jihoonson opened a new issue #7491: Introducing minor compaction with segment locking URL: https://github.com/apache/incubator-druid/issues/7491 ### Background #### Druid's versioning system & segment timeline Currently in Druid, a segment is tightly coupled with its _interval_. All timestamps stored in the segment fall into segment's interval. The segment version is associated with the segment interval. That is, all _visible_ segments in the same interval have the same version. With the concept of segments and their intervals, we can imagine that a set of segments composes a [_segment timeline_](http://druid.io/docs/latest/ingestion/index.html). The segment timeline can be thought of as a timeChunk space. In this space, the segments are lined up by their interval. The segments of the same interval fall into the same timeChunk. This can be represented by a sorted map of interval and its corresponding segments, which is implemented in `VersionedIntervalTimeline`. The `VersionedIntervalTimeline` is responsible for searching for the segments of the highest version in the given interval (`lookup()`). If there are two or more segments of different versions in the same interval, the segments of the lower version are _overshadowed_ by the ones of the highest version and not visible to other components in Druid. This timeline is being used primarily by coordinators and brokers to update the timeline with new segments and to find queryable segments, respectively. We are also using the timeline in many places to figure out the latest segments from the given set of segments. #### TimeChunk locking In Druid, tasks should get a task lock before reading or writing segments. This task lock is currently for coordinating all accesses to a timeChunk. For example, if a task needs to read segments of a timeChunk of `2019-01-01/2019-01-02`, it should get a lock for that timeChunk before reading segments. While this lock is valid, no other tasks can read segments in the same timeChunk or write new segments into it. Once a task gets a lock, it remains valid until 1) the task is finished or 2) another task of a higher priority revokes the lock (see https://github.com/apache/incubator-druid/issues/4479 for more details). <img width="1115" alt="time chunk lock" src="https://user-images.githubusercontent.com/2322288/45274547-d5215800-b46c-11e8-9d43-060dadf6ed0b.png";> This figure shows an example of time chunk locking. `IndexTask` and `KafkaIndexTask` got a lock for the timeChunk of `2018-01-01/2018-04-01` and `2018-08-01/2018-09-01`, respectively. Note that each task can generate one or more segments. If a task creates multiple segments using the same lock, the created segments would have the same version. The version of new locks usually have the higher version than the old ones. For example, overwriting tasks always get a lock of the higher version than that of existing segments. However, sometimes, we need to use the same version across different locks. The well-known use case is the tasks of the appending mode like kafkaIndexTask. Since these tasks append new segments to timeChunks where some segments can already exist, the new segments shouldn't overshadow the existing ones. So, the appending tasks get the lock of the same version with the existing segments. This is implemented in `TaskLockBox`. ### Motivation Since https://github.com/apache/incubator-druid/issues/6136 is describing well what the problem and the motivation are, I'm just summarizing the key problems and motivations here. #### Late data problem The kafkaIndexTask has the higher priority than the compactionTask by default. If some data arrives late, the kafkaSupervisor spawns new kafkaIndexTasks to handle the late data. If a compaction tasks was running for any overlapping timeChunk, the new kafkaIndexTask would revoke the locks of the running compactionTask. If this happens frequently, the compaction might never complete. To avoid this problem, the compaction should be available while new data is being ingested into the same dataSource and the same timeChunk. From the perspective of optimization, this is also good because more recent data becomes available for compaction as soon as it gets ingested into Druid. ### Requirements for compaction - A segment should be available for compaction immediately once it is published. - Overwriting tasks (including compactionTask) and appending tasks shouldn't interfere each other. More generally speaking, two tasks shouldn't block each other if they read/write from/to different segments. - This implies the segments generated by appendingTasks should be always queryable even if overwriting tasks are running for the same timeChunk. - Overwriting tasks can change the segment granularity. This means, a segment can overshadow another segment even if they have different timeChunks. - Overshadowing relation should be encoded efficiently in each segment to minimize the memory footprint of segments. ### Proposed changes I propose to have two different types of compaction: _major compaction_ and _minor compaction_. The major compaction is to generate perfectly rolled up, fully optimized segments in both size and query performance. To fully optimize segments in each timeChunk, the major compaction would get a lock for each entire timeChunk, and then use those timeChunks exclusively. As a result, major compaction can't be performed with other ingestion tasks together for the same timeChunk at the same time. The minor compaction generates sub-optimized segments in size with best-effort rollup. Since minor compaction would lock each input