paul-rogers commented on issue #11933: URL: https://github.com/apache/druid/issues/11933#issuecomment-1272429473
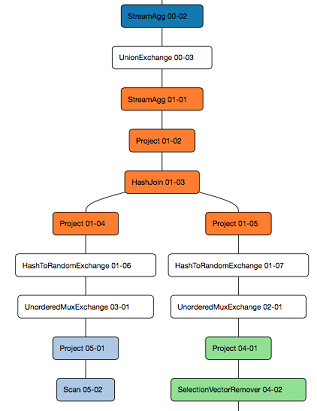
@FrankChen021, thanks for the link! Yes, the proposal is based on the pull model _within_ each fragment. When we get to distribution (i.e. "multi-stage"), we envision a _push_ model between fragments. That way, we get the simplicity of the pull model with the performance of the push model. To explain this a bit more, let's remember that, in a distributed system, we don't run the entire operator DAG single-threaded: we slice the query into fragments, perhaps on the same node, more typically across multiple nodes. (Druid's scatter/gather is the simplest possible distributed DAG: it has two slices.) The Drill version of this idea is explained [here](https://drill.apache.org/docs/drill-query-execution/). Within a fragment, operators work using the Volcano pull model. The code for this is quite simple as is illustrated by the operators in the PR. Each operator is stateful: it does the work to return one row (or, more typically, one batch) reading as many input rows as it needs. It is trivial to order the inputs, starting them one by one as in a union. The push model is common in search engines, I understand. However, it becomes quite complex once one has multiple branches (i.e. joins, unions, etc.). Suppose we have a single-thread DAG with a join. We've got two leaves, both of which want to push data up to the join. But, a hash join, say, wants to first read the build side, only later the probe side. This is trivial with the Volcano model, but quite messy with pull. As it turns out, I once worked on a query engine that used the push model: it was, indeed, quite complex. Far more complex than the Volcano model of Drill and Impala. The benefit of pull is concurrency: each fork in the DAG pretty much demands to be run in a separate thread (or process or node), with some kind of queue-based exchange between operators. If only Druid were written in Go: we'd get the pull model for free! Otherwise, we get this benefit in the Volcano model by introducing distribution. But, what we distribute are _slices_ of operators, not individual operators. Each running slice is a _fragment_. (Scan slices, for example may be replicated dozens or hundreds of time, each of those copies is a fragment.) The way we visualize this idea is with a [query profile](https://drill.apache.org/docs/query-profiles/). Here is a [typical one](https://drill.apache.org/images/docs/vis_graph.png) from Drill. In Drill and Impala, fragments use the push model. Leaf fragments (typically scans) start running immediately and push results to their downstream fragments, pausing if the receiver queue fills. For example, in that hash join example, the build side scan fragment will pump batches to the join which builds the hash table. The probe side scan will get blocked quickly because the hash join won't read from the receive queue until the hash table is built. One can turn the Volcano push model into a pull model simply by making all fragments contain a single operator. This is, in fact, what MSQ does with its frame processors: each frame processor does a single operation. In practice, however, such a design incurs unnecessary overhead. The operator-per-fragment model is great for "big" operators such as distributed sorts, distributed aggregations, etc. (And for the native queries which MSQ runs in its frame processors.) We will find, however, that other operators are "small" and don't provide benefit when run as a separate fragment: the overhead becomes unproductive. For example, a limit, filter, or projection on top of a join: might as well do those in the same fragment as the join itself. You pointed to ClickHouse. Consider [this image](https://presentations.clickhouse.com/meetup24/5.%20Clickhouse%20query%20execution%20pipeline%20changes/#processors-1). In the proposed design, the image would normally be inverted (root at the top). There would likely be exchanges where branches converge, which is a logical place to slice the DAG into fragments. The "Expression", "Project", "Extremes" and "Limit Checking" would likely be combined into a single fragment. In short, the proposed design (borrowed heavily from other projects) proposes to combine the simplicity of the Volcano pull model for individual operators (i.e. within a fragment), with the benefits of the push model between fragments. Does this make sense? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}