garyli1019 opened a new issue #800: Performance tuning URL: https://github.com/apache/incubator-hudi/issues/800 Hello, I am having a performance issue when I was upserting ~100GB data into a 700GB table already managed by Hudi in HDFS. The upsert part does have some duplicates with existing table because I am setting up a buffer to cover all the delta in case my spark job doesn't start on time. spark config I used(external shuffle is true as default in my cluster): ``` spark2-submit \ --conf spark.serializer=org.apache.spark.serializer.KryoSerializer \ --conf spark.network.timeout=480s \ --conf spark.executor.memoryOverhead=3g \ --conf spark.dynamicAllocation.maxExecutors=50 \ --conf spark.executor.cores=1 \ --conf spark.driver.maxResultSize=4g \ --conf spark.task.maxFailures=10 \ --conf spark.yarn.max.executor.failures=500 \ --conf spark.rdd.compress=true \ --conf spark.kryoserializer.buffer.max=1024m \ --master yarn \ --deploy-mode client \ --num-executors 20 \ --executor-memory 12g \ --driver-memory 5g \ ``` Key Hudi Configs: ``` PARQUET_SMALL_FILE_LIMIT_BYTES = 200MB PARQUET_FILE_MAX_BYTES = 256MB BLOOM_FILTER_NUM_ENTRIES = "2000000" hoodie.upsert.shuffle.parallelism = "800" ``` I am using Datasource Writer to append the delta data. I tried to use CMS garbage collector but it doesn't change too much. A 200MB parquet file has ~3-6 million records in my case. Do you have any idea how to make `count at HoodieSparkSqlWriter` faster? Thank you so much! 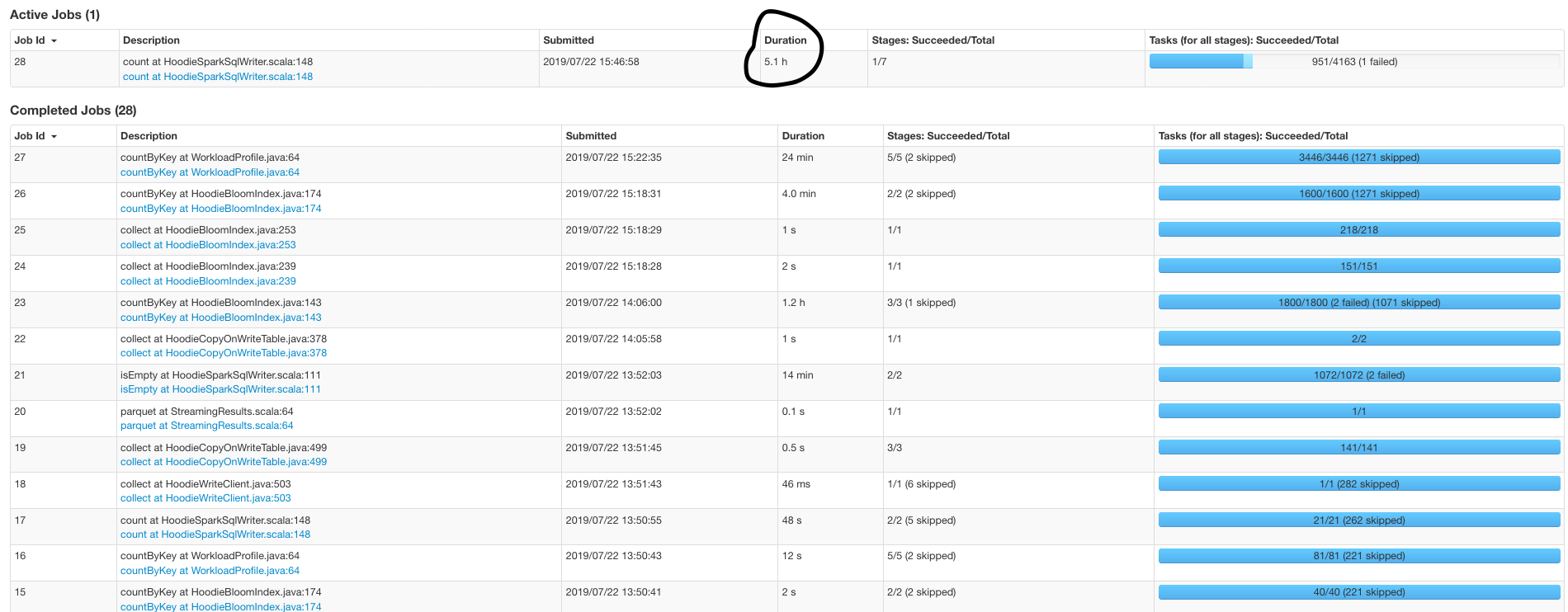 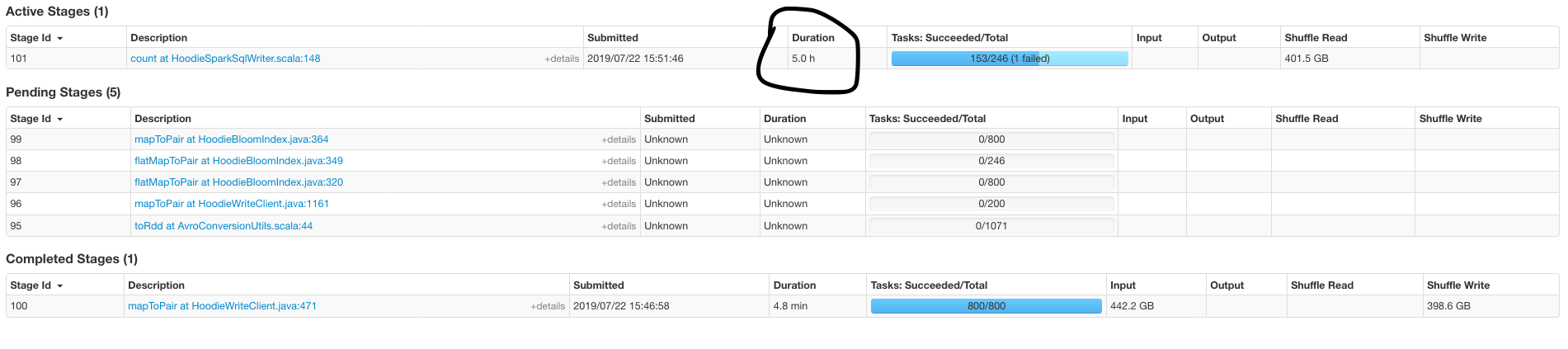 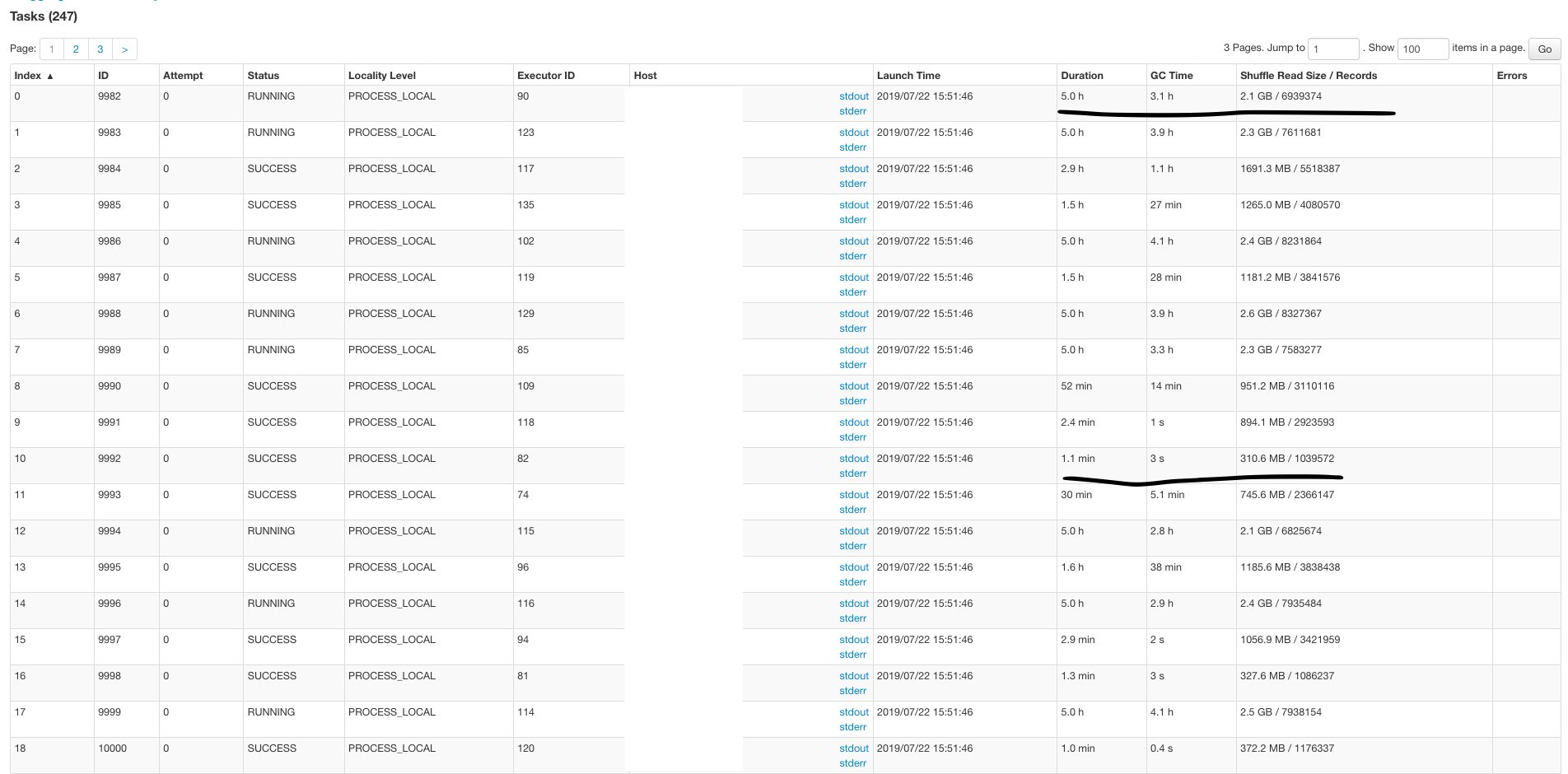
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services