segments instead of locking entire timeChunks, it can be performed with other ingestion tasks for same timeChunks simultaneously. (Locking individual segment will be explained below.) Minor compaction can be used to optimize segments quickly as they are created, and later, major compaction can be used to further optimize them. For example, if you're ingesting data from Kafka, you can first optimize generated segments using minor compaction while stream data is being ingested. Later, you can perform major compaction to fully optimize them to reduce disk usage (if rollup is enabled) and to improve query performance. My idea about major compaction is not concrete yet, so in this proposal, I'll focus on minor compaction first and add some more details for major compaction in the "Future Work" section. #### Locking individual segments To lock individual segments, I propose to add a new lock type, _segment lock_. Unlike timeChunk lock, segmentLock is to coordinate the access (reading/writing) to individual segments. With segmnet lock, each task should get a lock whenever it reads or writes a segment. If two or more tasks request a lock for the same segment at the same time, only one task will get a lock and others should wait for the task to release the lock. Since two or more tasks can read or write segments of the same timeChunk, there should be no lock contention between appending tasks (e.g., kafkaIndexTask) and overwriting tasks (e.g., compactionTask). <img width="944" alt="segment lock" src="https://user-images.githubusercontent.com/2322288/45274914-7826a180-b46e-11e8-8dd7-b1faa314e3a4.png";> This figure shows an example of the segment locking. A compactionTask should get locks for all input segments before it starts. It should also get locks for output segments before writing segments. A kafkaIndexTask gets a new lock whenever it reads an event of a new timestamp which is not covered by its current locks. Since each task has separate locks for individual segments, there's no lock contention between kafkaIndexTask and compactionTask even though they are running for the same dataSource and the same timeChunk. Please note that segment lock doesn't replace the existing timeChunk lock. Instead, both can be used in different cases. Details are described in the below 'Changes in indexing service' section. The below sections describes details of the algorithms for timeline management and segment locking. #### Encoding overshadowing relation in Data Segment To be able to check overshadowing relation between any segments (no matter that they are published, unpublished, realtime segments, etc), the entire overwriting history should be encoded into each segment. For example, if the segment `A` is created by compacting segments `B` and `C`, which in turn are created by compacting segments `D`, `E`, and `F`, we should be able to figure out `A` overshadows `D`, `E`, and `F`, by looking at only those segments (this is important because looking up queryable segments is in the query path in brokers). To efficiently encode this information in each segment, 3 additional restrictions are required. 1. First-generation segments can be compacted only if they have adjacent partitionIds. The first generation segments are created by non-overwriting tasks, e.g., kafka tasks or index tasks. Two partitionIds are adjacent if their partitionIds are consecutive. 2. Non-first-generation segments can be compacted with other segments when they are created from adjacent first-generation segments or first-generation segments of adjacent partitionIds. 3. When compacting non-first-generation segments, all segments created from the same first-generation segments must be compacted together. The below images show exmples of these restrictions. `Gn` means _nth_ generation and each rectangle containing `Pn` inside it is a segment of partitionId `Pn`.  This figure shows the restriction 1. In this example, segments of partitionIds of `P0` and `P1` can be compacted together because they have adjacent partitionIds while `P2` and `P4` can't be compacted.  This figure shows the restriction 2. In this example, `P6` and `P7` overshaodw `P0`, `P1`, and `P2`. Similarly, `P8` overshadows `P4` and `P5`. `P6`, `P7`, and `P8` can't be compacted because `P6` and `P7` are created from `P0`, `P1`, and `P2` while `P8` is from `P4` and `P5`. However, `P3` and `P8` can be compacted because the first-geneartion segments of `P8`, i.e., `P4` and `P5`, are adjacent to `P3`.  This figure shows the restriction 3. `P6` and `P7` can be compacted with `P3` together, but both `P6` and `P7` must be included in compaction because they are from the same first-generation segments. With these restrictions, the partitionIds of the first-generation segments of non-first-generation segments are _always_ consecutive. As a result, we can encode them into a range in each segment. An extra `short` minor version is required to fingure out the latest segment. "AtomicUpdateGroup" is the segments which should be updated all together atomically in the timeline (This will be further explained later in the below "Timeline construction algorithm" section). Finally, non-first-generation segments would have a special shardSpec, `NumberedOverwritingShardSpec` which have 4 additional fields like below: ```java public class NumberedOverwritingShardSpec implements ShardSpec { private final int partitionId; private final short startRootPartitionId; private final short endRootPartitionId; // exclusive private final short minorVersion; private final short atomicUpdateGroupSize; // number of segments in atomicUpdateGroup } ``` Note that `partitionId` is usually stored as an integer in Druid, but here we use an _unsigned short_ to save memory usage (It's stored as a short, but will be extracted as if it's an unsigned short). It should be fine because, in general, number of partitions in a timeChunk should be much smaller than 30,000. Regarding restrictions above, it's important to make the partitionIds of the first-generation segments consecutive to facilitate compaction. To do this, we use separate partitionId space for first-generation segments and non-first-generation segments: (0 - 32767) is for first-generation and (32768 - 65535) is for non-first-generation segments. To easily coordinate segment allocation for first-generation and non-first-generation segments, a new table, called `pendingoverwritingsegments`, is required to be added to the metadata store. `pendingsegments` and `pendingoverwritingsegments` tables are used for allocating new segmentIds for first-generation and non-first-generation segments, respectively. After compaction (or an overwriting task is finished), the output segments would have updated metadata. - If compaction merges segments, the rootPartition range is also merged and minorVersion is increased. - If compaction splits segments, the rootPartition range is not changed but minorVersion is increased. - AtomicUpdateGroupSize is the number of output segments of the compaction task (or overwriting task). #### Lock granularity (segment lock vs timeChunk lock) Indexing tasks now have two options for locking, i.e., segment lock and timeChunk lock. ##### Segment lock All tasks should use segment lock except when they overwrite existing segments with the different segmentGranularity. In segment locking, a task first gets locks for all input segments if exist. Whenever the task writes a new row having the timestamp which are not covered by the current lock for output segments, it gets a new lock for the new output segment. This lock allocation for new segments involve allocating new segmentIds as well. If the task is overwriting existing segments, the new segmentIds would still have the _same_ version with existing segments but its `startPartitionId`, `endPartitionId`, `minorVersion`, and `atomicUpdateGroupSize` will be filled properly. The `SegmentLock` would be: ```java public class SegmentLock implements TaskLock { private final TaskLockType lockType; private final String groupId; private final String dataSource; private final Interval interval; private final String version; private final int priority; private final boolean revoked; private final IntSet partitionIds; // partitionIds of locked segments } ``` With this change, a giant batch task can get a lot of segment locks instead of a single timeChunk lock. Stream ingestion tasks can also have multiple segment locks and they should release those locks once they publish corresponding segments. ##### TimeChunk lock The timeChunk lock is same with the current taskLock. Tasks get a lock for a timeChunk (e.g., `2019-01-01/2019-01-02`) before reading segments from the timeChunk or writing new segments into the timeChunk. The timeChunk lock is used only when overwriting tasks change the segment granularity. For example, if a compactionTask with segmentGranularity = `DAY` should use the timeChunk lock if the original segmentGranularity was `HOUR`. When a task requests a timeChunk lock, the overlord allocates a new version for the requested lock which must be higher than the versions of any existing segments in the same timeChunk. All new segments created with this lock would have the new version. Since new segments with a timeChunk lock would always have a higher version than existing segments, they overshadow all existing segments. The `TimeChunkLock` class would look like below: ```java public class TimeChunkLock implements TaskLock { private final TaskLockType type; private final String groupId; private final String dataSource; private final Interval interval; private final String version; private final Integer priority; private final boolean revoked; } ``` ##### Configuring lockGranularity in taskContext TimeChunk lock is used only when a task overwrites existing segments with a different segmentGranularity. Otherwise, they use segment lock by default. However, users can set lockGranularity to use in the taskContext of their ingestion spec as below: ```json context { "lockGranularity": "timeChunk" or "segment" } ``` #### Segment allocation Segment allocation is allocating segmentIds for new segments. The segment allocation algorithm is different depending on the lock granularity and the rollup mode. If the lock granularity = segmentLock, the segment allocation must be centralized in the overlord so that all segments of the same version have a different partitionId in the same timeChunk. If the lock granularity = timeChunkLock, each task can generate segments of any partitionIds by itself since new segments would have a higher version than existing segments. If rollup mode = best-effort rollup, segments can be allocated dynamically whenever a new segment needs to be created. In the perfect rollup mode, all new segments should be allocated with a proper shardSpec at once before writing data into segments. To sum up, Lock granularity | Rollup mode | Segment allocation algorithm -----------------|-------------|----------------------------- segment lock | best-effort rollup | Centralized incremental segment allocation. Whenever a task sends a lock request for a new segment, the overlord allocates a new segmentId and creates a lock for the new segment. The