MikeBuh opened a new issue, #5481:
URL: https://github.com/apache/hudi/issues/5481
At the moment we have a setup using Spark structured streaming to read Avro
files from S3, do some basic transformation and schema cleaning, then persist
into Hudi which also resides on S3. This setup is using Spark 3.1.1 and Hudi
0.10.0 and is running on AWS EMR using emr-6.3.1. Currently this is working
fine for new incoming data (Spark app running a batch interval query to listen
for new data and process it accordingly), however recently we began facing a
performance bottleneck when we attempted to stop the real-time flow and reload
some old data as fewer but considerably larger batch. The main problem here
seems to be that the executors are running out of memory and thus causing
numerous failures in the application until the entire application shuts down.
Having said all this, can you kindly assist us with better understanding
what might be causing the bottleneck and how we would be able to overcome it?
**Data Details**
- Transactional datain Avro format, all residing on S3
- Existing table size (total): 75GB | 2,300 Objects
- Existing table size (one partition): 4.5GB | 45 Objects
- Data to upsert (total): 50GB | 2,600 objects
- Data to upsert (one batch): 7GB | 370 objects
**EMR Config**
`[
{
"classification": "yarn-site",
"properties": {
"yarn.nodemanager.resource.memory-mb": "27852",
"yarn.nodemanager.pmem-check-enabled": "false",
"yarn.scheduler.maximum-allocation-mb": "27852",
"yarn.nodemanager.vmem-check-enabled": "false"
},
"configurations": []
},
{
"classification": "spark-defaults",
"properties": {
"spark.history.retainedApplications": "100",
"spark.rdd.compress": "true",
"spark.network.timeout": "600s",
"spark.history.fs.cleaner.interval": "2d",
"spark.history.fs.cleaner.maxNum": "40",
"spark.sql.shuffle.partitions": "100",
"spark.history.fs.cleaner.enabled": "true",
"spark.history.fs.eventLog": "true",
"spark.eventLog.rolling.maxFileSize": "1g",
"spark.shuffle.spill.compress": "true",
"spark.history.fs.cleaner.maxAge": "3d",
"spark.shuffle.compress": "true",
"spark.default.parallelism": "100",
"spark.history.fs.eventLog.rolling.maxFilesToRetain": "5",
"spark.serializer": "org.apache.spark.serializer.KryoSerializer",
"spark.executor.memoryOverhead": "2680m",
"spark.executor.instances": "10",
"spark.task.maxFailures": "11",
"spark.executor.memory": "24100m",
"spark.driver.memory": "24100m",
"spark.kryoserializer.buffer.max": "128m",
"spark.yarn.scheduler.reporterThread.maxFailures": "5",
"spark.eventLog.rolling.enabled": "true",
"spark.driver.cores": "5",
"spark.executor.heartbeatInterval": "30s",
"spark.executor.cores": "5",
"spark.memory.storageFraction": "0.6",
"spark.sql.session.timeZone": "UTC",
"spark.driver.memoryOverhead": "2680m",
"spark.yarn.max.executor.failures": "12",
"spark.memory.fraction": "0.7",
"spark.executor.extraJavaOptions": "-Xloggc:/var/log/spark-GClog.log
-XX:+PrintGC -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'",
"spark.dynamicAllocation.enabled": "false",
"spark.driver.extraJavaOptions": "-Xloggc:/var/log/spark-GClog.log
-XX:+PrintGC -XX:+UseG1GC -XX:+UnlockDiagnosticVMOptions
-XX:+G1SummarizeConcMark -XX:InitiatingHeapOccupancyPercent=35 -verbose:gc
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:OnOutOfMemoryError='kill -9 %p'"
},
"configurations": []
},
{
"classification": "spark-log4j",
"properties": {
"log4j.logger.org.apache.parquet": "WARN",
"log4j.logger.parquet": "WARN",
"log4j.logger.org.apache.hudi": "WARN"
},
"configurations": []
}
]`
**Hudi Parameters**
- hoodie.index.type: BLOOM
- hoodie.datasource.write.operation: UPSERT
- hoodie.upsert.shuffle.parallelism: 100
- hoodie.payload.ordering.field: hoodie.datasource.write.precombine.field
(uses same field as the precombine)
- hoodie.datasource.write.payload.class:
org.apache.hudi.common.model.DefaultHoodieRecordPayload (used so that latest
does not automatically override existing)
In addition to this, the current real-time version of this app uses the
following parameters:
- driver-cores: 3
- driver-memory: 5400m
- conf spark.driver.memoryOverhead:1024m
- num-executors: 3
- executor-cores: 3
- executor-memory: 5400m
- conf spark.driver.memoryOverhead:1024m
- conf spark.sql.shuffle.partitions: 18
- conf spark.default.parallelism: 18
- spark.memory.fraction: 0.7
- spark.memory.storageFraction: 0.6
- hoodie.index.type: BLOOM
- hoodie.datasource.write.operation: UPSERT
- hoodie.upsert.shuffle.parallelism: 18
Last but not least, attached please find some screenshots from the Spark
history server.
