This is an automated email from the ASF dual-hosted git repository.
luzhijing pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/doris-website.git
The following commit(s) were added to refs/heads/master by this push:
new 3b0e356a209 [blog]update some picture links (#208)
3b0e356a209 is described below
commit 3b0e356a209b510859bedbc1da6186ab99d81323
Author: Luzhijing <[email protected]>
AuthorDate: Fri Apr 14 17:16:09 2023 +0800
[blog]update some picture links (#208)
---
.../docusaurus-plugin-content-blog/Netease.md | 48 +++++++++-------------
.../zh-CN/docusaurus-plugin-content-blog/summit.md | 4 +-
2 files changed, 21 insertions(+), 31 deletions(-)
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
b/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
index 4f70d1eb1fe..8e21e639a13 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/Netease.md
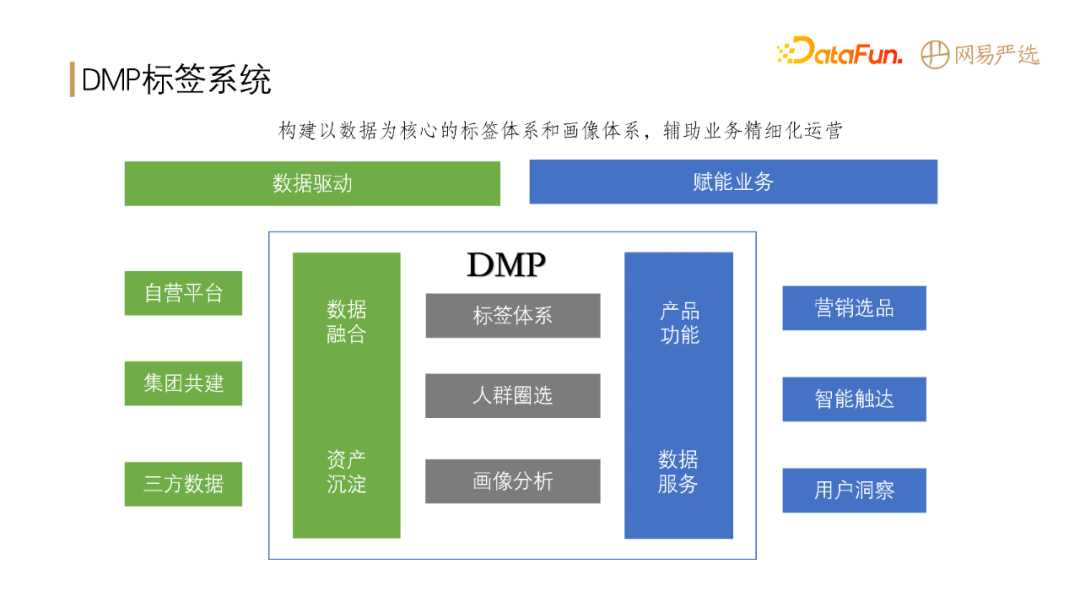
@@ -57,9 +57,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
通过收集、清洗,将以上数据形成数据资产沉淀下来。DMP
在数据资产基础上形成了一套自己的标签产出、人群圈选和用户画像分析体系,从而为业务提供支撑,包括:智能化的选品、精准触达以及用户洞察等。总的来说,**DMP
系统就是构建以数据为核心的标签体系和画像体系,从而辅助业务做一系列精细化的运营。**
-
-
-
+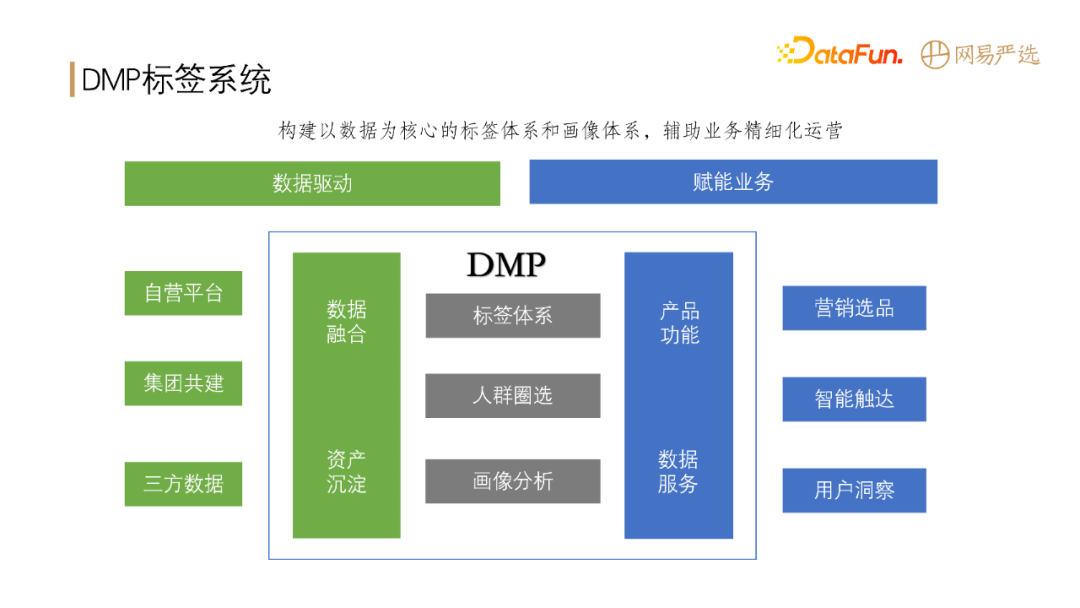
了解 DMP 系统,先从以下几个概念开始。
@@ -67,7 +65,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
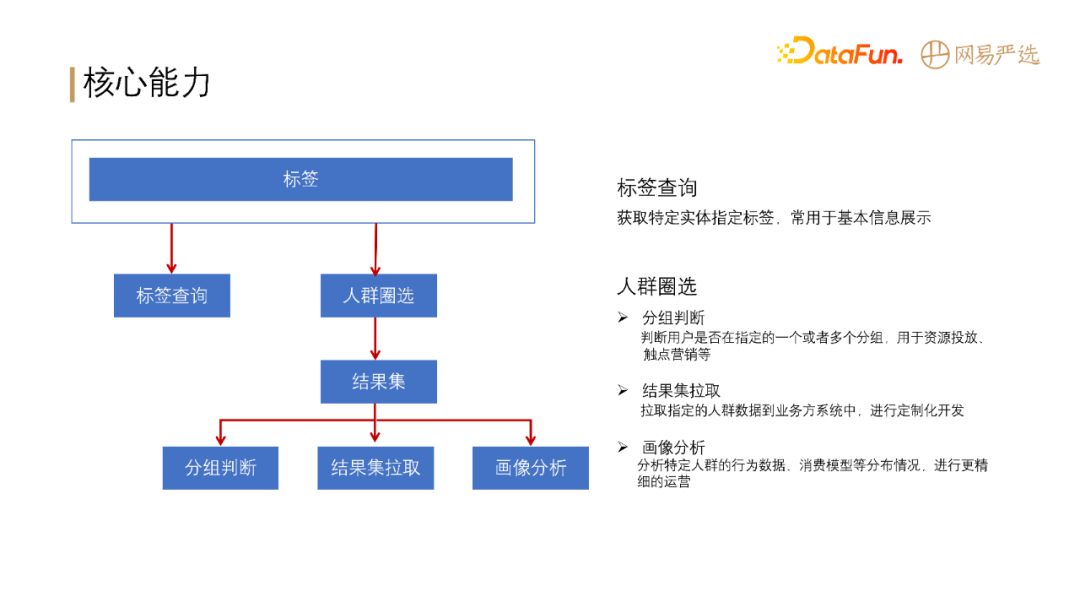
- **人群圈选**: 通过条件组合从全体用户中圈选出一部分用户,具体就是指定一组用户标签和其对应的标签值,得到符合条件的用户人群。
- **画像分析**: 对于人群圈选结果,查看该人群的行为情况、标签分布。例如查看【城市为杭州,且性别为女性】的用户在严选 APP 上的行为路径、消费模型等。
-
+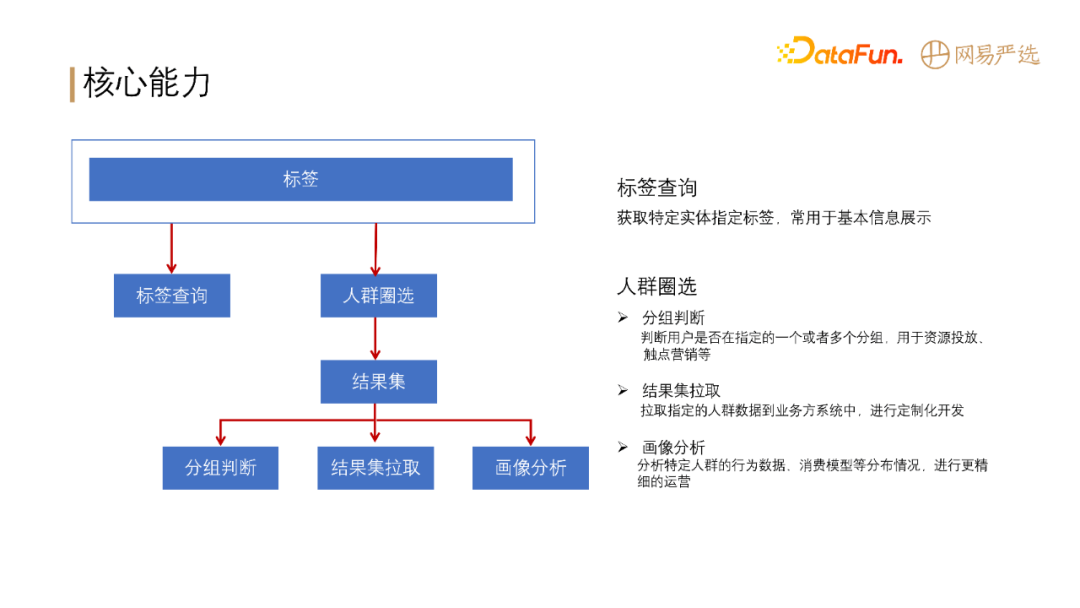
严选标签系统对外主要提供两大核心能力:
@@ -81,20 +79,20 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