segmentId allocation and lock creation are performed atomically. segment lock | perfect rollup | Centralized bulk segment allocation. The task sends lock requests for all new segments before it starts writing segments. timeChunk lock | best-effort rollup | Local incremental segment allocation. The task allocates a new segmentId on its own whenever it needs. timeChunk lock | perfect rollup | Local bulk segment allocation. The task allocates all new segmentIds on its own before it starts writing segments. ### Changes in `TaskLockbox` `TaskLockbox` should support both timeChunk locks and segment locks. It checks the followings to detect lock collisions. - A single exclusive lock (either timeChunk lock or segment lock) can exist for a timeChunk. - Two or more shared locks regardless of the lock granularity can exist for a timeChunk. - Lock requests are idempotent only when they have the same `groupId`, `interval`, and `lockGranularity` (timeChunk or segment). Since segment allocation and lock creation should be performed atomically, the taskLockbox is also responsible for allocating new segmentIds. When a task sends a lock request, it explicitly specifies the partitionId for the new segment. The taskLockbox checks if the request is for a new segment and allocates it. Note that the segment allocation in taskLockbox can happen only for segment locks. ### Timeline management The new timeline extends the capability of the existing timeline algorithm based on the versioned intervals; the timeline first compares the segment version and then checks their `startRootPartitionId`, `endRootPartitionId`, and `minorVersion` to find the overshadowing relation between them. <img width="981" alt="overshadow graph" src="https://user-images.githubusercontent.com/2322288/45275474-e6b92e80-b471-11e8-9150-21b48c70b03a.png";> The above figure shows an example of consecutive compactions. Let me suppose the below scenario. 1) A batch task created the segments 1, 2, and 3. 2) A compaction task merged segment 2 and 3 to segment 4. At the same time, a kafkaIndexTask created segment 5. 3) A compaction task created segments 6 and 7 by mixing segments 4 and 5. At the same time, a kafkaIndexTask created segment 8. The overshadowing relation of the created segments can be represented as a graph as seen above. After `3.`, only segments 1, 6, 7, and 8 are visible. To check the overshadowing relation, `startRootPartitionId`, `endRootPartitionId`, and `minorVersion` are compared: a segment _S1_ overshadows another segment _S2_ if `S1.startRootPartitionId <= S2.startRootPartitionId && S1.endRootPartitionId >= S2.endRootPartitionId && S1.minorVersion > S2.minorVersion`. Note that the rootPartition range can only be merged (when merging segments) and thus the rootPartition range of the segment of a higher minorVersion should include that of the segment of a lower minorVersion. Coordinators and brokers should be able to update their timeline incrementally whenever a historical announces/unannounces a segment. A new or removed segment can cause the state transition of atomicUpdateGroups. AtomicUpdateGroups can have 3 different states in the timeline. - standby: some segments of an atomicUpdateGroup are available in servers but others are not yet. AtomicUpdateGroups in this state are not queryable. - visible: all segments of an atomicUpdateGroup are available and queryable. - overshadowed: segments of an atomicUpdateGroup are overshadowed by another fully available atomicUpdateGroup. AtomicUpdateGroups in this state are not queryable. When a new segment is added, the state of its atomicUpdateGroup can be either `standby` or `overshadowed`. Then, it can be changed as below. 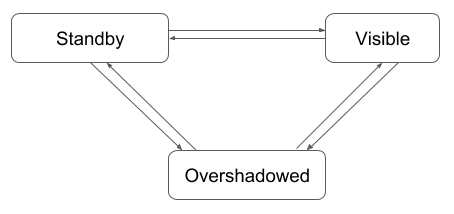 - A standby atomicUpdateGroup becomes visible when its all segments are available. - A standby atomicUpdateGroup becomes overshadowed when a new segment of another atomicUpdateGroup is added which overshadows the standby one. - A visible atomicUpdateGroup becomes standby when one of its segments is removed and there is an overshadowed atomicUpdateGroup which is fully available (see the below condition for overshadowed segments to become visible). - A visible atomicUpdateGroup becomes overshadowed when a new segment of another atomicUpdateGroup is added which overshadows the visible one. - An overshadowed atomicUpdateGroup becomes visible when one of the following conditions is met. - All segments in the atomicUpdateGroup which overshadows this atomicUpdateGroup is removed. - A segment in the atomicUpdateGroup which overshadows this atomicUpdateGroup is removed and all segments of this atomicUpdateGroup are available (see the above condition for visible segments to become standby). - An overshadowed atomicUpdateGroup becomes standby when all these conditions are met. - The entire atomicUpdateGroup which overshadows this atomicUpdateGroup is removed. - Some segments of its atomicUpdateGroup are not available - There is an overshadowed atomicUpdateGroup which is fully available and overshadowed by this atomicUpdateGroup. Note that we can check that atomicUpdateGroup is fully available by checking there are available segments of `atomicUpdateGroupSize` which have the same `minorVersion`. #### Incremental update for new segments This algorithm is called whenever a new segment is added to a timeline. For example, a new segment is loaded by a historical, the segment is newly added to brokers' timeline. - Compares the version of the new segment with other segments of overlapping intervals. - If the new segment has a higher version than others, only