jasonk000 commented on PR #12303: URL: https://github.com/apache/druid/pull/12303#issuecomment-1416201807
> Do you have a performance report that shows how this change improves the throughput by setting different values of thread count under same incoming message rate? Yes. This patch has a penalty when configured to use `parsingThreadCount=1` but, for 2 or higher, throughput is improved! 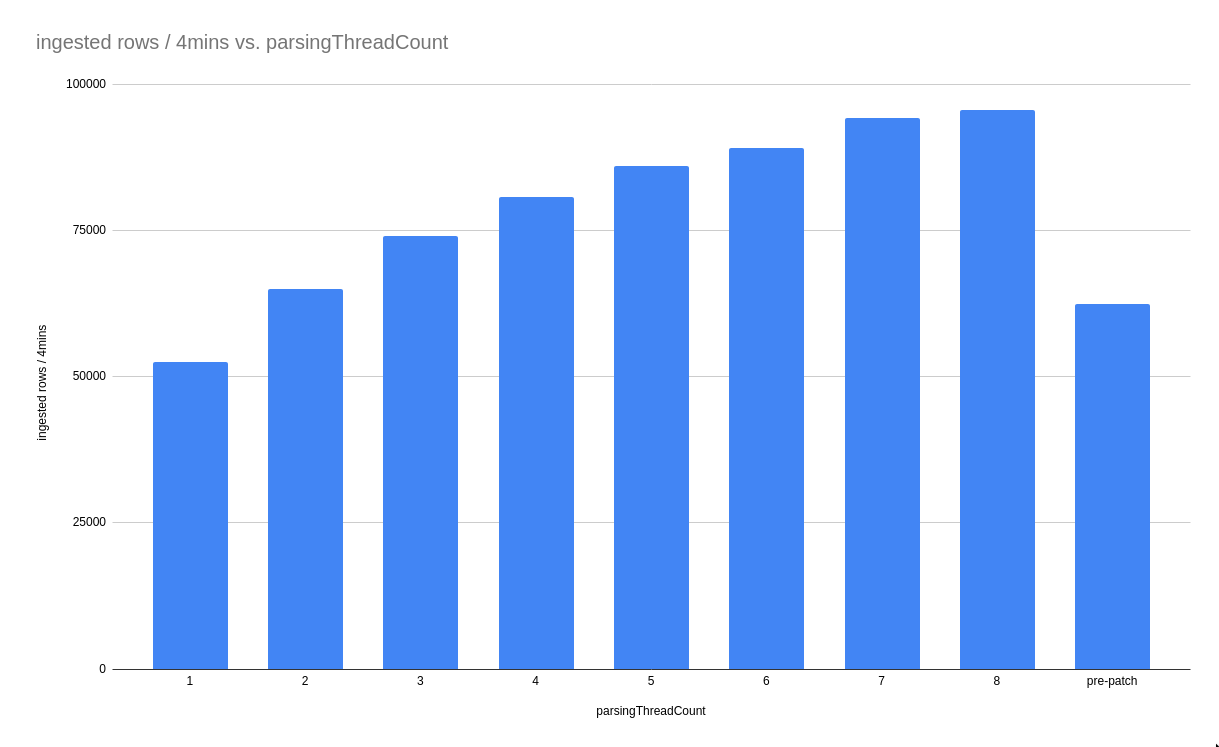 parsingThreadCount | ingested rows / 4mins | speedup -- | -- | -- 1 | 52515 | 84% 2 | 64926 | 104% 3 | 74105 | 119% 4 | 80810 | 130% 5 | 86054 | 138% 6 | 89136 | 143% 7 | 94213 | 151% 8 | 95680 | 153% pre-patch | 62372 | 100% This change moves the performance impact mostly to (1) kafka ingestion flow and (2) to index row generation focused only on the task-runner thread: before: 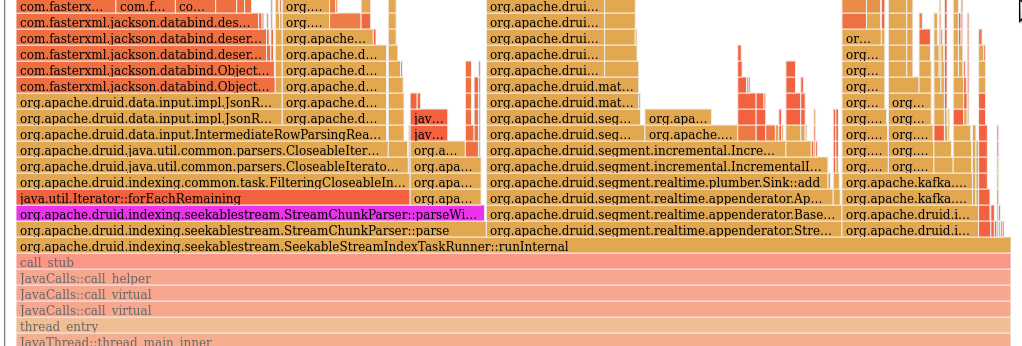 after:, notice the purple `parseWithInputFormat` is moved to this thread 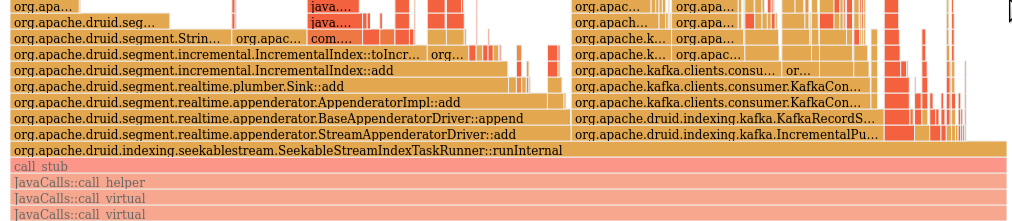 So, this makes the next bottleneck be the remainder of that loop, and any future improvements to index generator will scale up with N threads. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}