tejaskumar-cm opened a new issue #11371: URL: https://github.com/apache/druid/issues/11371
Hi Team, We are extracting and storing events in druid. In a day there will be nearly **6 million records**, which is of size **9GB/day**, and there are around **200 columns** in the table. We are storing the data directly connecting to kafka and facing no problems in storing the data in druid. But when we are trying to retrieve this data using Druid SQL query, we are getting error and **not even able to query 1 million record** at a time. We tried different druid configuration as per the doc, but nothing helped us. **Can anyone guide us through the master, query and data server capacity required to handle this much of data, and also the druid configuration of each servers respectively?** I tried to find solution in different forum and didn't get any solution and hence I am posting a message here. Below I have attached some error I saw when I ran the query. 1) Console error 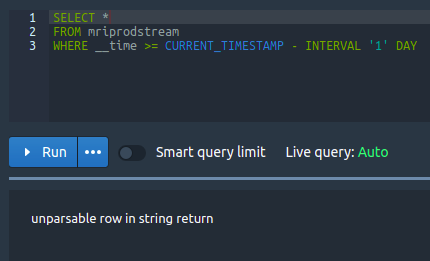 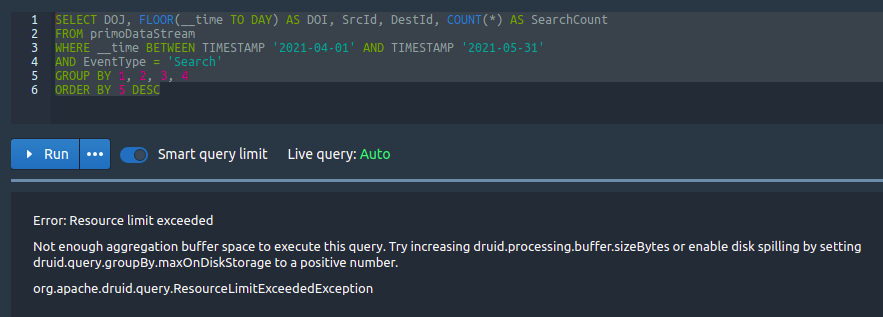 2) Druid broker.log  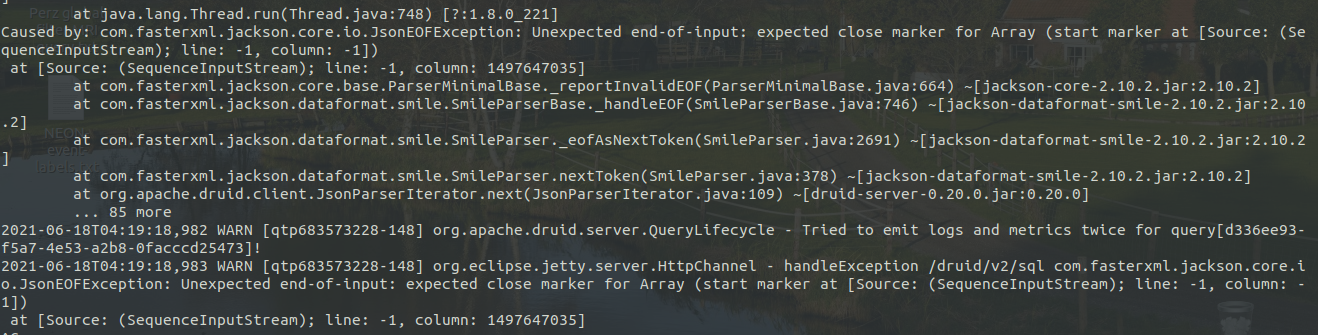 3) historical.log  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}