the new segment is `visible`. - If the new segment has the same version and the same interval with existing segments, decides its state according to the above state machine. #### Incremental update for removed segments This algorithm is called whenever an existing segment is removed from a timeline. For example, if a historical becomes unavailable, all its segments are removed from brokers' timeline. Unlike adding new segments, removing segments should consider falling back to previous generation of atomicUpdateGroups. Suppose two segments, A and B, and the segment A overshadows the segment B. When the segment A is removed but the segment B is still available, the broker should be able to route queries to the historical serving the segment B. - Remove a segment from the timeline. - If the removed segment was `visible`, check its overshadowed segments. - If all overshadowed segments are in `overshadowed` state, all segments in atomicUpdateGroup of the removed segments are atomically swapped with its overshadowed segments. - Otherwise, for each segment in the overshadowed segments of the removed segment, repeat the above step until any swappable atomicUpdateGroup is found. - If any swappable atomicUpdateGroup is not found, changes nothing. ### Rationale #### Expected limitations of the proposed method Minor compaction might not be able to compact some segments if they don't meet the restrictions in "Encoding overshadowing relation in Data Segment" section. For example, in the worst case, minor compaction can't compact any segments if a small segment and a big segment appear alternately. This case must be handled by major compaction. #### Rejected Alternatives There are two rejected alternatives. ##### The first proposal for background compaction https://github.com/apache/incubator-druid/issues/4434 ##### Storing all overshadowed segments in `overshadowedSegments` of `DataSegment` Unlike in the proposal, we can store all partitionIds of the overshadowed segments in `overshadowedSegments` set. Since `overshadowedSegments` has all overshadowed segments in it, we can check one segment overshadows another by simply checking their `overshadowingSegments` contain each other. This would be simpler than traversing the graph of overshadowing relation. However, since `overshadowedSegments` would always grow as new segments which overshadow existing segments are added, it would take too much memory. ##### Representing the shallow overshadowing relation as comparing numbers In this alternative, a partition of a segment is represented by a range of fraction, i.e., `startPartitionId` and `endPartitionId`. For appending tasks, the partitions of new segments are increased by 1 like `[0, 1), [1, 2), ...`. In overwriting tasks, the partitionId of each segment is `(endPartitionId of last partition - startPartitionId of first partition) * i / (# of output partitions)` where `i` is the index for new segment. For example, suppose there are 3 segments of partitionIds `[0, 1)`, `[1, 2)`, and `[2, 3)`. If an overwriting task reads these segments and generates 2 segments, the new segments would have partitionIds of `[0, 3/2)` and `[3/2, 3)`. Since a fraction can theoretically represent any number, any partition can be represented by a pair of fractions no matter how many times the partition has been split. This is dropped because it can't represent the overshadowing relation properly. For example, `[0, 1)` should be overshadowed by `[3/2, 3)` because the later segment is created from the former but it's not possible without additional information. ##### Representing the shallow overshadowing relation as a set In this alternative, each segment stores a set of segments which are directly overwritten by that segment. For example, if a segment _S1_ is created by merging _S2_ and _S3_, then _S1_ stores the partitionIds of _S2_ and _S3_ in its `overshadowedSegments` set. Since `overshadowedSegments` stores references to overshadowing segments, we can compose an overshadowing graph. See https://github.com/apache/incubator-druid/issues/6319 for more details. This alternative is dropped because it's possible that some segments in the middle of the overshadowing graph are missing in brokers which needs additional complicated handling. ### Test plan - Will add unit tests for changed codes. - Existing integration tests would verify segment locking. - Will test in a real cluster. ### Future work (optional) Major compaction is to complement minor compaction. It will use the parallel index task which locks entire timeChunks of input segments to create fully optimized, perfectly rolled-up segments. To do this, the parallel index task should support shuffle first proposed in https://github.com/apache/incubator-druid/issues/5543. Maybe it would be worth to add another type of compaction, semi-major compaction, which is similar to the major compaction but uses segment lock. So, it would still try to generate more optimized segments than minor compaction, but stream data can be appended while semi-major compaction is in progress for the same timeChunk. Major, semi-major, minor compactions would be automatically scheduled by the coordinator. Minor and semi-major compactions will be performed as soon as new compactible segments are found. The semi-major compaction would be scheduled less frequently than minor compaction. Major compaction will be performed after minor & semi-major compactions are finished. It will use `offsetFromLatest` configuration to find the start point to search for segments to compact.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]