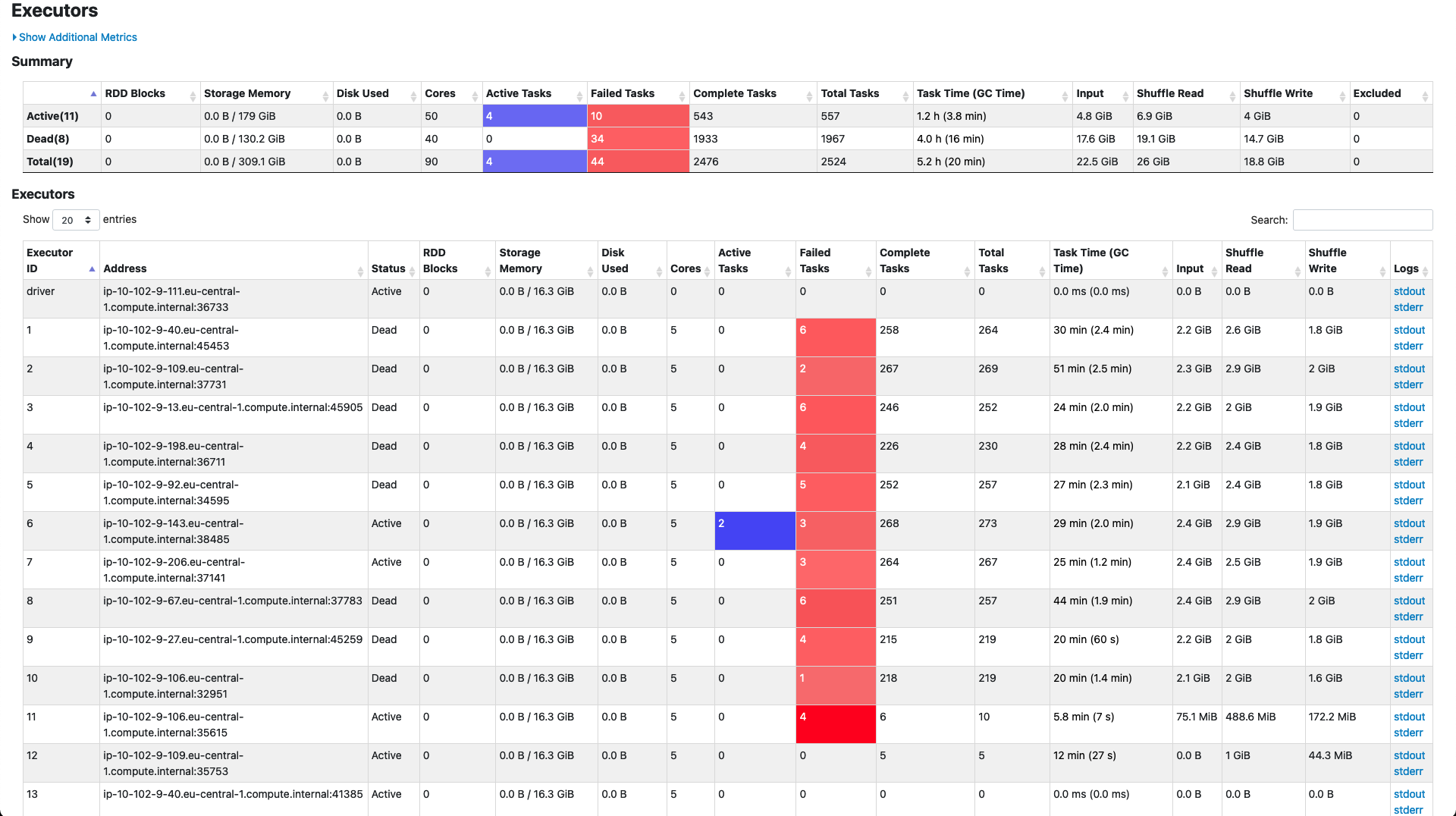
_Executors_