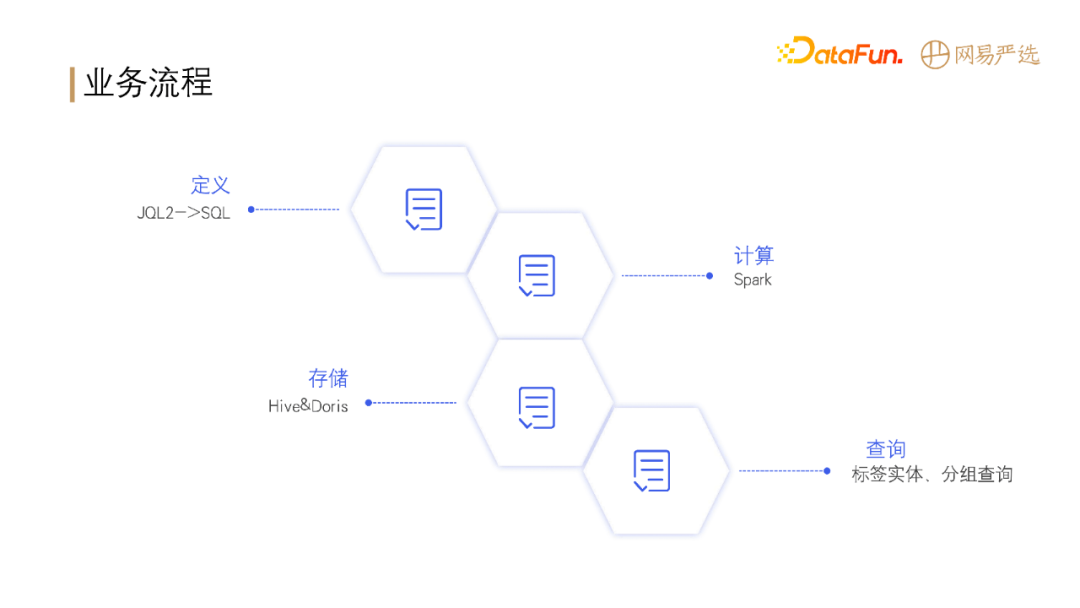
**整体的业务流程如下:**
-
+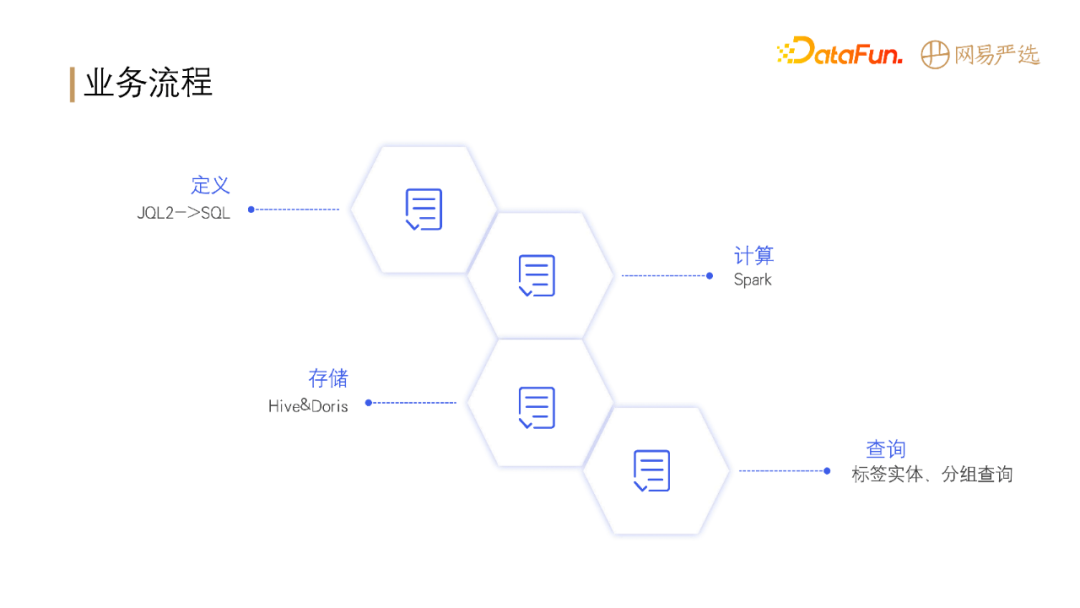
- 首先定义标签和人群圈选的规则;
- 定义出描述业务的 DSL 之后,便可以将任务提交到 Spark 进行计算;
- 计算完成之后,**将计算结果存储到 Hive 和 Doris**;
- 之后业务方便可以根据实际业务需求**从 Hive 或** **Doris** **中查询使用数据**。
-
+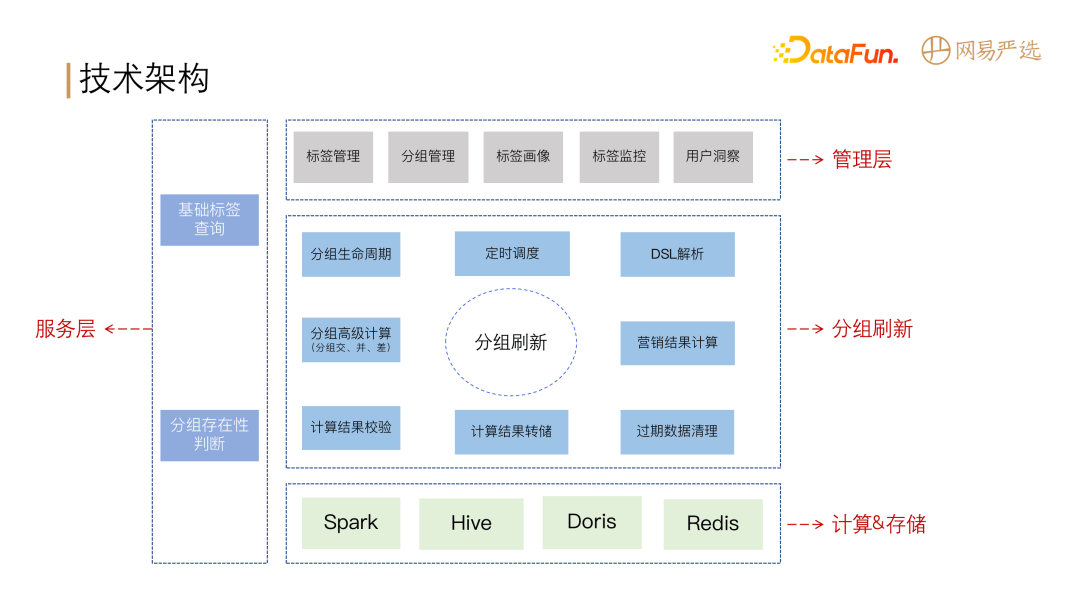
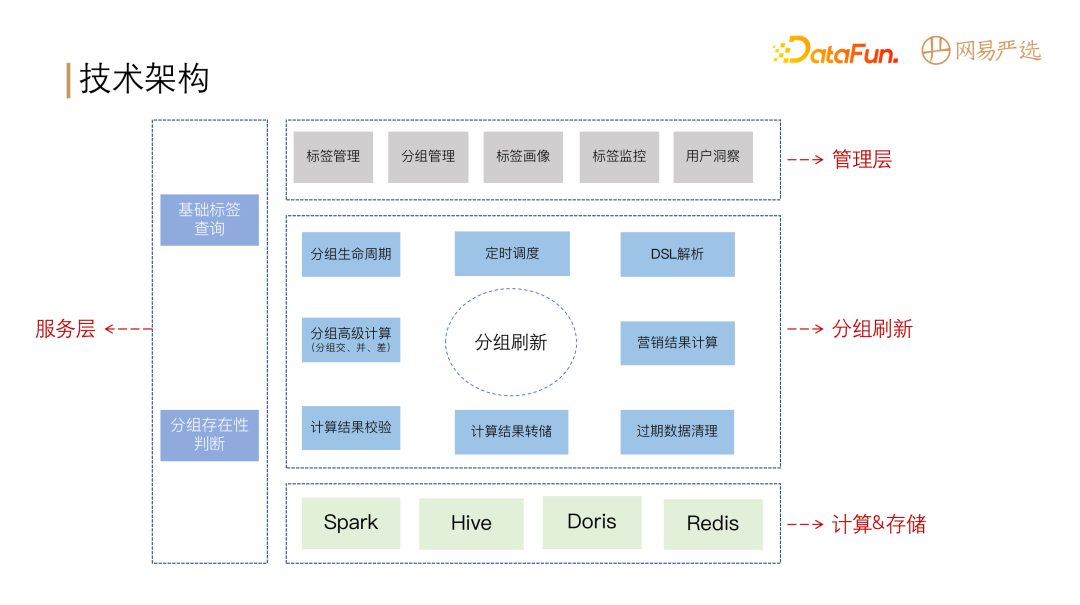
**DMP 平台整体分为计算存储层、调度层、服务层、和元数据管理四大模块。**
所有的标签元信息存储在源数据表中;调度层对业务的整个流程进行任务调度:数据处理、聚合转化为基础标签,基础标签和源表中的数据通过 DSL
规则转化为可用于数据查询的 SQL 语义,由调度层将任务调度到计算存储层的 Spark 进行计算,**并将计算结果存储到 Hive 和 Doris
中。**服务层由标签服务、实体分组服务、基础标签数据服务、画像分析服务四部分组成。
-
+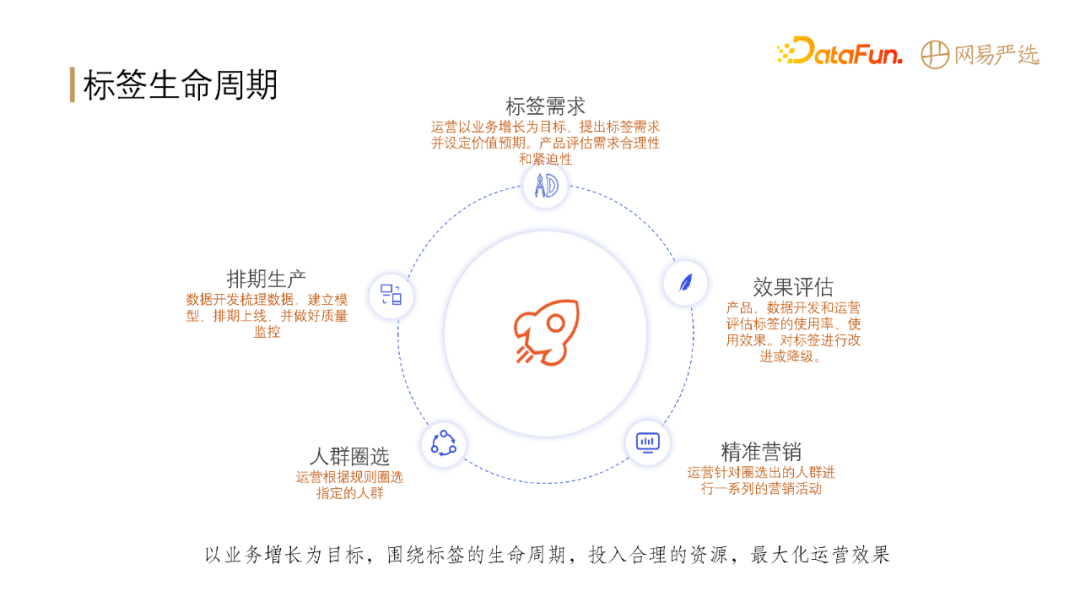
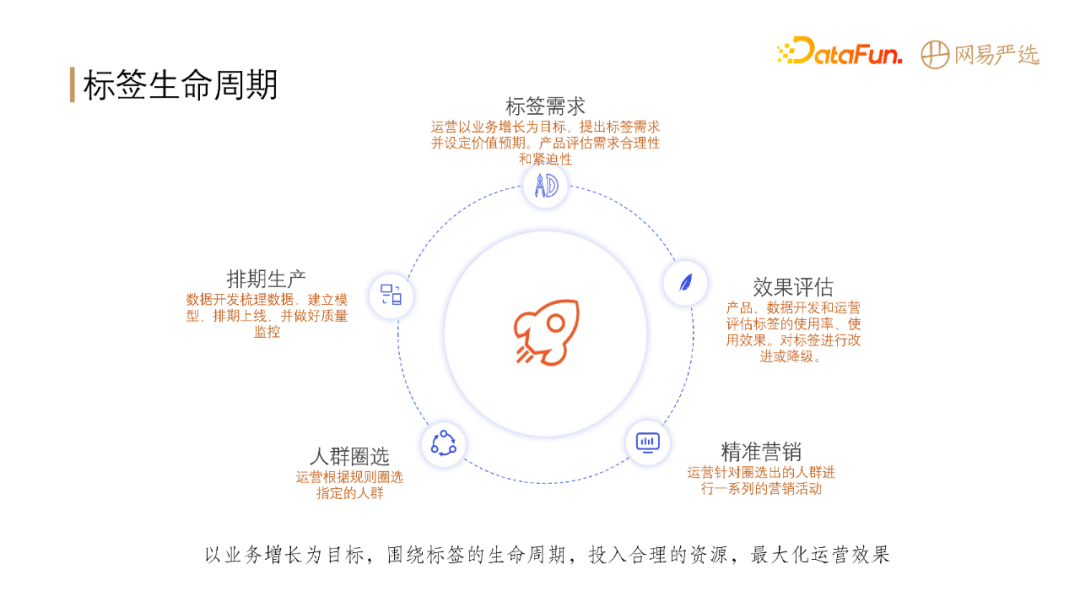
**标签的生命周期包含5个阶段:**
@@ -112,7 +110,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
**接下来介绍标签生产的整个过程。**
-
+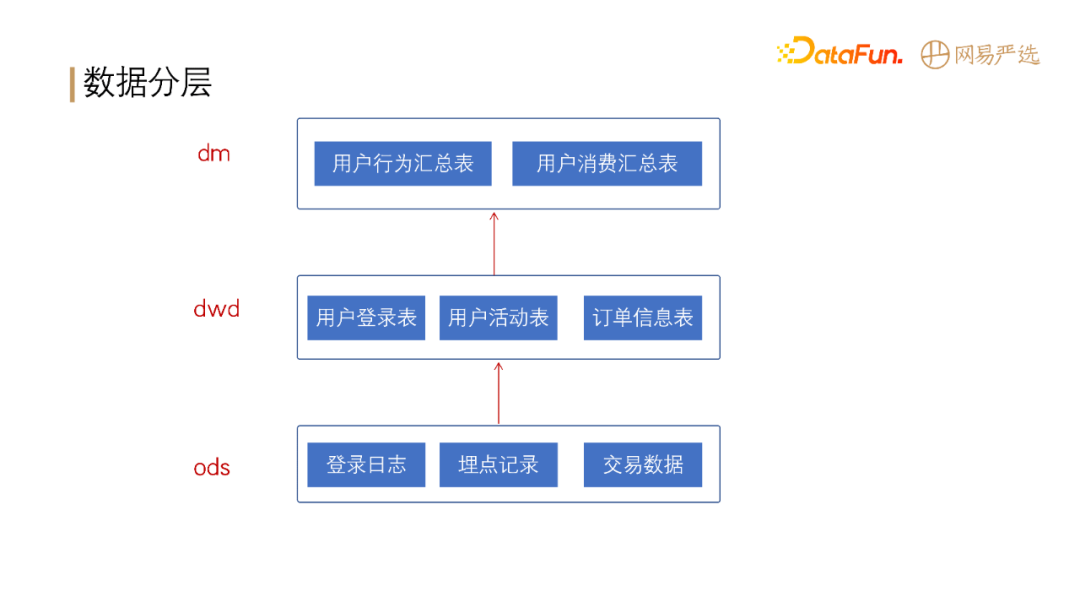
