kfaraz opened a new issue, #12881: URL: https://github.com/apache/druid/issues/12881
## Motivation Segment loading is one of the more complicated pieces of Druid operations and is prone to failures and race conditions. Due to lack clean logs and metrics, it is often very difficult to debug too. ## Identified issues and proposed changes Discussed below are a few issues with the current implementation and possible fixes that can help improve the coordinator operation. ### 1. Balancing always causes over-replication! **Problem:** While moving a segment from server A to B, the load succeeds on B but the drop on A is never invoked. This happens because the server inventory view maintained by the coordinator may still not be updated when the drop callback comes. Under normal circumstances, this is not noticeable because load rules quickly drop the over-replicated segments. But if load rules get stuck for some reason, the number of over-replicated segments keeps increasing thereby overloading historicals. 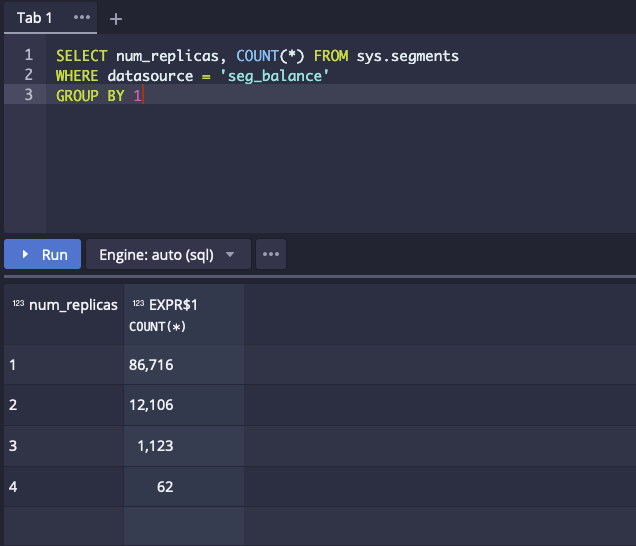 **Proposed fix:** 1. Do not check the server inventory to determine if the drop should be invoked. 2. Use the HTTP status (applicable only to `HttpLoadQueuePeon`) received from the change request to determine if the load was successful or not. 3. Provide a success as well as a failure callback to the `LoadQueuePeon`. ### 2. Changes to `replicationThrottleLimit` **Definition:** > The maximum number of segments that can be replicated at one time. The main aim of throttling replication is to avoid a stampede when a server suddenly disappears. It is possible that the server is temporarily invisible to the coordinator due to ephemeral network issues. In such scenarios, the load queue should not be completely filled up with replicas which might appear soon after. **Problem 1:** This design considers replication on a cluster level, rather than a tier level. Ideally, if load rules determine that a segment should be available on a tier, the segment should be quickly loaded there. Relying on data existing on other tiers kind of defeats the purpose of tiering. **Proposed fix:** 1. Do not consider the first copy of a segment on a tier as a replica and do not subject it to replication throttling. At the start of every run, a tier is considered eligible for replication only if there is no pending replication in that tier. Based on the `replicationThrottleLimit`, we add items to the replication queue during the course of `RunRules`. **Problem 2:** While rules are executing, the replication queue might free up as replicas get successfully loaded. The rules misinterpret this situation as the `replicationThrottleLimit` not having been met and queue up more replicas. In some situations, this can go on for a very long time increasing the duration of a now stale coordinator run cycle. **Proposed fix:** 1. Clarify the definition of the `replicationThrottleLimit` as `The maximum number of segment that can be queued up for replication in one coordinator cycle.` 2. Determine `replicationThrottleLimit` at the start of the run for each tier. Compare the number of segments assigned for replication in this run rather than the current queue size against the `replicationThrottleLimit` to determine if the limit has been reached. ### 3. Drops happen only after target replication is met on every tier **Problem:** The target replication level on a new tier might be high and would be subject to replication throttling. Drop of an unneeded replica should not have to wait on this. **Proposed fix:** Drop over-replicated segments as soon as a single replica of the segment is available on every required tier. ### 4. Only loaded segments count towards over-replication Changes in item (2) above ensure that segments assigned freshly to a tier would not be subject to replication throttling anymore. This implies that when a server disappears temporarily (due to intermittent network issues), segments whose only copy in this tier was on the disappeared server would quickly be reassigned to other servers. It's possible that the server then reappears soon after. In the current implementation, all the items in the load queue would finish loading and only then would the rules realise that there is an over-replication. This could take several cycles to happen and would unnecessarily block other important load operations. **Proposed fix:** 1. Consider a segment as over-replicated if `loaded + loading > required` in any tier. 2. While dropping over-replicated segments, look first in the loading queues. If found, cancel the loading operation. Otherwise, drop one of the loaded segments. ### 5. Segments being balanced may count towards over-replication As a consequence of the fix in item (4) above, segments that are in the loading queue for balancing might be viewed as over-replicated. **Proposed fix:** 1. Maintain a marker to distinguish between "moving" segments and "loading" segments. 