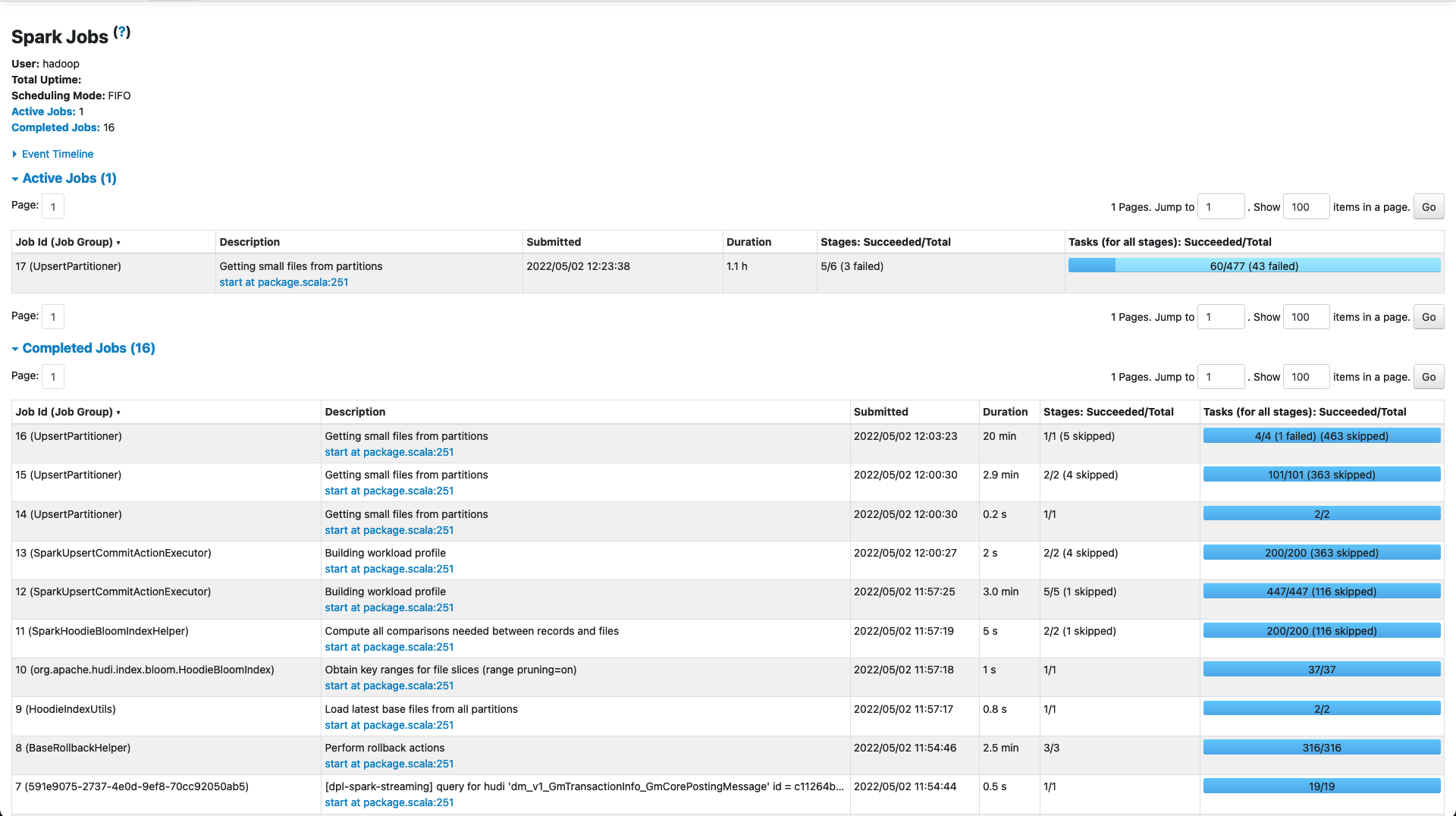
_Jobs_
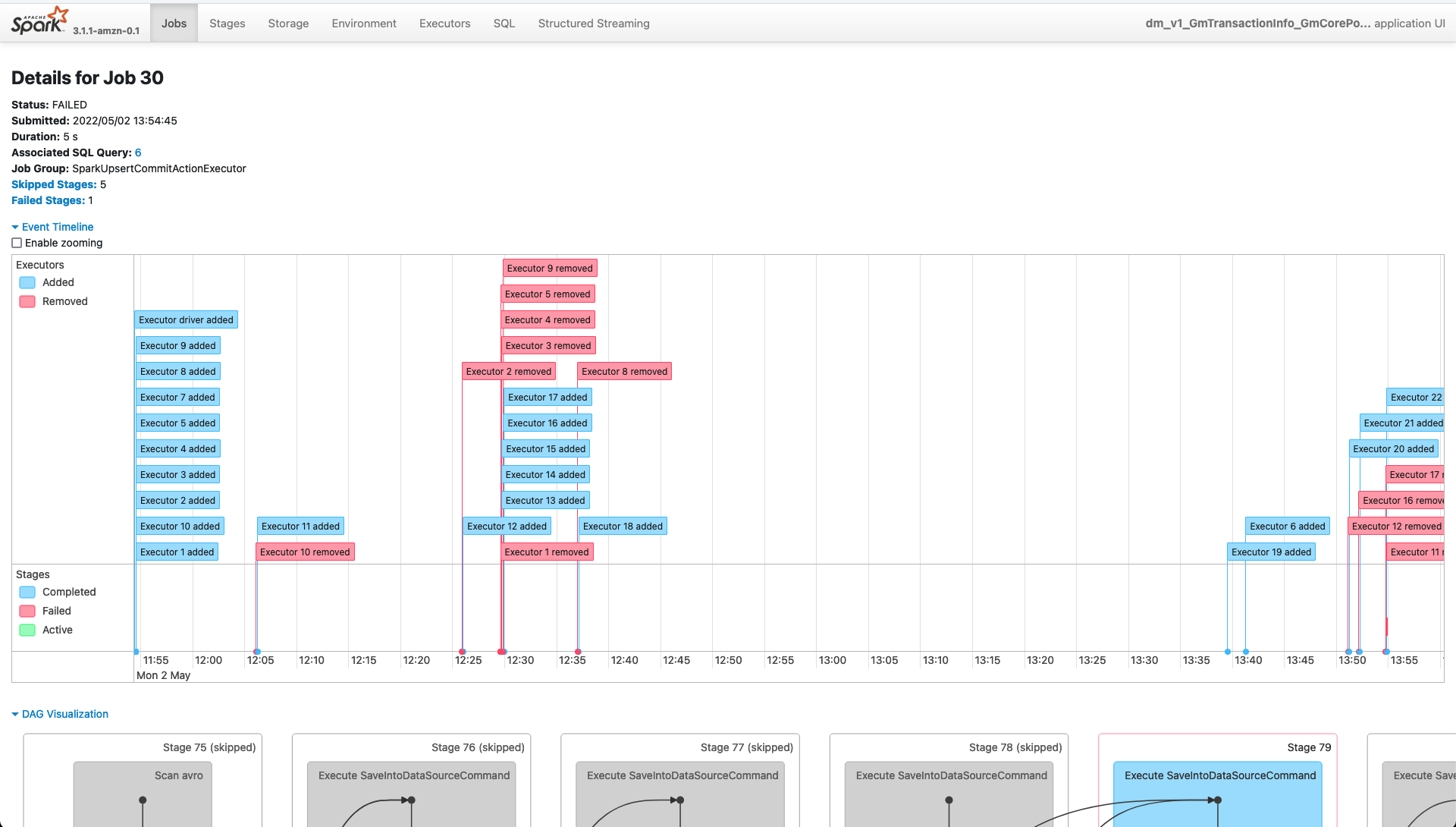
