatPort: 9159 BePort: 9169 HttpPort: 8149 BrpcPort: 8169 LastStartTime: 2023-03-09 11:21:16 LastHeartbeat: 2023-03-09 11:34:04 Alive: true SystemDecommissioned: false ClusterDecommissioned: false TabletNum: 21 DataUsedCapacity: 0.000 AvailCapacity: 193.080 GB TotalCapacity: 502.964 GB UsedPct: 61.61 % MaxDiskUsedPct: 61.61 % RemoteUsedCapacity: 0.000 Tag: {"location" : "default"} ErrMsg: Version: doris-0.0.0-trunk-dee41d106b Status: {"lastSuccessReportTabletsTime":"2023-03-09 11:33:58","lastStreamLoadTime":-1,"isQueryDisabled":false,"isLoadDisabled":false} HeartbeatFailureCounter: 0 NodeRole: mix 1 row in set (0.00 sec) ``` The information of Doris's backends is stored in Fe, but the execution of the `Select` query plan is responsible for BE. So when BE executes the` SELECT * FROM backends` query plan, BE needs to send RPC requests to Fe, request FE to transmit information related to Backends to own. The entire process is as follows: 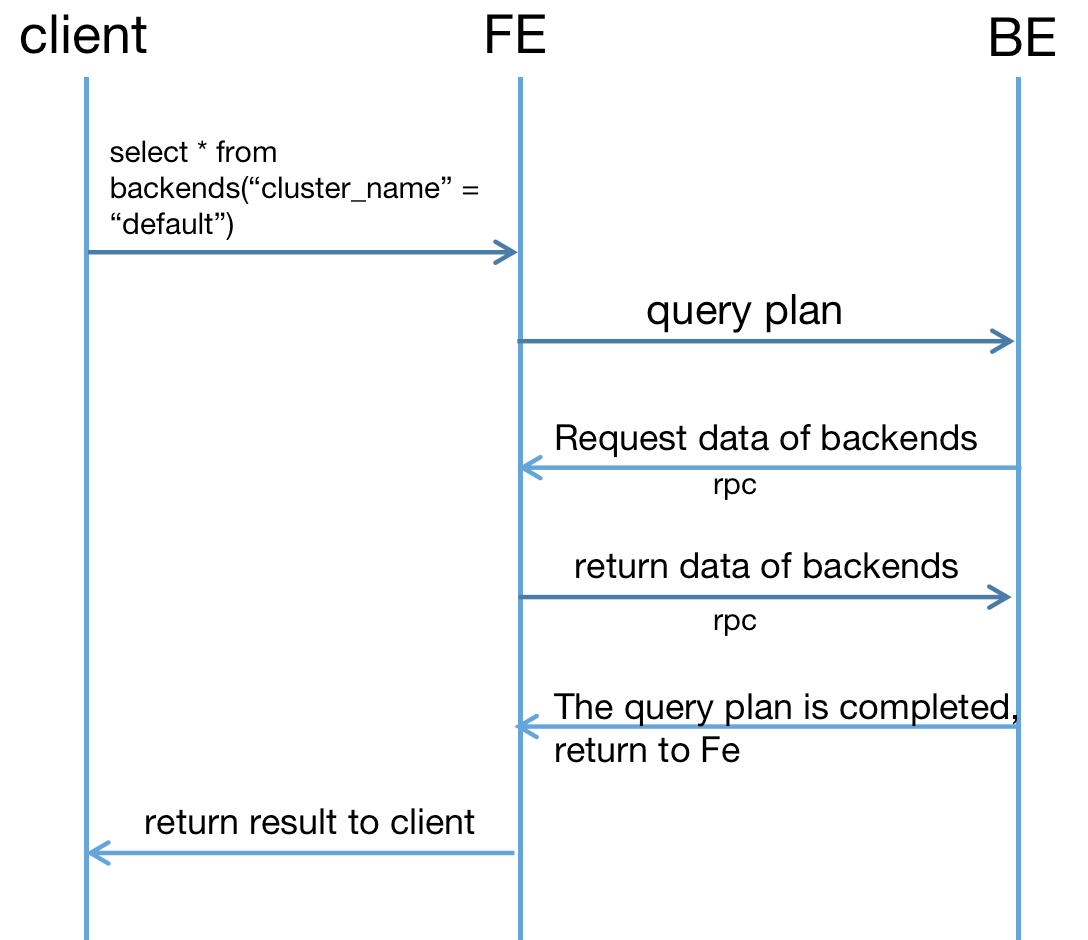 # Steps ## Modify thrift 1. Types.thrift `TMetadataType` add a new type: BACKENDS ``` enum TMetadataType { ICEBERG, BACKENDS } ``` 2. PlanNodes.thrift Add a new thrift struct called `TBackendMetadataParams`, contains a param called `cluster_name`. ``` struct TBackendMetadataParams { 1: optional string cluster_name } ``` Add the structure to `TMetaScanRange`: ``` struct TMetaScanRange { 1: optional Types.TMetadataType metadata_type 2: optional TIcebergMetadataParams iceberg_params 3: optional TBackendMetadataParams backends_params } ``` 3. FrontendService.thrift Add the structure to `TMetadataTableRequestParams`: ``` struct TMetadataTableRequestParams { 1: optional Types.TMetadataType metadata_type 2: optional PlanNodes.TIcebergMetadataParams iceberg_metadata_params 3: optional PlanNodes.TBackendMetadataParams backends_metadata_params } ``` ## FE code 1 Create a new class called `BackendsTableValuedFunction`, extends from `MetadataTableValuedFunction`: ```java public class BackendsTableValuedFunction extends MetadataTableValuedFunction { public BackendsTableValuedFunction(Map<String, String> params) throws AnalysisException { } @Override public TMetadataType getMetadataType() {} @Override public TMetaScanRange getMetaScanRange() {} @Override public String getTableName() {} @Override public List<Column> getTableColumns() throws AnalysisException {} } ``` `BackendsTableValuedFunction` need to implement its own constructor and override the four superclass abstract methods: 1. constructor: The params `Map<String, String>` params are the parameter pairs sent by the client. The parameters can be judged and processed in the constructor. 2. `getMetadataType` Return the `MetadataType` of this TVF. That's the new type in `TMetadataType`. 3. `getTableName` Return the name of this TVF. 4. `getMetaScanRange` Set the parameters of FE brought to BE in `TMetaScanRange`. 