2. Do not consider "moving" segments while computing replication level or while cancelling load operations to fix over-replication. 3. For all other purposes, continue to treat "moving" and "loading" segments as the same. ### 6. Historicals can get overassigned During the course of a coordinator run, the available space on a server is not updated even when a load completes. This is because a snapshot of the cluster is taken at the start of the run and the coordinator duties use this snapshot to make assignment decisions. **Proposed fix:** 1. Maintain the current size and max size of every server inside the `HttpLoadQueuePeon`. 2. Refresh this value at the start of every run. 3. `HttpLoadQueuePeon` already maintains the size of items currently in queue. 3. As soon as an item in the load/drop queue succeeds, update the current size. 4. Add a method `boolean canLoad(DataSegment segment)` which checks both the current size, the queue size and the `maxSegmentsInNodeLoadingQueue` to determine if a segment can be loaded. Currently, both the `LoadRule` and `BalanceSegments` have to account for the space available on a server and its loading queue to determine if a segment can be assigned to a server. The new method `canLoad` would simplify this logic. Hopefully, we would also be able to phase out `maxSegmentsInNodeLoadingQueue` after this. ### 7. Changes to `cachingCost` balancer strategy **Problem:** There are some ways in which `cachingCost` differs from `cost` balancer strategy. 1. It does not subtract the cost of segments about to be dropped. 2. It has a correction factor of `maxSize / availableSize` which is supposed to work for heterogeneous historicals but causes issues with homogeneous historicals. **Proposed fix:** 1. Subtract the cost of segments marked to be dropped. 2. Remove the correction factor from `cachingCost`. This means that clusters with heterogeneous historical sizes in the same tier should use `diskNormalized` and should avoid both `cost` and `cachingCost` strategies. ### 8. Balancing skips unused segments but not overshadowed segments **Problem:** The duty `MarkAsUnusedOvershadowedSegments` marks overshadowed segments as unused. But unfortunately, the `BalanceSegments` is unable to use this information as it works off of an older snapshot. **Proposed fix:** This can be easily remedied by updating the list of used segments maintained by the `CoordinatorRuntimeParams` whenever a segment is marked as unused. ### 9. Logging and metrics Load rules currently flood the logs with cryptic info which hardly provides any assistance while debugging a stuck load. We should clean up the logs and provide verbose info only on debug or trace levels. Some new metrics should also be added to track the following info: 1. Number of items currently in the replication queue. 2. Number of cancelled load operations. 3. Average time taken for cost computation of each segment. ## Current work status I am working on the changes for the above fixes and will publish the PRs soon. ## Further improvements Alongwith these, there are other areas that require improvement to make segment loading more robust and reliable. 1. A single rule run can sometimes take a lot of time (upto hours). This is highly undesirable as the rules would be using a stale metadata snapshot and keep making incorrect decisions. Ideally, the coordinator should make short and quick decisions and keep dynamically correcting itself. Most of this time is spent in cost computation, as can be easily verified by using a `RandomBalancerStrategy`. An in-depth comparison of cost strategies and identification of possible improvements would go a long way to improve balancing and loading. 2. The cache used by `cachingCost` balancer strategy is constructed freshly at the start of every coordinator cycle. The advantage that `cachingCost` seems to offer over `cost` is that you would need to compute the cost for a segment only against the relevant interval buckets rather than all the segments. But the cost of all the segments is anyway computed at the start while building the cache. Since the number of segments for which cost is to be computed is typically much lower than the total number of segments, this does not offer any real advantage. An improvement could be to maybe reuse the cache across coordinator runs if possible or atleast populate the cache lazily for interval buckets when they are needed. 3. The `replicationThrottleLimit` considers the _number_ of replicas rather than their size to throttle replication. Ideally, this throttling should try to ensure that only a certain percentage (based on size) of the segments that each historical of a tier currently houses are considered for replication in each run. This value can be determined for each tier at the start of the run. Using this approach, we should be able to eventually phase out this config. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}