jihoonson commented on issue #7547: Add support minor compaction with segment locking URL: https://github.com/apache/incubator-druid/pull/7547#issuecomment-511966275 @clintropolis I ran some benchmark and here are some results. The benchmark code is available in [my branch](https://github.com/jihoonson/druid/blob/minor-compaction-benchmark/benchmarks/src/main/java/org/apache/druid/timeline/VersionedIntervalTimelineBenchmark.java) and will raise another pr for it after this PR is merged. Please note that this benchmark doesn't compare the performance of `VersionedIntervalTimeline` of this PR with that of the master branch. The primary purpose of this benchmark is to measure how slow `VersionedIntervalTimeline` is with segmentLock after this PR. (When timeChunk lock is used, `VersionedIntervalTimeline` performs a bit more operations such as creating an `OvershadowableManager` of a single partitionChunk than that of master. However, the overall performance wouldn't be much different.) TL;DR `VersionedIntervalTimeline` is slower with segment lock than that with timeChunk lock, but it's still acceptable. ### Data setup A synthetic segments were created to emulate the usual compaction scenario where initial segments are created and then they got compacted while new segments are appended. The benchmark first generates `numInitialRootGenSegmentsPerInterval` segments per interval. Then, it generates `numInitialRootGenSegmentsPerInterval * COMPACTED_SEGMENTS_RATIO_TO_INITIAL_SEGMENTS` compacted segments which overwrites the segments of the previous generation. It also generates new appending segments. This can be repeated more than once based on `numNonRootGenerations`. Here, I pasted only some of results, e.g., when segmentGranularity = MONTH or # of non-root generations = 5, because they look similar. In every graph, blue and red represent throughput when using timeChunk lock and segment lock, respectively. Line charts show the throughput with varying # of total segments (including overshadowed ones). The _log scale_ is used for y axis of all line charts. The bar charts just show the one data point in line charts where # of segments = 160 which is the number Druid dataSources usually have per timeChunk. #### Lookup 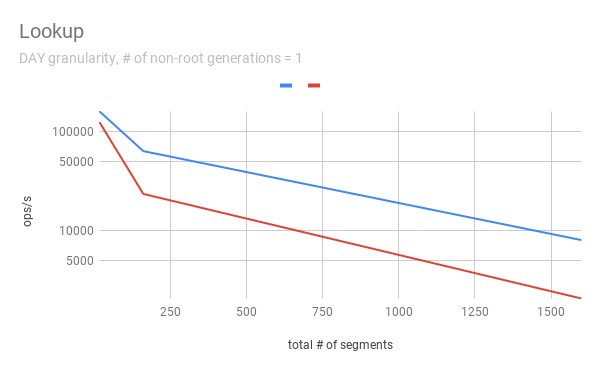 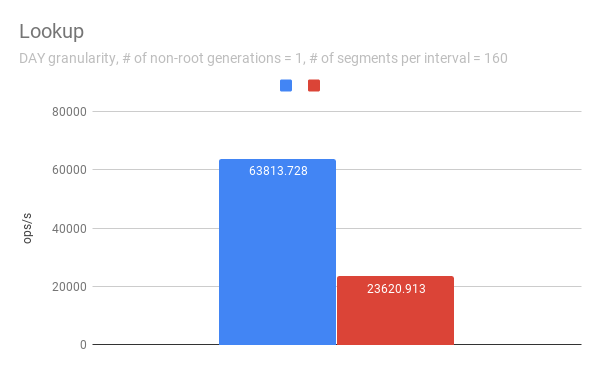 To measure the throughput of the `lookup` method, the benchmark picks up a random interval which spans 3 time chunks based on segmentGranularity. This result says the timeline is pretty faster with timeChunk lock than using segment lock. But 23620.913 ops/s is still fast. Regarding peak CPU usage, there's no big difference between using timeChunk lock and segment lock. #### FindFullyOvershadowed 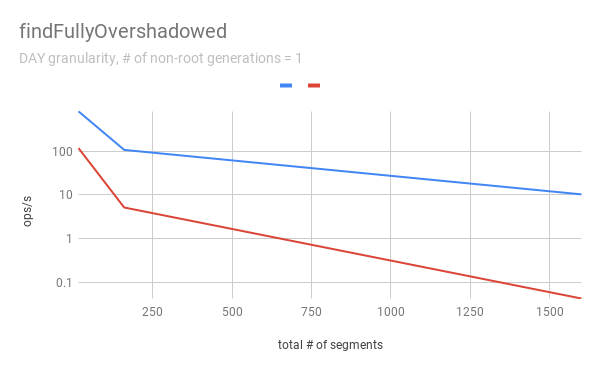 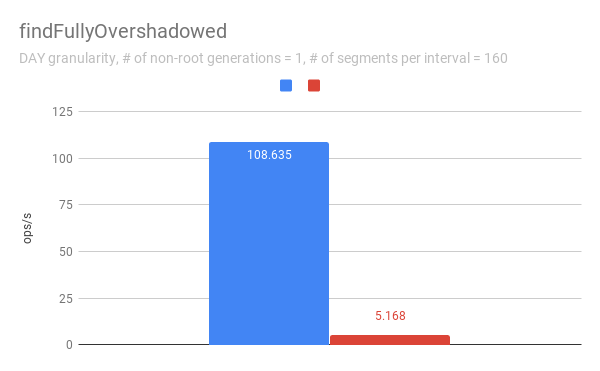 `findFullyOvershadowed` is very slow with segmentLock. This is because the implementation is not very optimized, especially the constructor of `PartitionHolder`. Here is the code snippet. ```java public PartitionHolder(List<PartitionChunk<T>> initialChunks) { this.overshadowableManager = new OvershadowableManager<>(); for (PartitionChunk<T> chunk : initialChunks) { add(chunk); } } ``` This could be improved by adding a bulk construction of OvershadowableManager, but `findFullyOvershadowed` is called only one place