5. `getTableColumns` We need to define the column definition of the TVF in this method. After writing `BackendsTableValuedFunction`, register it in `TableValuedFunctionIf`: ```java public static TableValuedFunctionIf getTableFunction(String funcName, Map<String, String> params) throws AnalysisException { switch (funcName.toLowerCase()) { case NumbersTableValuedFunction.NAME: return new NumbersTableValuedFunction(params); case S3TableValuedFunction.NAME: return new S3TableValuedFunction(params); case HdfsTableValuedFunction.NAME: return new HdfsTableValuedFunction(params); case IcebergTableValuedFunction.NAME: return new IcebergTableValuedFunction(params); case BackendsTableValuedFunction.NAME: return new BackendsTableValuedFunction(params); default: throw new AnalysisException("Could not find table function " + funcName); } } ``` ## BE code 1 We need to add the `_build_backends_metadata_request` method in `VMetaScanner` class. This method encapsulates the request sent to Fe. ```c++ // vmeta_scanner.h Status _build_backends_metadata_request(const TMetaScanRange& meta_scan_range, TFetchSchemaTableDataRequest* request); // vmeta_scanner.cpp // Mainly set request parameters Status VMetaScanner::_build_backends_metadata_request(const TMetaScanRange& meta_scan_range, TFetchSchemaTableDataRequest* request) { VLOG_CRITICAL << "VMetaScanner::_build_backends_metadata_request"; if (!meta_scan_range.__isset.backends_params) { return Status::InternalError("Can not find TBackendsMetadataParams from meta_scan_range."); } // create request request->__set_cluster_name(""); request->__set_schema_table_name(TSchemaTableName::METADATA_TABLE); // create TMetadataTableRequestParams TMetadataTableRequestParams metadata_table_params; metadata_table_params.__set_metadata_type(TMetadataType::BACKENDS); metadata_table_params.__set_backends_metadata_params(meta_scan_range.backends_params); request->__set_metada_table_params(metadata_table_params); return Status::OK(); } ``` Register the above method in `_fetch_metadata` method: ```c++ // vmeta_scanner.cpp Status VMetaScanner::_fetch_metadata(const TMetaScanRange& meta_scan_range) { VLOG_CRITICAL << "VMetaScanner::_fetch_metadata"; TFetchSchemaTableDataRequest request; switch (meta_scan_range.metadata_type) { case TMetadataType::ICEBERG: RETURN_IF_ERROR(_build_iceberg_metadata_request(meta_scan_range, &request)); break; case TMetadataType::BACKENDS: RETURN_IF_ERROR(_build_backends_metadata_request(meta_scan_range, &request)); break; default: _meta_eos = true; return Status::OK(); } .... return Status::OK(); } ``` ## FE code 2 After receiving BE's RPC request, the processing entrance is in `MetadataGenerator#getMetadataTable`. We need to implement a method to return the information of backends here. ```java public static TFetchSchemaTableDataResult getMetadataTable(TFetchSchemaTableDataRequest request) { if (!request.isSetMetadaTableParams()) { return errorResult("Metadata table params is not set. "); } switch (request.getMetadaTableParams().getMetadataType()) { case ICEBERG: return icebergMetadataResult(request.getMetadaTableParams()); case BACKENDS: return getBackendsSchemaTable(request); default: break; } return errorResult("Metadata table params is not set. "); } public static TFetchSchemaTableDataResult