sharathkola opened a new issue, #5223: URL: https://github.com/apache/hudi/issues/5223
**_Tips before filing an issue_** - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? Yes - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** Hudi clustered table reads all the files instead of reading only clustered files generated. I have created a hudi clustered table using deltastreamer.. its command and configuration are below - aws emr add-steps --cluster-id j-3W0PJEH4IJMOB --steps Type=Spark,Name="Deltastreamer_account_t_c",ActionOnFailure=CONTINUE,Args=[--master,yarn,--deploy-mode,client,--executor-memory,10G,--driver-memory,10G,--executor-cores,5,--driver-cores,5,--jars,s3://XX/hudi/jars/spark-avro_2.12-3.1.2-amzn-0.jar,--class,org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer,s3://XX/hudi/jars/hudi-utilities-bundle_2.12-0.8.0-amzn-0.jar,--props,s3://XX/hudi/props/test/cluster/account_t.properties,--enable-hive-sync,--table-type,COPY_ON_WRITE,--source-class,org.apache.hudi.utilities.sources.ParquetDFSSource,--source-ordering-field,commit_ts,--target-base-path,s3://XX/hudi/test/cluster/account_t,--target-table,account_t,--continuous,--min-sync-interval-seconds,10,--op,UPSERT] --region us-east-1 properties file info - hoodie.datasource.write.recordkey.field=poid_id0 hoodie.datasource.write.precombine.field=commit_ts hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator hoodie.datasource.write.partitionpath.field= hoodie.write.lock.zookeeper.lock_key=account_t hoodie.datasource.hive_sync.enable=true hoodie.datasource.hive_sync.database=hudi_c hoodie.datasource.hive_sync.table=account_t hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.NonPartitionedExtractor hoodie.deltastreamer.source.dfs.root=s3://XXXX/account_t/ hoodie.upsert.shuffle.parallelism=200 hoodie.datasource.write.row.writer.enable=true hoodie.index.type=BLOOM hoodie.bloom.index.filter.type=DYNAMIC_V0 hoodie.parquet.small.file.limit=0 hoodie.clustering.inline=true hoodie.clustering.inline.max.commits=1 hoodie.clustering.plan.strategy.target.file.max.bytes=1073741824 hoodie.clustering.plan.strategy.small.file.limit=629145600 hoodie.clustering.plan.strategy.sort.columns=poid_id0,status commit information below - 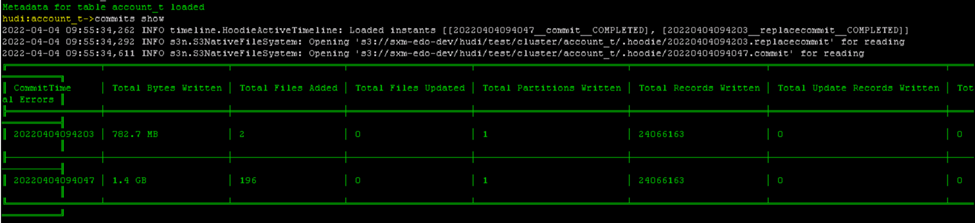 After first commit, clustering is done where 196 small files are converted into 2 larger files. I am running below query in a spark program against hudi external table– select * from hudi_c.account_t a where a.poid_id0 =1234567 In spark UI I see that all the files (196+2=198 files) are being read instead of only 2 larger files. 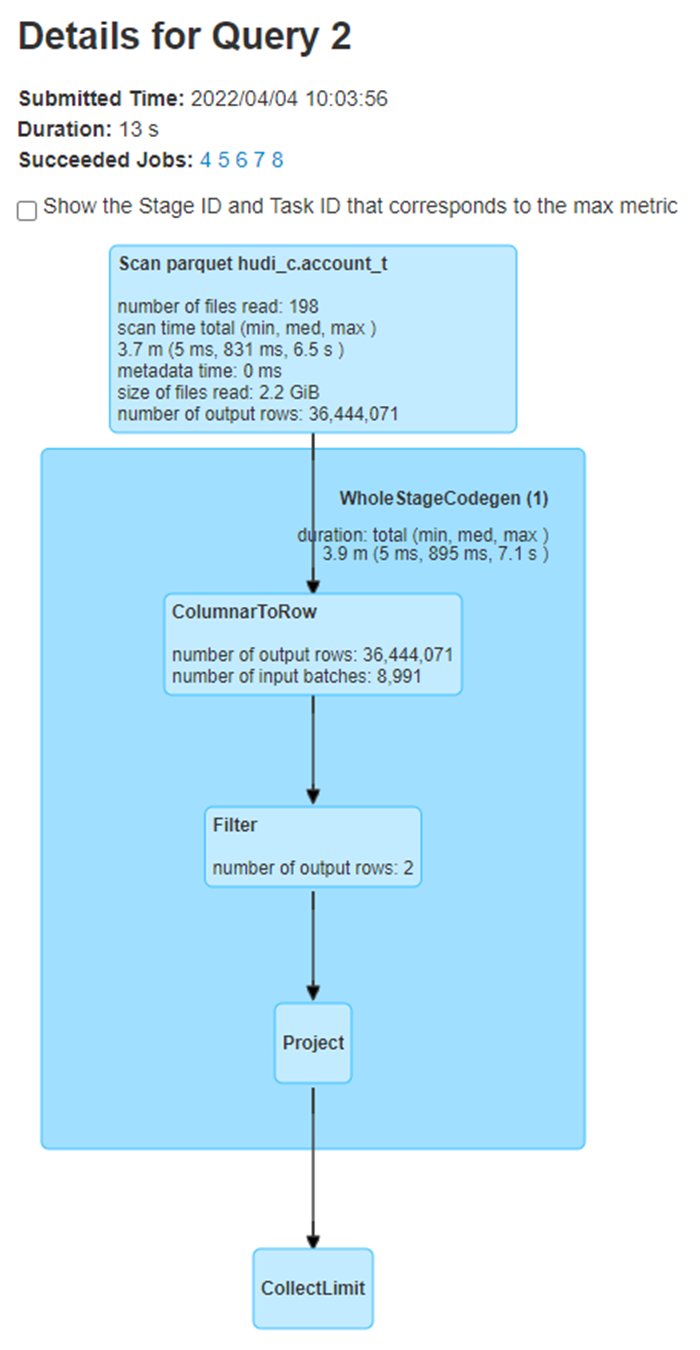 **To Reproduce** Steps to reproduce the behavior: 1. create properties file with configs as mentioned above. 2. run the deltastreamer command as mentioned above. 3. run the spark sql query mentioned above. 4. verify spark UI to see the S3 file scans **Expected behavior** Clustered hudi table should read only the new clustered files instead of all the old+new files. **Environment Description** * Hudi version : 0.8.0 * Spark version : 3.1.2 * Hive version : 3.1.2 * Hadoop version : * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** Adding a screenshot of .hoodie folder 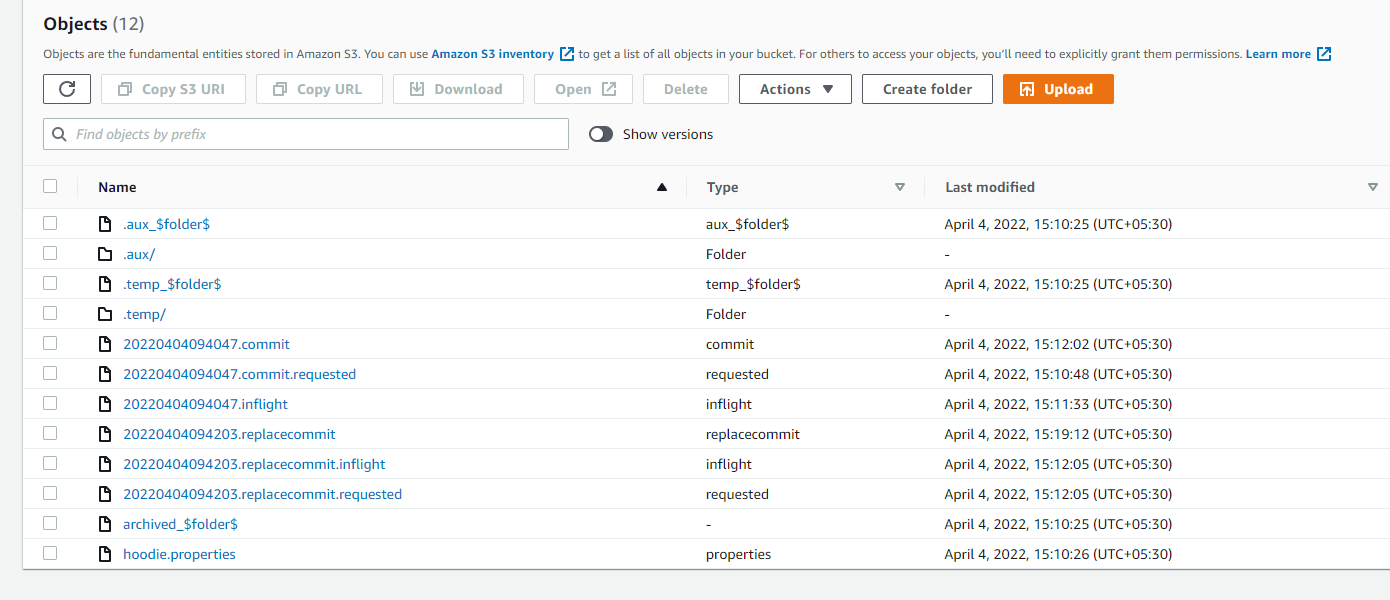 **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}