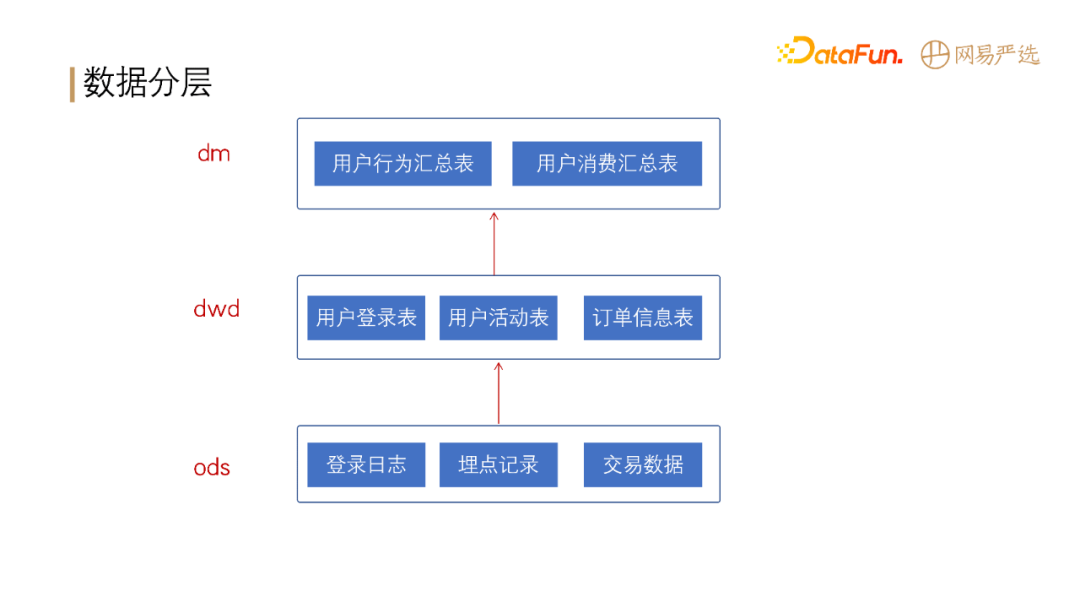
**标签的数据分层:**
@@ -122,7 +120,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
目前我们从原始数据库到 ods 层数据产出已经完全自动化,从 ods 层到 dwd 层实现了部分自动化,从 dwd 到 dm
层有一部分自动化操作,但自动化程度还不高,这部分的自动化操作是我们接下来的工作重点。
-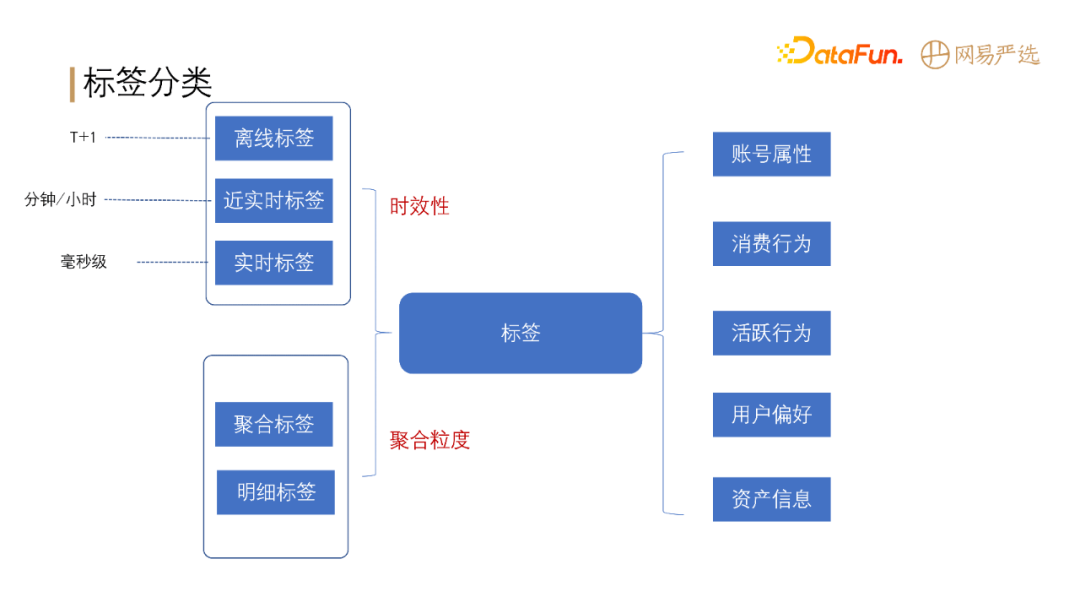
+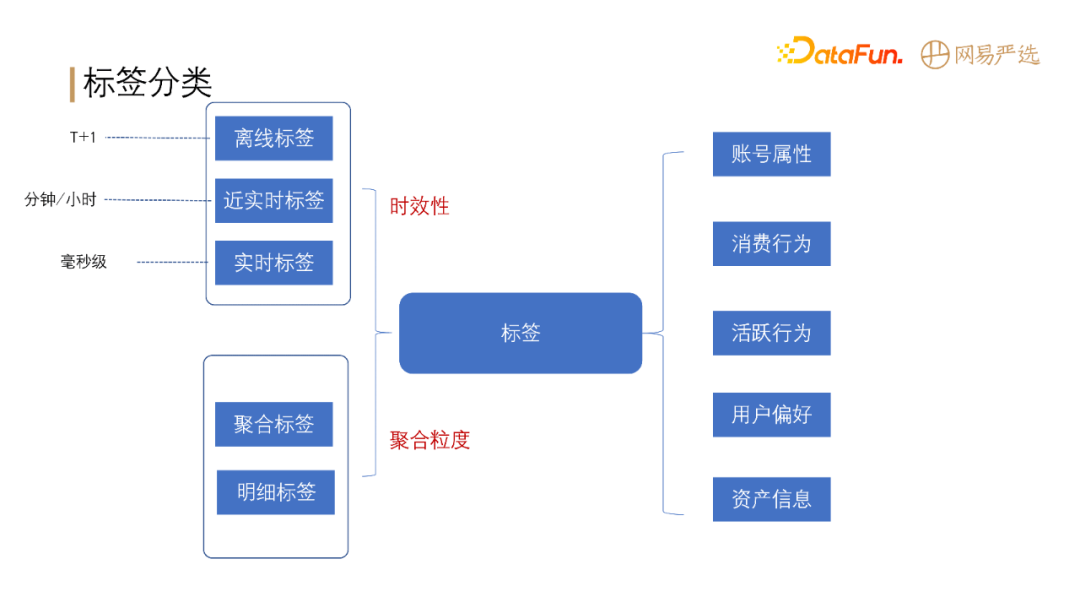
**标签根据时效性分为**:离线标签、近实时标签和实时标签。
@@ -130,21 +128,21 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
通过类别维度可将标签分为:账号属性标签、消费行为标签、活跃行为标签、用户偏好标签、资产信息标签等。
-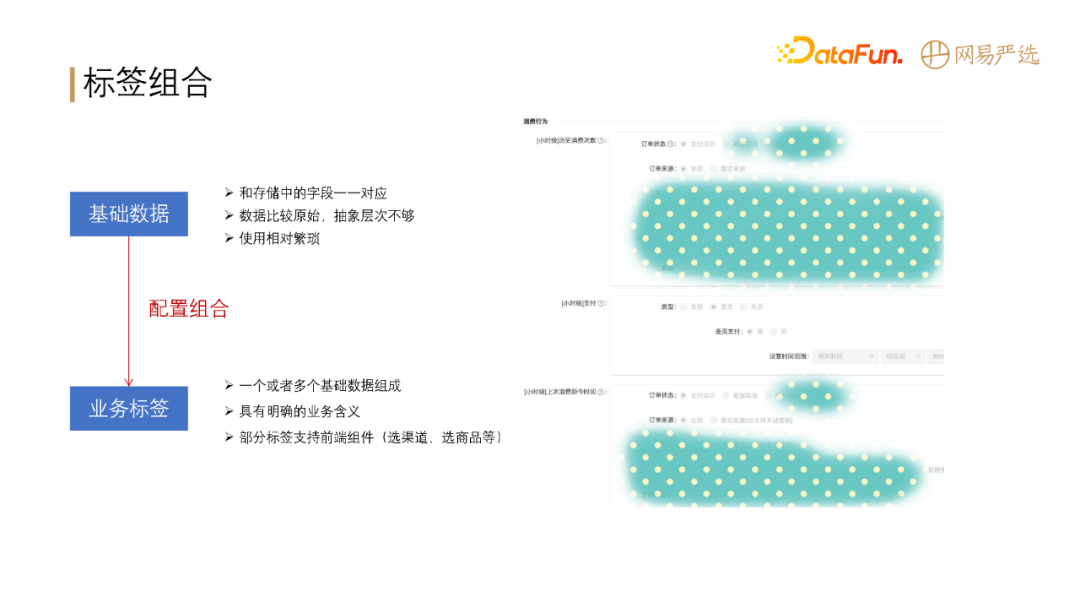
+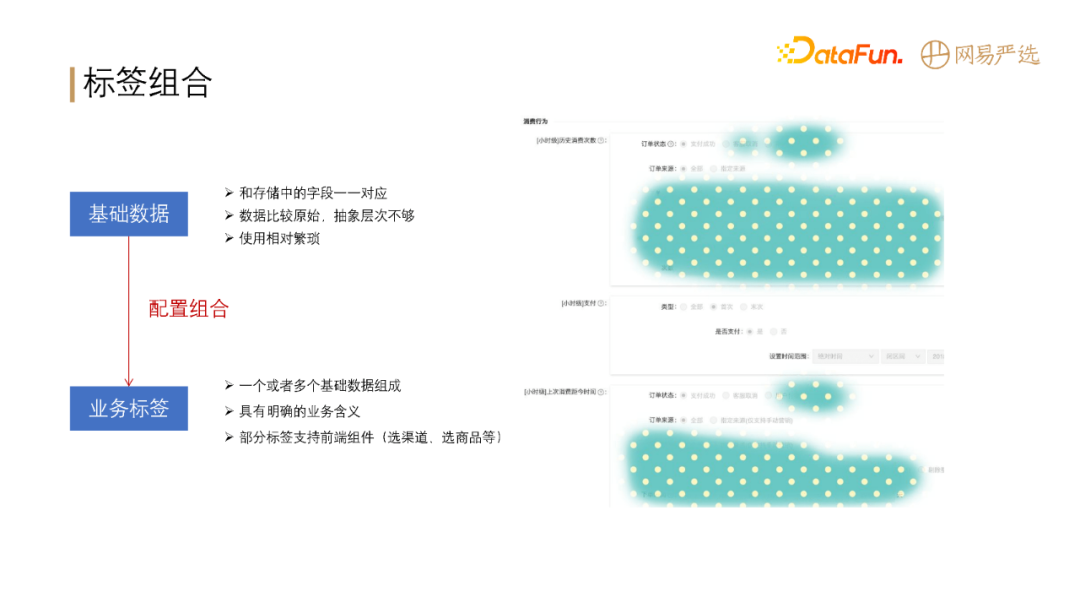
**直接将 dm 层的数据不太方便拿来用,原因在于:**
基础数据比较原始,抽象层次有所欠缺、使用相对繁琐。通过对基础数据进行与、或、非的组合,形成业务标签供业务方使用,可以降低运营的理解成本,降低使用难度。
-
+
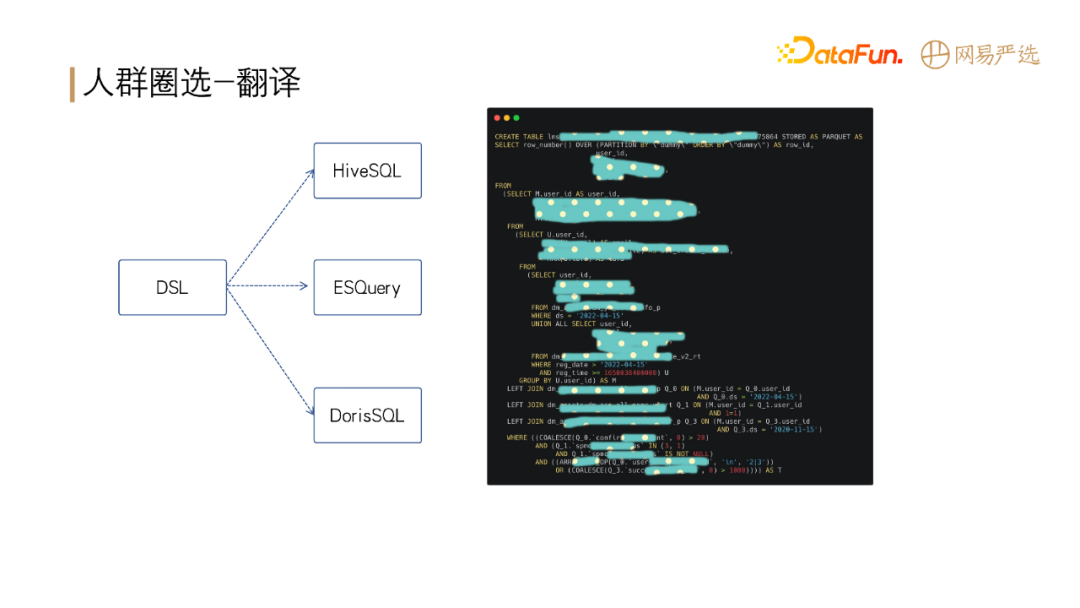
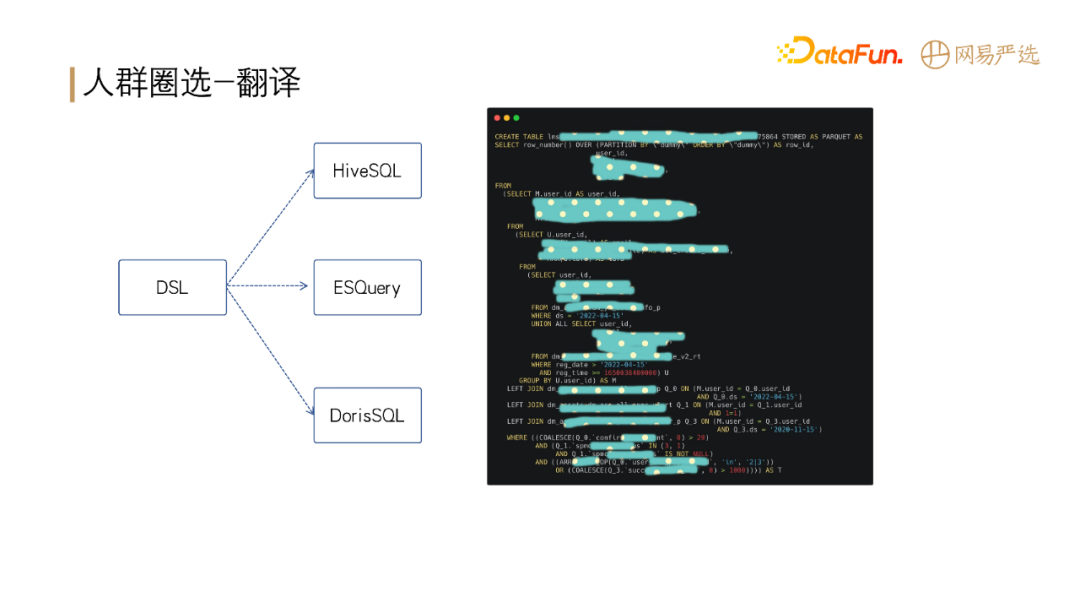