getBackendsSchemaTable(TFetchSchemaTableDataRequest request) { final SystemInfoService clusterInfoService = Env.getCurrentSystemInfo(); List<Long> backendIds = null; if (!Strings.isNullOrEmpty(request.cluster_name)) { final Cluster cluster = Env.getCurrentEnv().getCluster(request.cluster_name); // root not in any cluster if (null == cluster) { return errorResult("Cluster is not existed."); } backendIds = cluster.getBackendIdList(); } else { backendIds = clusterInfoService.getBackendIds(false); } TFetchSchemaTableDataResult result = new TFetchSchemaTableDataResult(); .... result.setDataBatch(dataBatch); result.setStatus(new TStatus(TStatusCode.OK)); return result; } ``` ## BE code 2 After receiving the data result from Fe, the data will be processed by `_fill_block_with_remote_data` method. You may need to add the corresponding type handling here. ```C++ Status VMetaScanner::_fill_block_with_remote_data(const std::vector<MutableColumnPtr>& columns) { VLOG_CRITICAL << "VMetaScanner::_fill_block_with_remote_data"; for (int col_idx = 0; col_idx < columns.size(); col_idx++) { auto slot_desc = _tuple_desc->slots()[col_idx]; // because the fe planner filter the non_materialize column if (!slot_desc->is_materialized()) { continue; } for (int _row_idx = 0; _row_idx < _batch_data.size(); _row_idx++) { vectorized::IColumn* col_ptr = columns[col_idx].get(); if (slot_desc->is_nullable() == true) { auto* nullable_column = reinterpret_cast<vectorized::ColumnNullable*>(col_ptr); col_ptr = &nullable_column->get_nested_column(); } switch (slot_desc->type().type) { case TYPE_INT: { int64_t data = _batch_data[_row_idx].column_value[col_idx].intVal; reinterpret_cast<vectorized::ColumnVector<vectorized::Int32>*>(col_ptr) ->insert_value(data); break; } case TYPE_BIGINT: { int64_t data = _batch_data[_row_idx].column_value[col_idx].longVal; reinterpret_cast<vectorized::ColumnVector<vectorized::Int64>*>(col_ptr) ->insert_value(data); break; } case TYPE_FLOAT: { double data = _batch_data[_row_idx].column_value[col_idx].doubleVal; reinterpret_cast<vectorized::ColumnVector<vectorized::Float32>*>(col_ptr) ->insert_value(data); break; } case TYPE_DOUBLE: { double data = _batch_data[_row_idx].column_value[col_idx].doubleVal; reinterpret_cast<vectorized::ColumnVector<vectorized::Float64>*>(col_ptr) ->insert_value(data); break; } case TYPE_DATETIMEV2: { uint64_t data = _batch_data[_row_idx].column_value[col_idx].longVal; reinterpret_cast<vectorized::ColumnVector<vectorized::UInt64>*>(col_ptr) ->insert_value(data); break; } case TYPE_STRING: case TYPE_CHAR: case TYPE_VARCHAR: { std::string data = _batch_data[_row_idx].column_value[col_idx].stringVal; reinterpret_cast<vectorized::ColumnString*>(col_ptr)->insert_data(data.c_str(), data.length()); break; } default: { std::string error_msg = fmt::format("Invalid column type {} on column: {}.", slot_desc->type().debug_string(), slot_desc->col_name()); return Status::InternalError(std::string(error_msg)); } } } } _meta_eos = true; return Status::OK(); } ``` ### Solution _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}