wangxiaobaidu11 commented on pull request #12159: URL: https://github.com/apache/druid/pull/12159#issuecomment-1038724386
@JulianJaffePinterest hi, I import a month's data to druid by spark connector. The data is partitioned by day. The number of lines per segment is in the tens of millions. 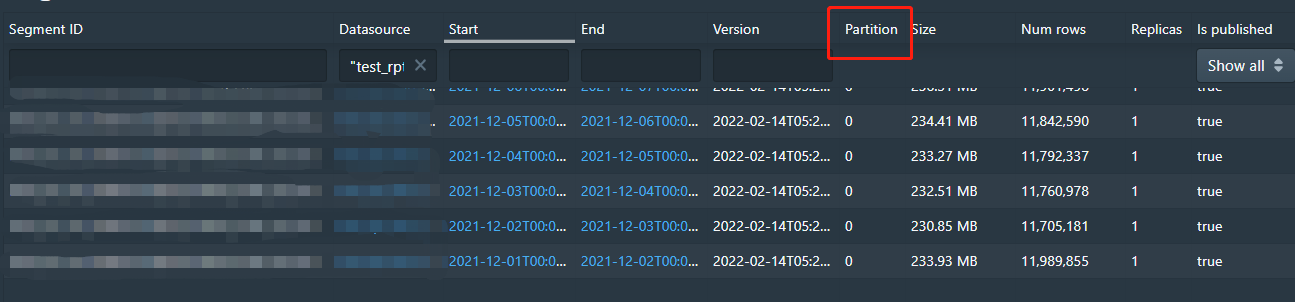 In my tests, I found that the import job took about an hour. How can I speed up the import? Whether the segment can be split into numShard format for import? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}