_Failed Job 30 (SparkUpsertCommitActionExecutor)_

_Job Details 30 (SparkUpsertCommitActionExecutor)_
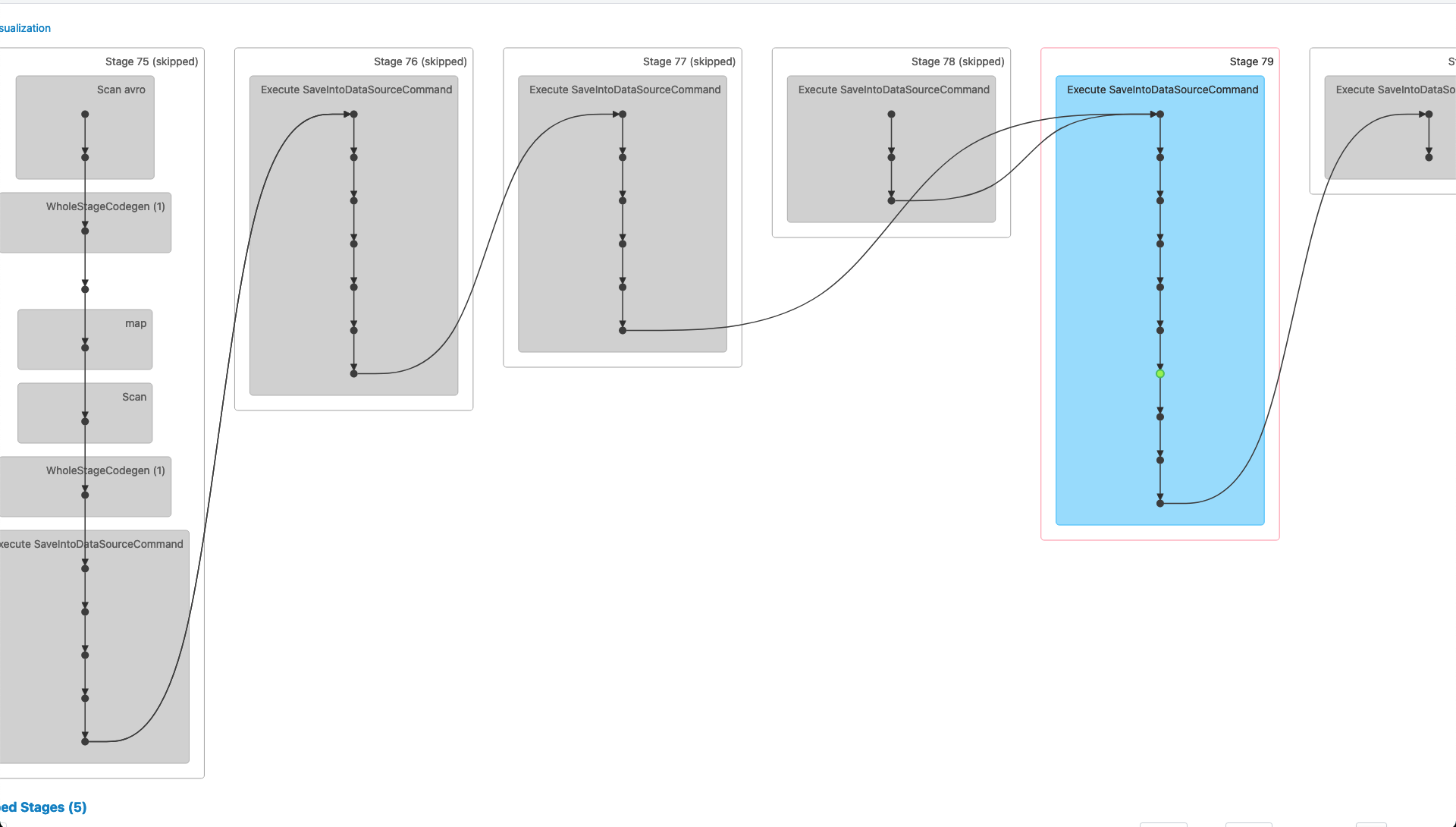