标签组合之后需要对标签进行具体业务场景应用,如人群圈选。配置如上图左侧所示,支持离线人群包和实时行为(需要分开配置)。
配置完后,生成上图右侧所示的 DSL 规则,以 Json 格式表达,对前端比较友好,也可以转成存储引擎的查询语句。
-
+
-
+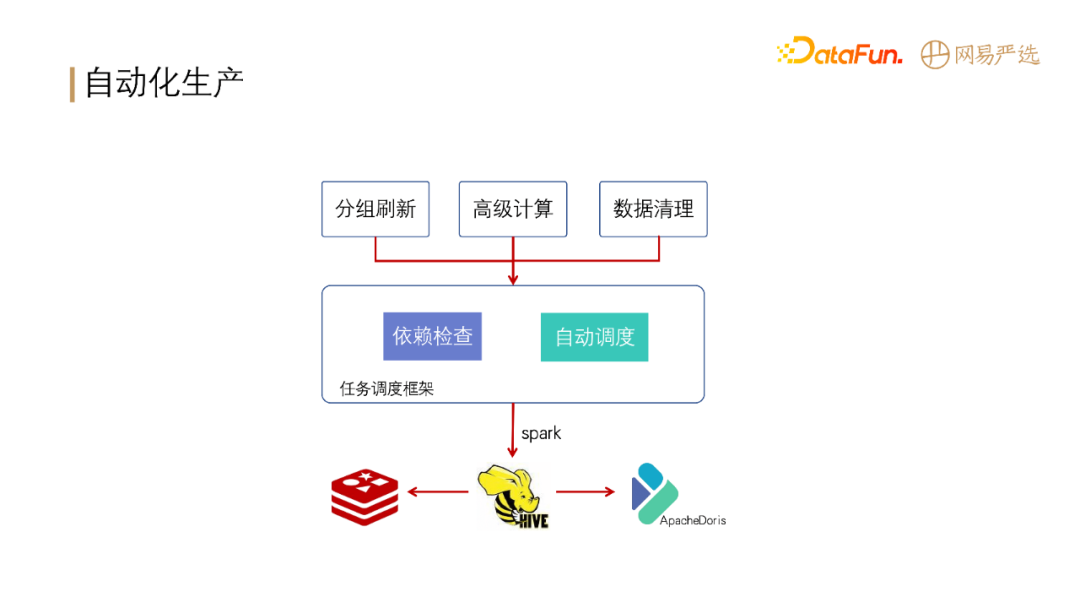
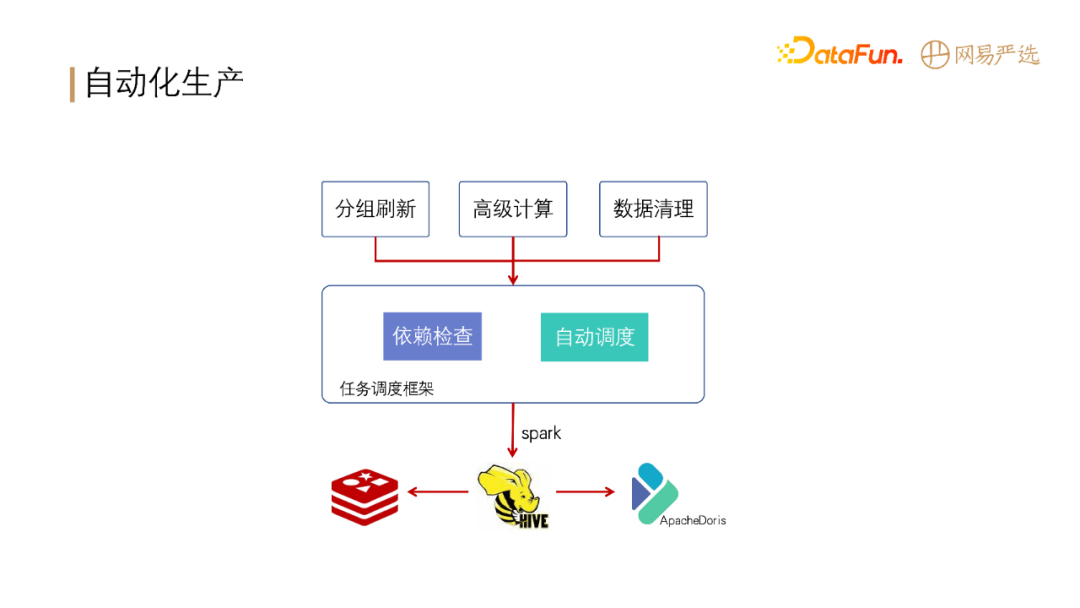
标签有一部分实现了自动化。在人群圈选部分自动化程度比较高。比如分组刷新,每天定时刷新;高级计算,如分组与分组间的交/并/差集;数据清理,及时清理过期失效的实体集。
@@ -167,7 +165,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
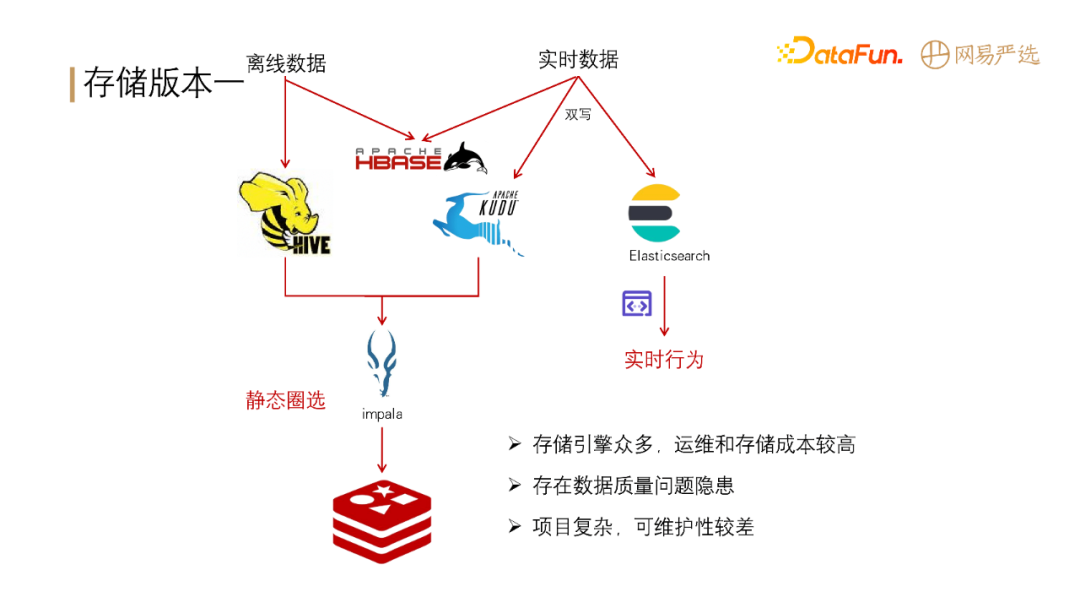
**我们第一版的存储架构如下图所示:**
-
+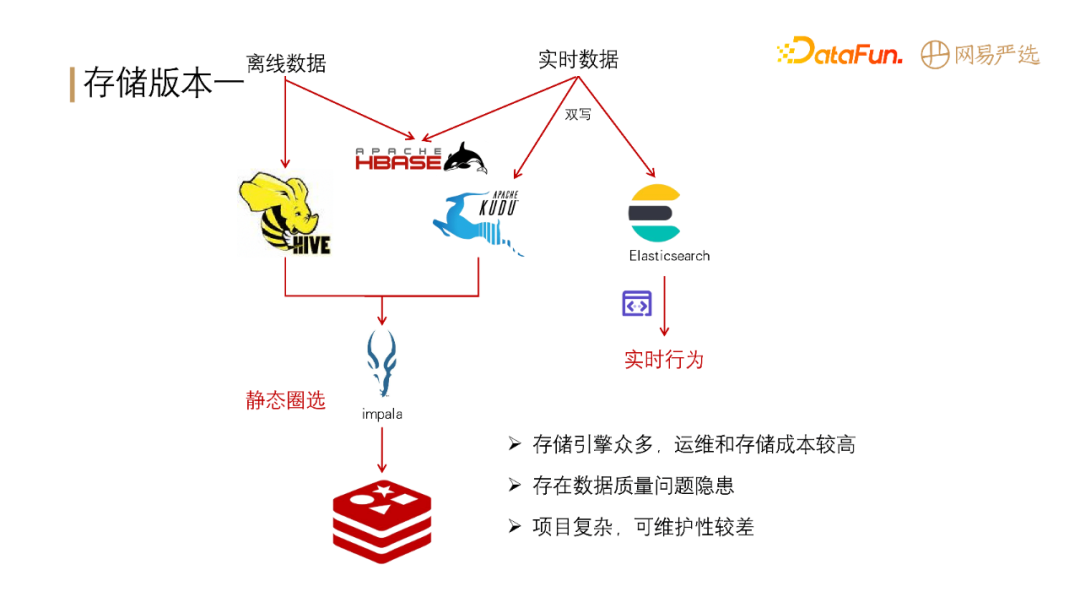
离线数据大部分存储在 Hive 中,小部分存储在 Hbase(主要用于基础标签的查询)。实时数据一部分存储在 Hbase 中用于基础标签的查询,部分双写到
KUDU 和 ES 中,用于实时分组圈选和数据查询。离线圈选的数据通过 impala 计算出来缓存在 Redis 中。
@@ -181,28 +179,28 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
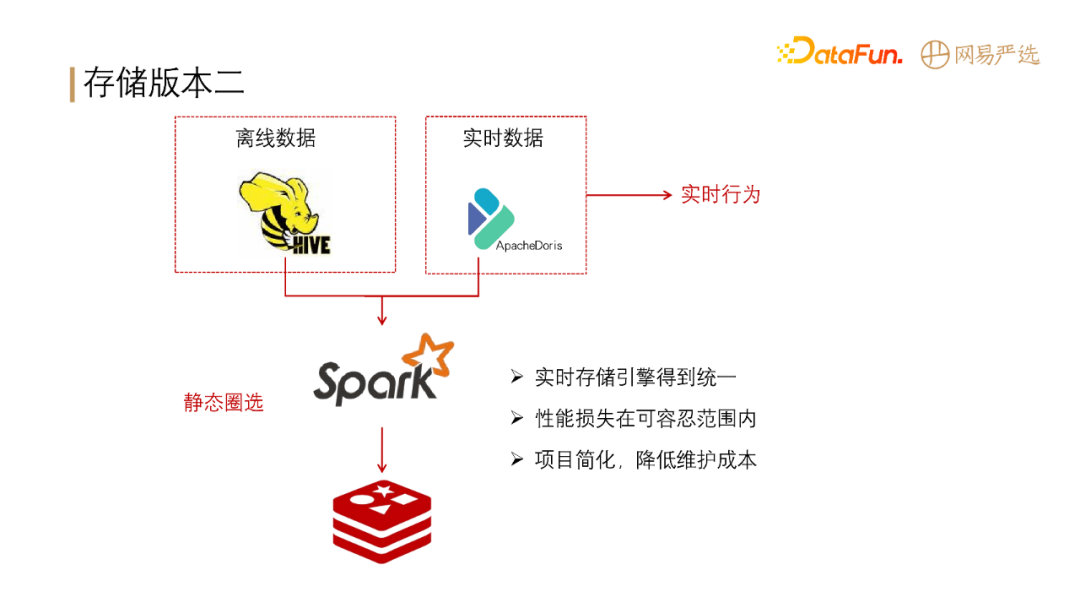
**我们第二版的存储架构如下图所示:**
-
+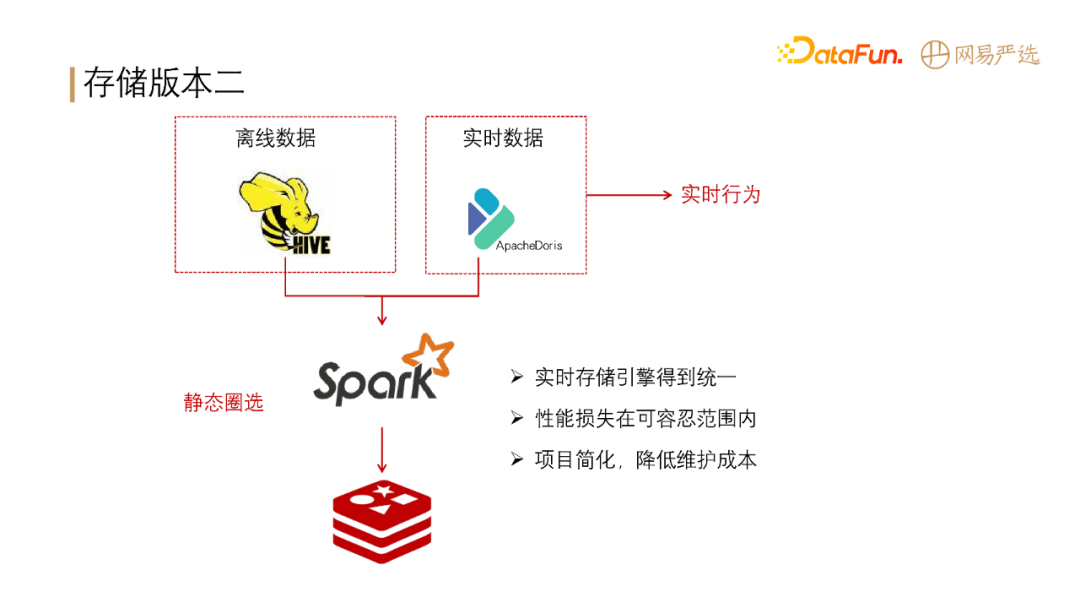
