wangxiaobaidu11 edited a comment on pull request #12159:
URL: https://github.com/apache/druid/pull/12159#issuecomment-1042657139
@JulianJaffePinterest I tested it this way
`Dataset<Row> dataset = sparkSession.createDataFrame(list, schema);`
` Dataset<Row> bucketedDataset =
dataset.withColumn("quick_col",SparkUdfs.bucketRow().apply(functions.col("_timeBucketCol"),functions.lit("millis"),functions.lit("DAY")));`
` Dataset<Row> partitionedDataSet1 =
bucketedDataset.repartition(functions.col("quick_col")).drop(functions.col("quick_col"));`
` Dataset<Row> partitionedDataSet2 =
partitionedDataSet1.repartition(10);` // Increase parallelism
`
partitionedDataSet2.write().format("druid").mode(SaveMode.Overwrite).options(map).save();`
but in log I find it :


I think it should be five segments, but only two segment
Corresponding code block:
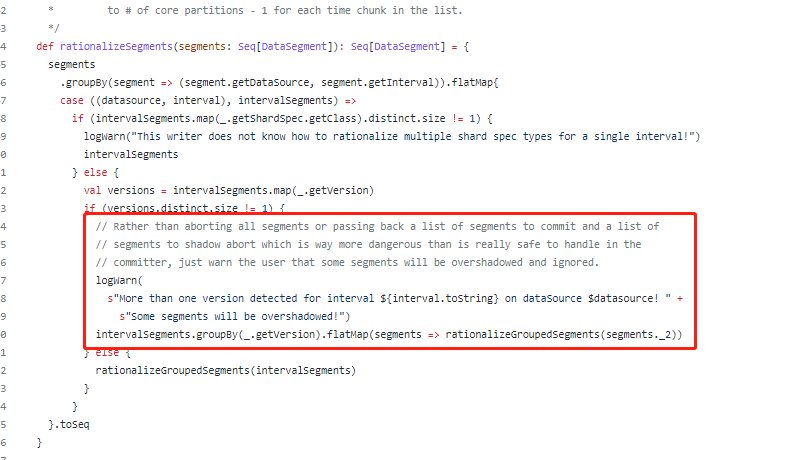
Code url:
https://github.com/JulianJaffePinterest/druid/blob/2dd1cda37289b780328e26d08bedfb1f57bac0e3/spark/src/main/scala/org/apache/druid/spark/utils/SegmentRationalizer.scala
What configuration items do I need to modify ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}