in production code, i.e., `ParallelSubIndexTask`. I think it could be done later rather than in this PR. #### IsOvershadowed 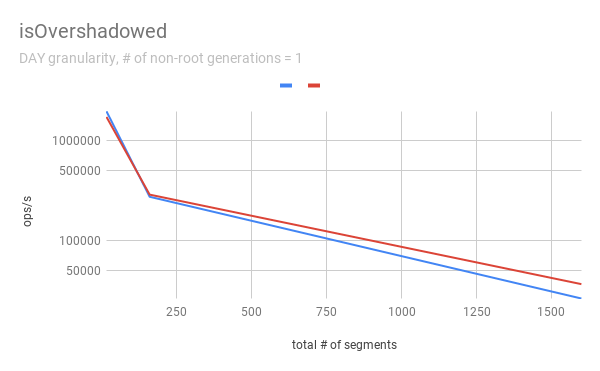 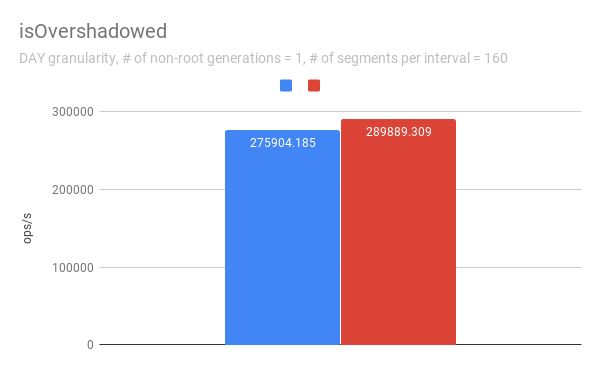 `isOvershadowed` shows a pretty similar throughput. The benchmark chooses a random one among timeChunks populated based on segmentGranularity. As a result, the benchmark always executes the below part in `isOvershadowed` method. ```java TimelineEntry entry = completePartitionsTimeline.get(interval); if (entry != null) { final int majorVersionCompare = versionComparator.compare(version, entry.getVersion()); if (majorVersionCompare == 0) { for (PartitionChunk<ObjectType> chunk : entry.partitionHolder) { if (chunk.getObject().isOvershadow(object)) { return true; } } return false; } else { return majorVersionCompare < 0; } } ``` Since the number of visible segments to be iterated in the for loop is same with timeChunk and segment locks, their throughput should be similar. #### Add 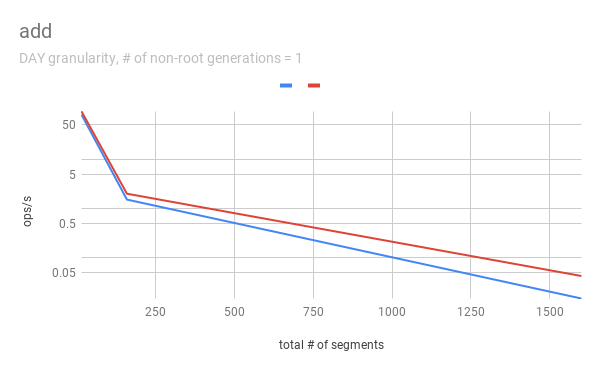 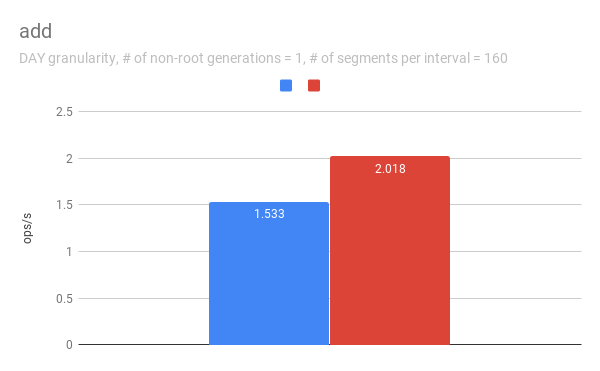 For `add`, it's faster with segment lock because I think `TimelineEntry` should be created for each new segment of new major version. When using segment lock, new segment of new minor version can be added into the same `TimelineEntry`. #### Remove 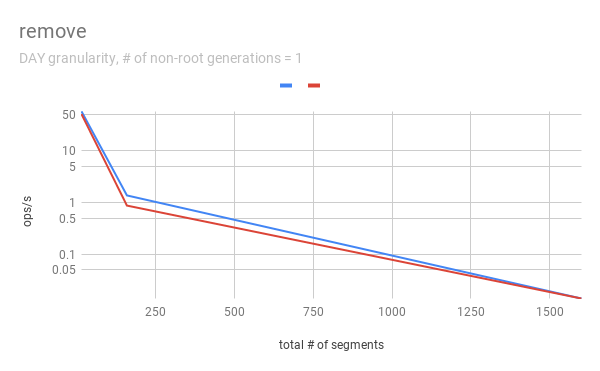 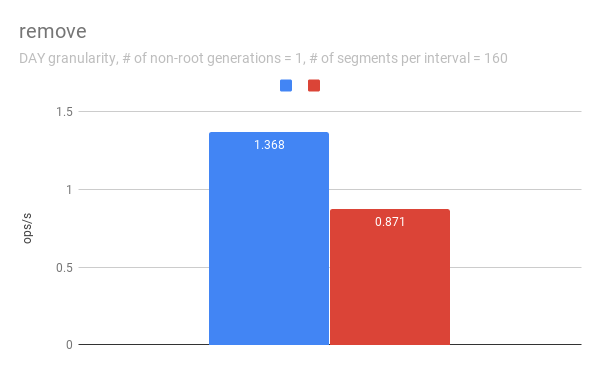 `remove` is slower with segment lock. This is expected since whenever a visible segment is removed, `OvershadowableManager` needs to check all overshadowed atomicUpdateGroups to determine the visible one.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]