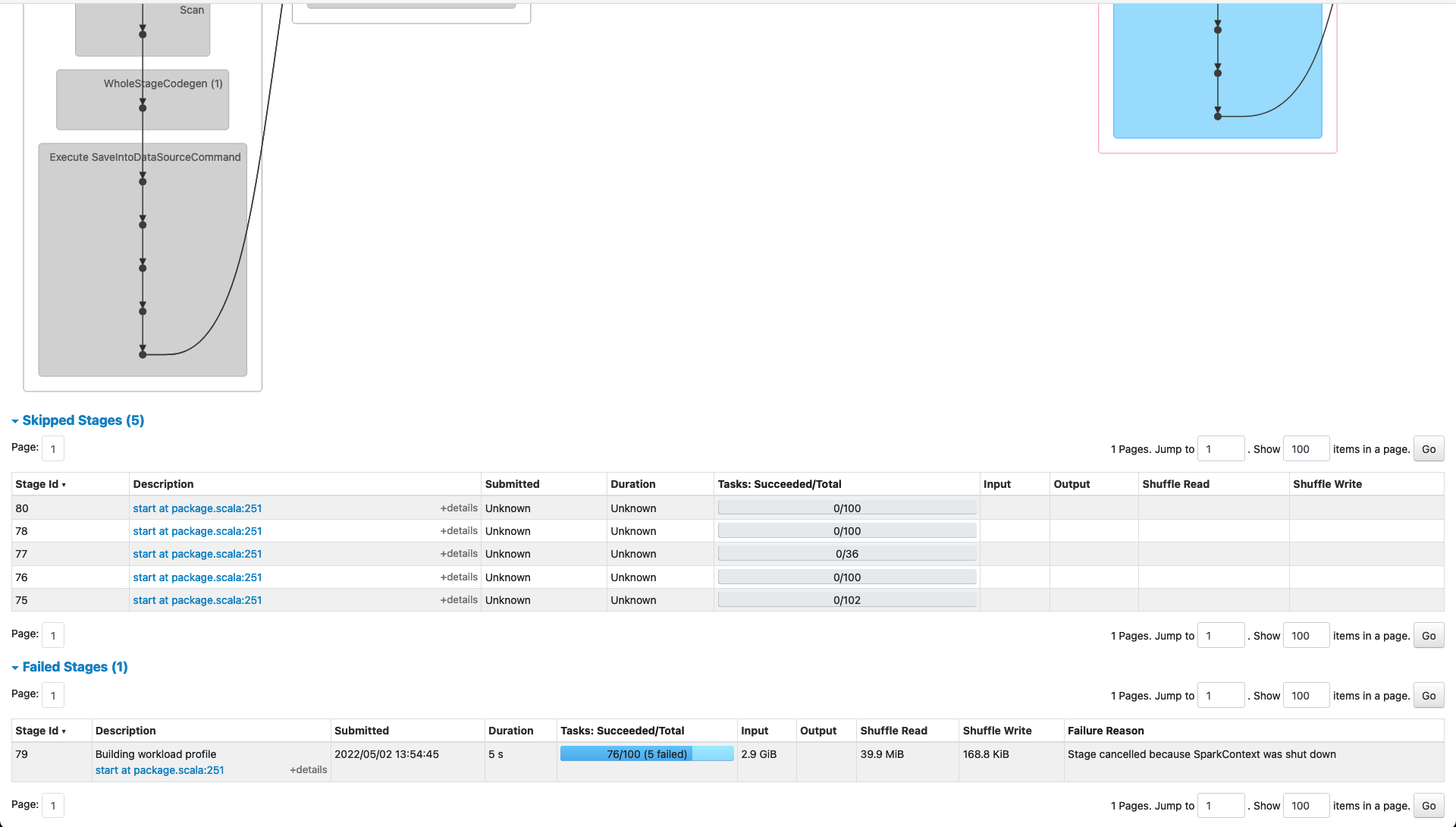
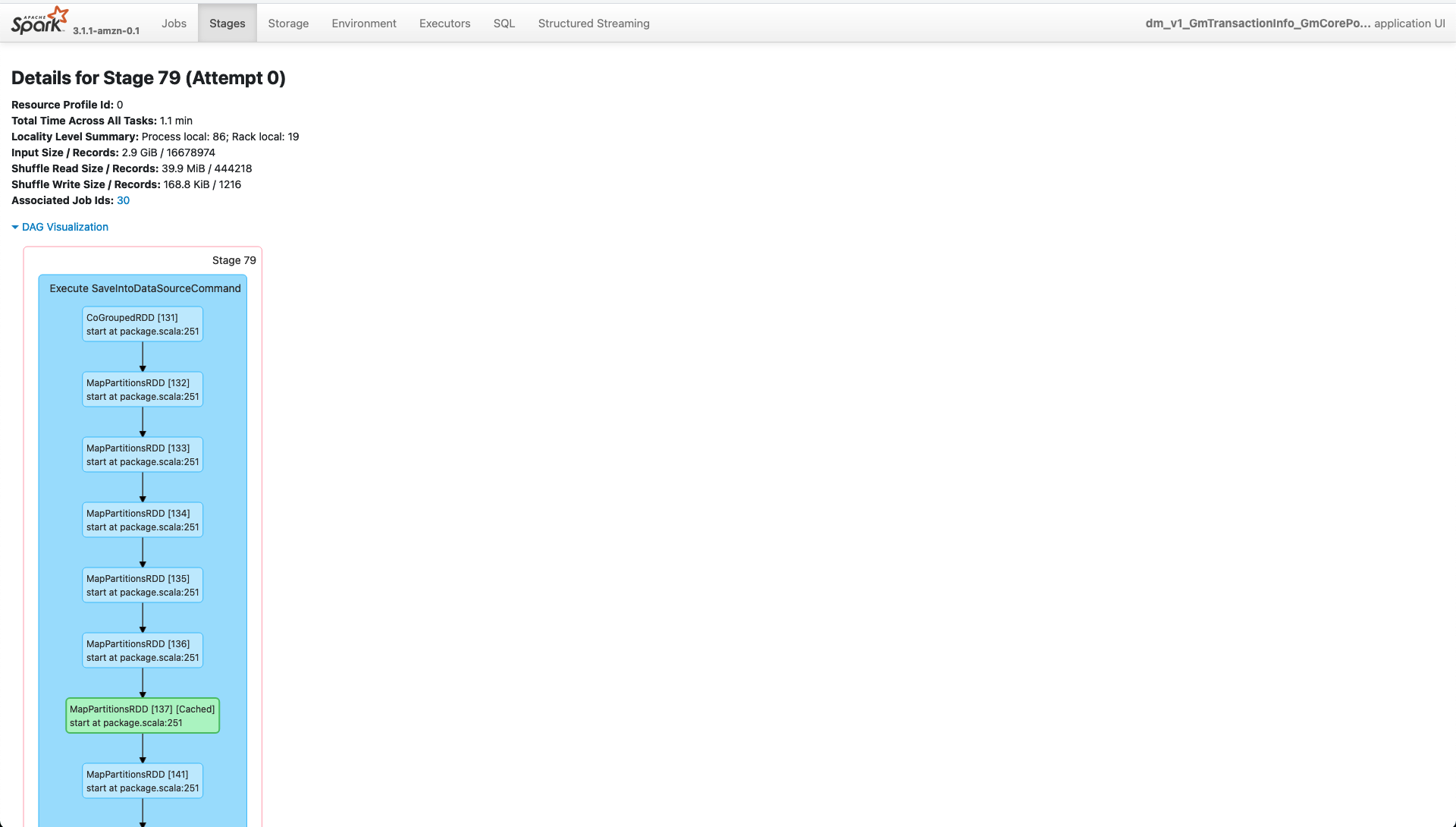
_Failed Stage 79_

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}