**存储架构版本二引入了 Apache Doris**,离线数据主要存储在 Hive 中,同时将基础标签导入到 Doris,实时数据也存储在
Doris,基于 Spark 做 Hive 加 Doris 的联合查询,并将计算出来的结果存储在 Redis
中。经过此版改进后,实时离线引擎存储得到了统一,性能损失在可容忍范围内(Hbase 的查询性能比 Doris 好一些,能控制在 10ms 以内,Doris
目前是 1.0 版本,p99,查询性能能控制在 20ms 以内,p999,能控制在 50ms 以内);**项目简化,降低了运维成本。**
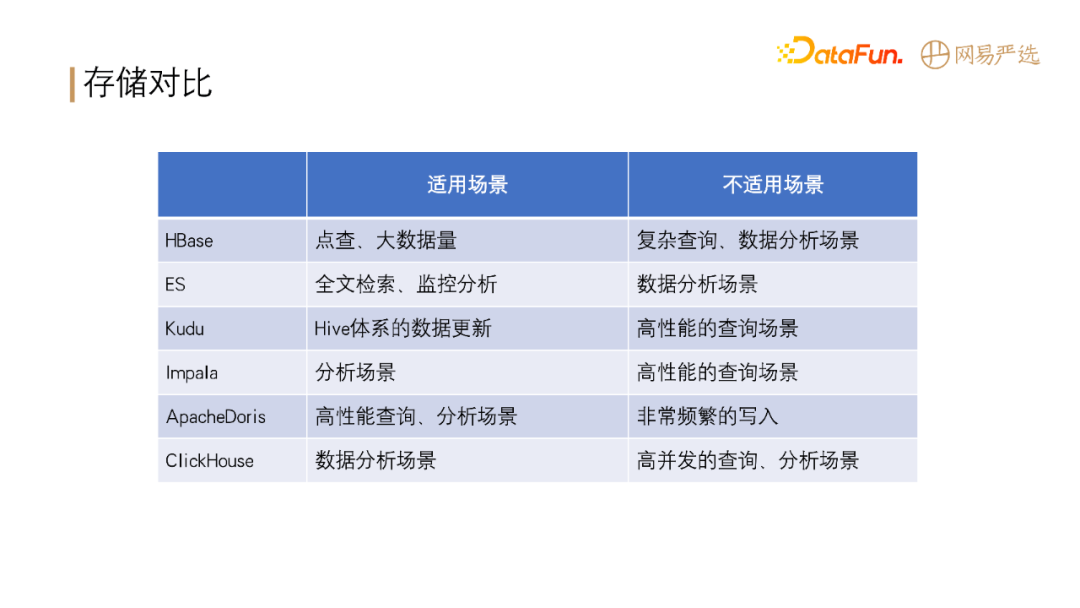
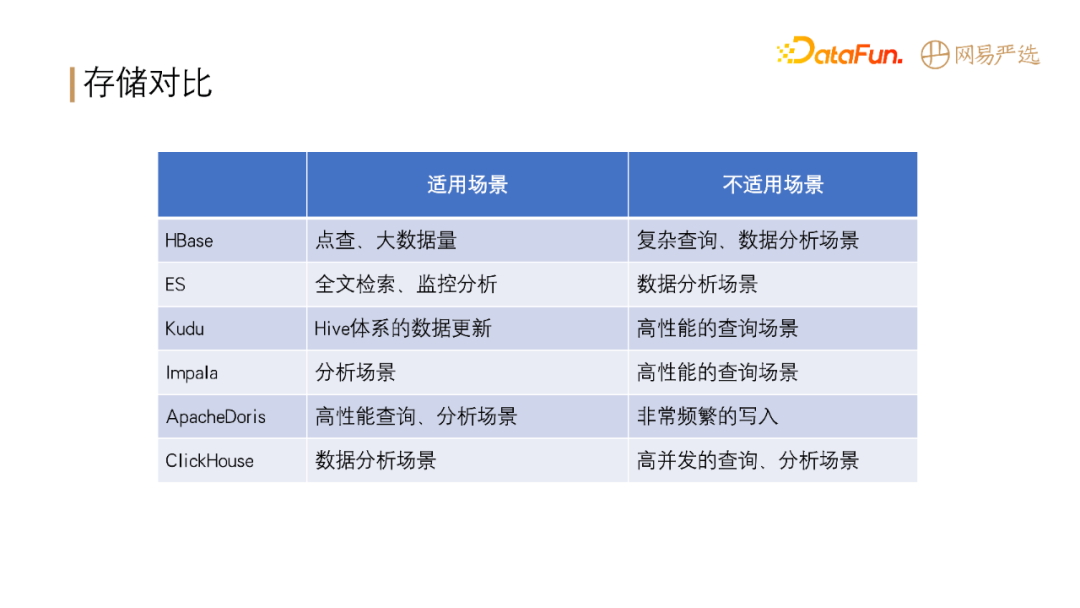
**在大数据领域,各种存储计算引擎有各自的适用场景,如下表所示:**
-
+
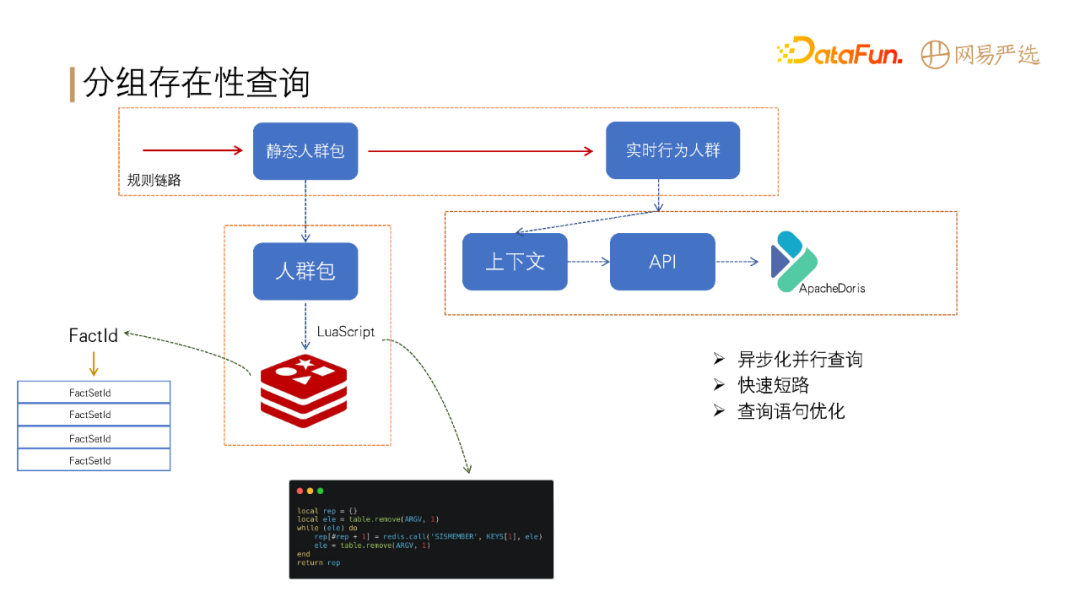
# 高性能查询
-
+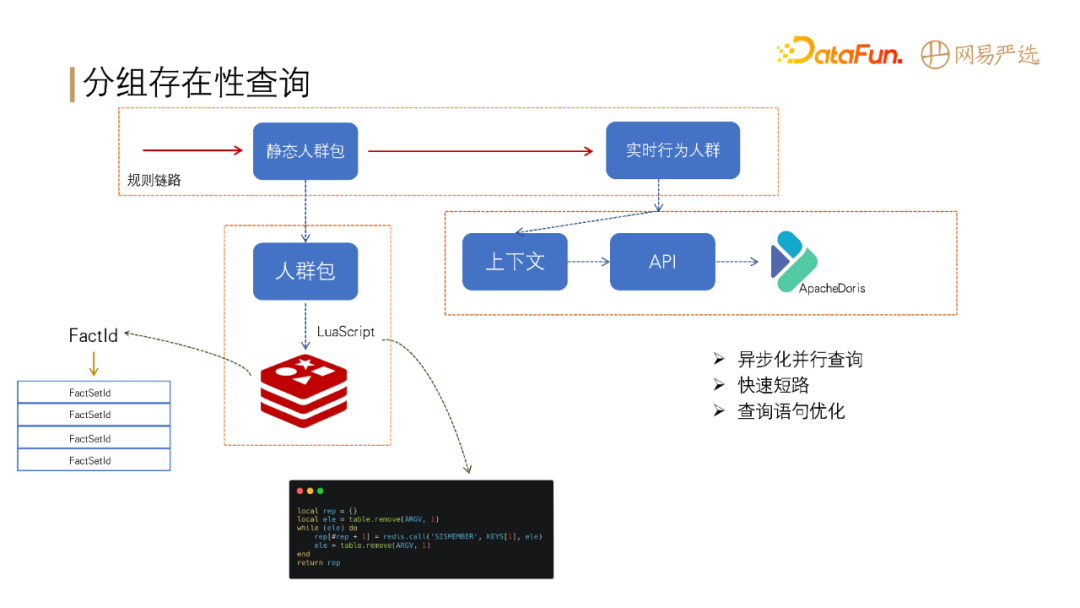
分组存在性判断:判断用户是否在指定的一个分组或者多个分组。包括两大部分:
- 第一部分为静态人群包,提前进行预计算,存入 Redis 中(Key 为实体的 ID,Value 为结果集 ID),采用 Lua
脚本进行批量判断,提升性能;
- 第二部分为实时行为人群,需要从上下文、API 和 Apache Doris
中提取数据进行规则判断。性能提升方案包括,异步化查询、快速短路、查询语句优化、控制 Join表数量等。
-
+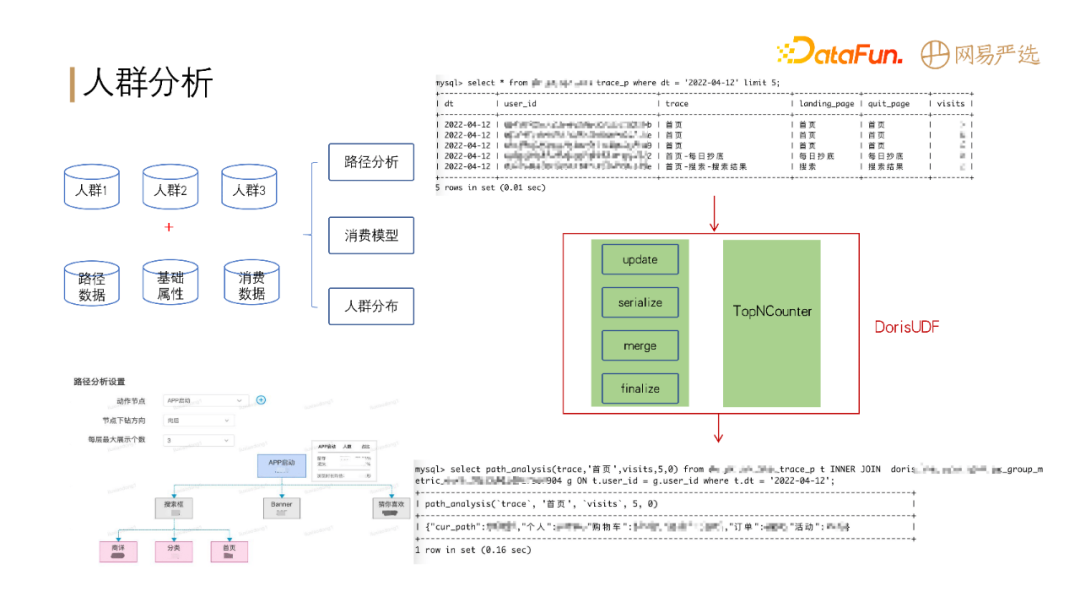
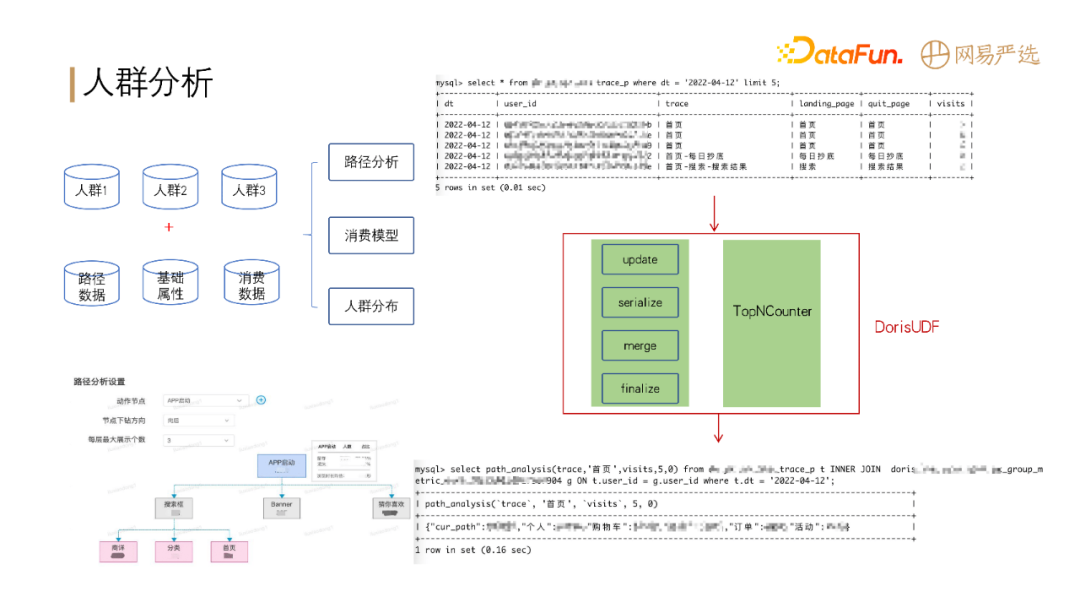
