adamjoneill edited a comment on issue #1325: presto - querying nested object in parquet file created by hudi URL: https://github.com/apache/incubator-hudi/issues/1325#issuecomment-585128793 thanks @lamber-ken I've updated my deploy step to remove all references to org.apache.spark:spark-avro_2.11:2.4.4 ``` aws emr add-steps --cluster-id j-xxxxxx --steps Type=spark,Name=ScalaStream,Args=[\ --deploy-mode,cluster,\ --master,yarn,\ --jars,\'/usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-streaming-kinesis-asl-assembly.jar\',\ --conf,spark.yarn.submit.waitAppCompletion=false,\ --conf,yarn.log-aggregation-enable=true,\ --conf,spark.dynamicAllocation.enabled=true,\ --conf,spark.cores.max=4,\ --conf,spark.network.timeout=300,\ --conf,spark.serializer=org.apache.spark.serializer.KryoSerializer,\ --conf,spark.sql.hive.convertMetastoreParquet=false,\ --class,ScalaStream,\ s3://xxxx.xxxx/simple-project_2.11-1.0.jar\ ],ActionOnFailure=CONTINUE ``` and i receive the following error, where no hudi file is created for a streaming record ``` 20/02/12 09:56:45 INFO BlockManagerInfo: Removed broadcast_20_piece0 on ip-10-10-10-212.ap-southeast-2.compute.internal:33453 in memory (size: 7.9 KB, free: 2.6 GB) Exception in thread "streaming-job-executor-0" java.lang.NoClassDefFoundError: org/apache/spark/sql/avro/SchemaConverters$ at org.apache.hudi.AvroConversionUtils$.convertStructTypeToAvroSchema(AvroConversionUtils.scala:80) at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:81) at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:91) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131) at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127) at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:156) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676) at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:676) at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:676) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229) at ScalaStream$.handleOrderCreated(stream.scala:39) at ScalaStream$$anonfun$main$1.apply(stream.scala:110) at ScalaStream$$anonfun$main$1.apply(stream.scala:82) at org.apache.spark.streaming.dstream.DStream$$anonfun$foreachRDD$1$$anonfun$apply$mcV$sp$3.apply(DStream.scala:628) at org.apache.spark.streaming.dstream.DStream$$anonfun$foreachRDD$1$$anonfun$apply$mcV$sp$3.apply(DStream.scala:628) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(ForEachDStream.scala:51) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply(ForEachDStream.scala:51) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1$$anonfun$apply$mcV$sp$1.apply(ForEachDStream.scala:51) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:416) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply$mcV$sp(ForEachDStream.scala:50) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply(ForEachDStream.scala:50) at org.apache.spark.streaming.dstream.ForEachDStream$$anonfun$1.apply(ForEachDStream.scala:50) at scala.util.Try$.apply(Try.scala:192) at org.apache.spark.streaming.scheduler.Job.run(Job.scala:39) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply$mcV$sp(JobScheduler.scala:257) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply(JobScheduler.scala:257) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler$$anonfun$run$1.apply(JobScheduler.scala:257) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.run(JobScheduler.scala:256) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.avro.SchemaConverters$ at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:418) at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ... 46 more ``` if i add the arvo dependency as a jar, rather than a package as above, the hudi directory and meta data is created, but no data is saved. ie missing the default directory i was expecting missing default directory  what usually appears when i include `--package org.apache.spark:spark-avro_2.11:2.4.4` 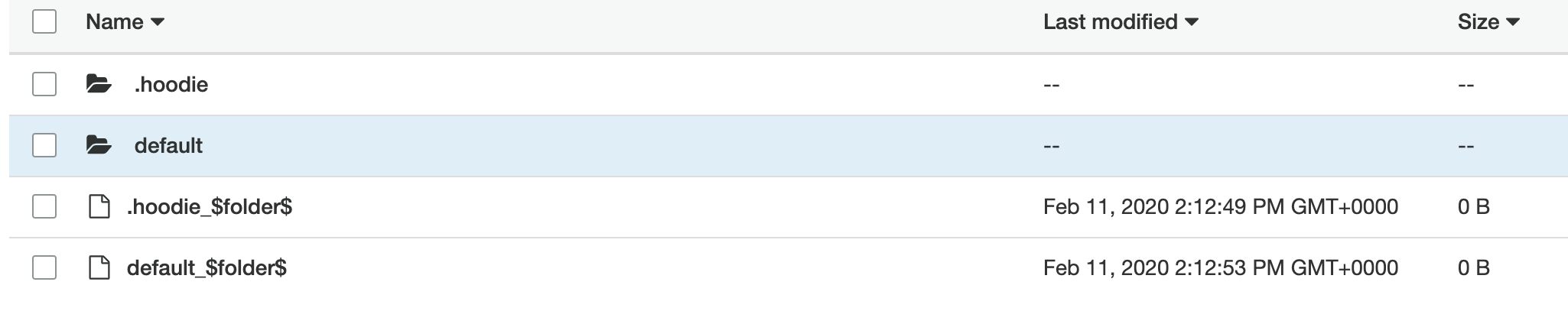 i notice the AWS blog post that has an example app running through the spark-shell uses the command line arguments `spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" --jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar` (from https://aws.amazon.com/blogs/aws/new-insert-update-delete-data-on-s3-with-amazon-emr-and-apache-hudi/) which i've tried to replicate in my application
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services