还有一个场景是人群分析:人群分析需要将人群包数据同多个表进行联合查询,分析行为路径。目前 Doris 还不支持路径分析函数,因此我们开发了 DorisUDF
来支持此业务。**Doris 的计算模型对自定义函数的开发还是很友好的,能够比较好地满足我们的性能需要。**
-
+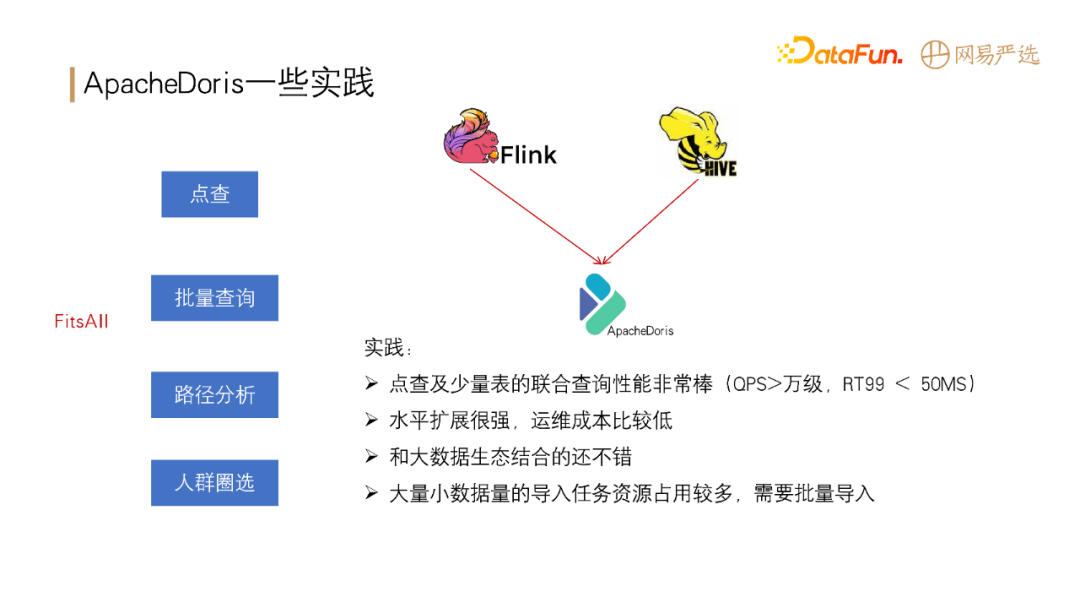
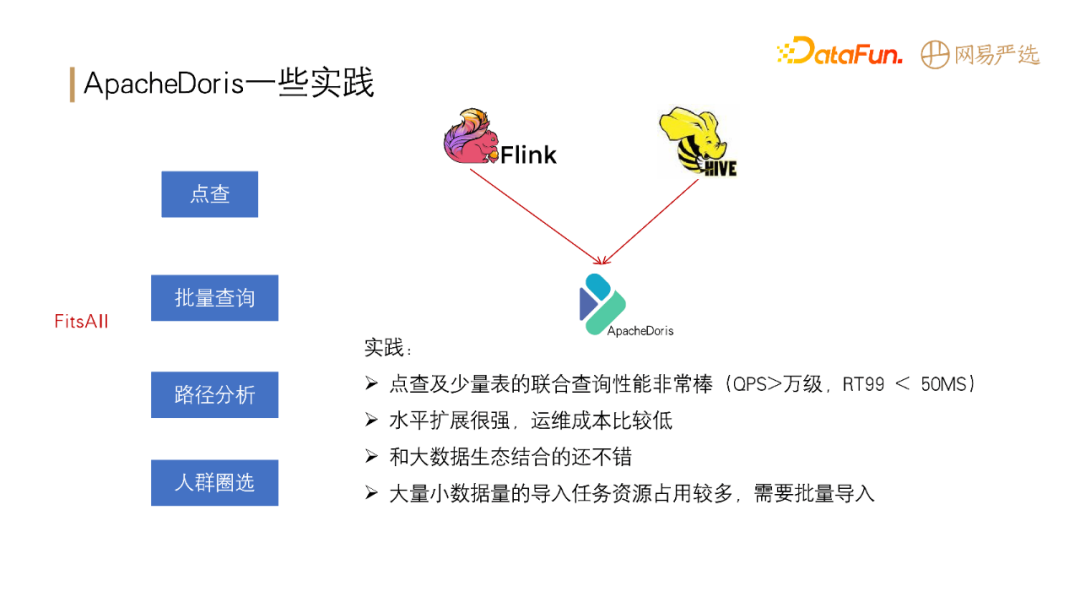
**Apache Doris 在网易严选中已应用于点查、批量查询、路径分析、人群圈选等场景。在实践中具备以下优势:**
@@ -216,7 +214,7 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
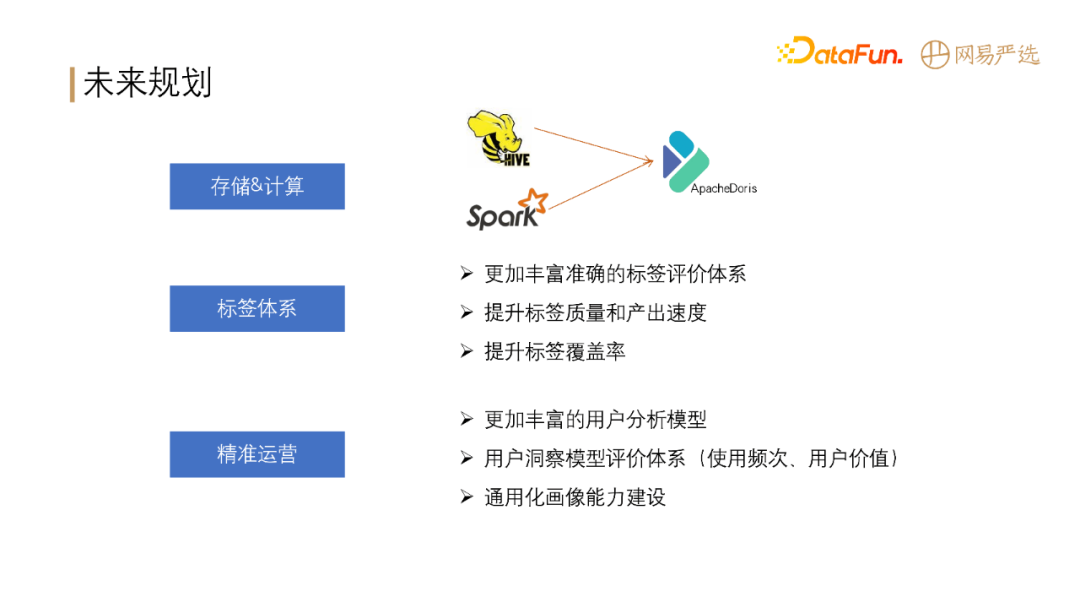
# 未来规划
-
+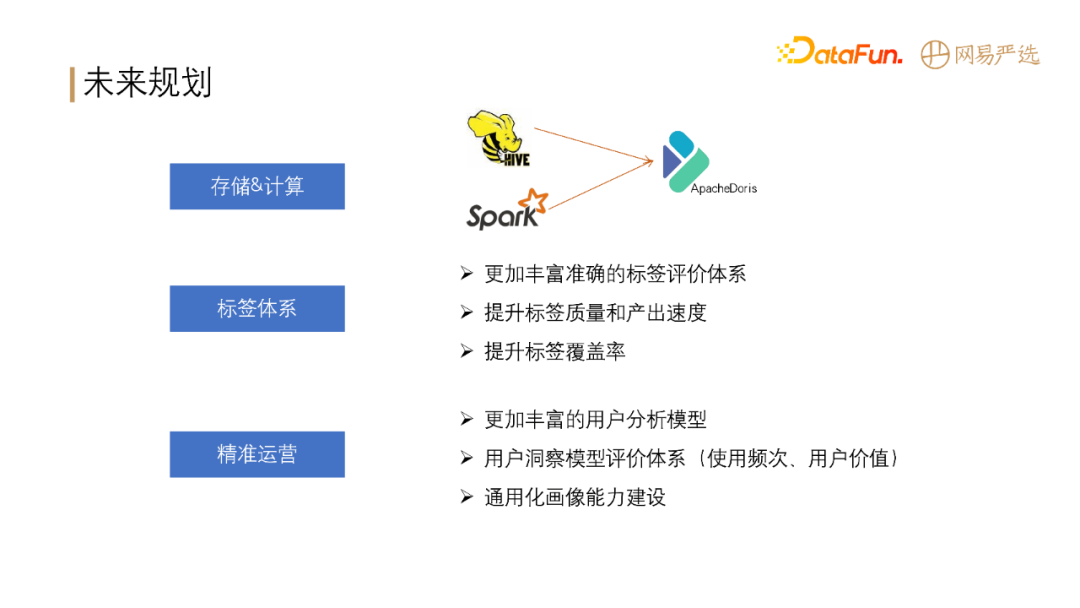
**提升存储&计算性能**: Hive 和 Spark 逐渐全部转向 Apache Doris。
@@ -239,16 +237,8 @@ DMP 作为网易严选的数据中台,向下连接数据,向上赋能业务
关注公众号「**SelectDB**」,后台回复【**网易严选**】获取本次演讲 **PPT 资料**!
-
-
-
-SelectDB 是一家开源技术公司,致力于为 Apache Doris
社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于 Apache Doris
研发的新一代云原生实时数仓 SelectDB,运行于多家云上,为用户和客户提供开箱即用的能力。
-
**相关链接:**
-SelectDB 官方网站:
-
-https://selectdb.com
Apache Doris 官方网站:
@@ -260,4 +250,4 @@ https://github.com/apache/doris
Apache Doris 开发者邮件组:
[email protected]
\ No newline at end of file
[email protected]
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
b/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
index 6e8eac006eb..4b960363871 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/summit.md
@@ -1,6 +1,6 @@
---
{
- 'title': '十年对于数据库意味着什么?',
+ 'title': '下一个十年,我们需要一款什么样的 OLAP 数据库?',
'summary': '十年对于数据库而言,可能是一段从诞生到消逝的完整软件生命周期,也可能是迈过里程碑之后的全新旅程。',
'date': '2023-01-06',
'author': '陈明雨',
@@ -197,4 +197,4 @@ under the License.
希望通过这一定位的转变迎接下一个十年的挑战,或许技术趋势会有变化,架构将会革新,但我们解决用户数据分析问题的初衷不会改变。
-希望继续带着上一个十年出发的初心,开启下一个十年的旅程。
\ No newline at end of file
+希望继续带着上一个十年出发的初心,开启下一个十年的旅程。
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}