yangdafish opened a new issue, #5541: URL: https://github.com/apache/hudi/issues/5541
**Describe the problem you faced** Recently, we upgraded our environment from Hudi 0.8.0 to Hudi 0.9.0, and after the upgrade we noticed that upsert jobs for some of our existing tables run much slower compared to how they ran in Hudi 0.8.0. For our Hudi tables, we ran one bulk_insert job to ingest snapshot, and schedule an upsert job every 10 mins to ingest incremental updates after the completion of bulk_insert job. To reproduce the issue, we ran upsert job on a table with the size around 1.8T. The job took in 11 tsv files (< 150 MB in total) containing both new records and updates. In Hudi 0.8.0, the job took 8.5 mins to complete whereas in Hudi 0.9.0, the job took 25+ mins consistently. And we notice that the main difference seemed to come from the steps "Getting small files from partitions". We don't upgrade to Hudi 0.10 because it is not yet supported by Redshift for our customer purposes 0.8 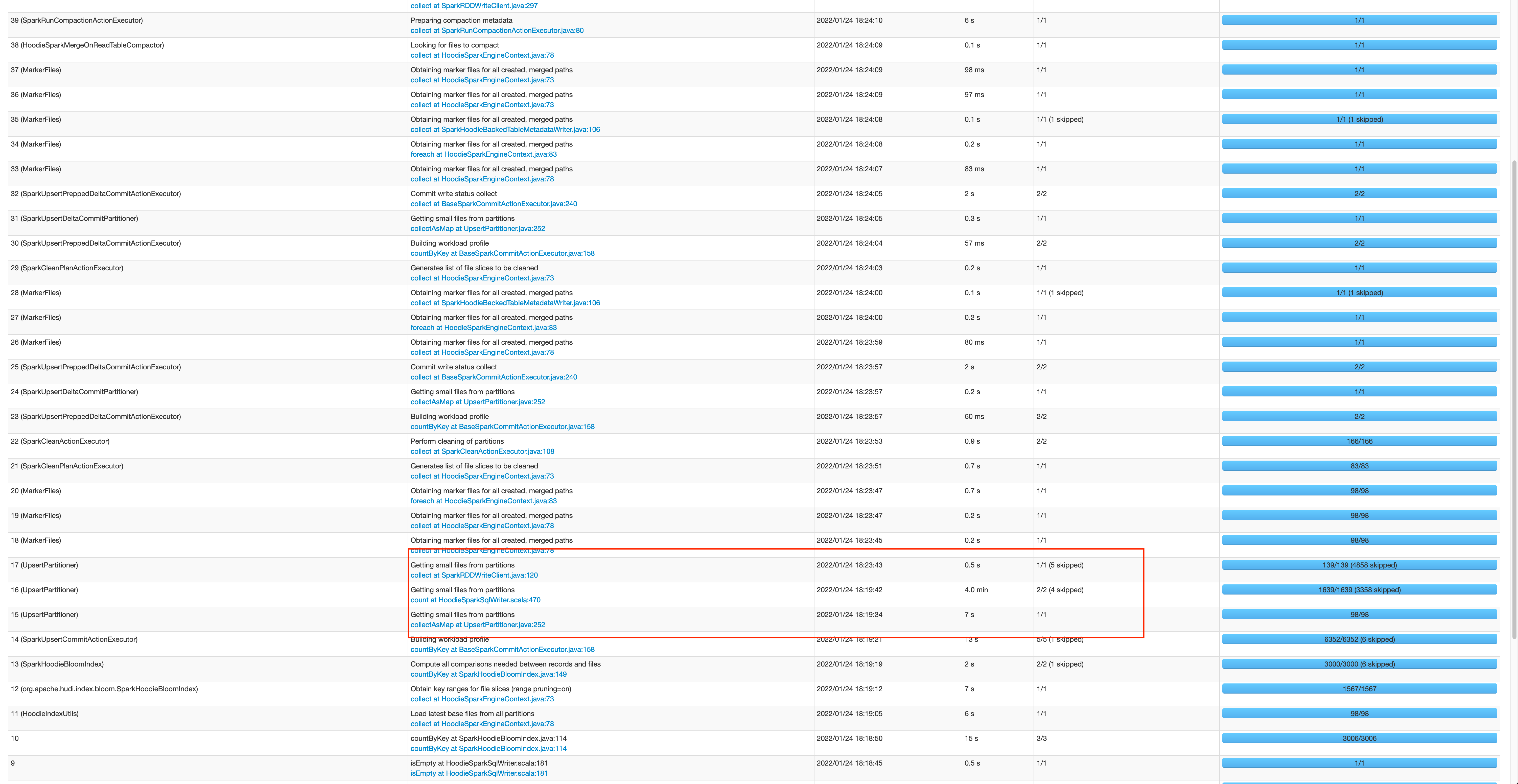 0.9 <img width="1782" alt="Screen Shot 2022-05-03 at 2 28 43 PM" src="https://user-images.githubusercontent.com/32607057/167448363-51dbdf36-44ec-4d7b-ac80-d166f8b6f656.png";> **Environment Description** * Hudi version : 0.9.0 * Spark version : 3.1.2 * Scala version: 2.12 * Hadoop version : 2.10.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no * AWS EMR: 6.55.0, 1 master(r6g.16xlarge) with 30 cores(r6g.16xlarge) **Additional context** Spark configs: --deploy-mode cluster --executor-memory 43g --driver-memory 43g --executor-cores 6 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.hadoop.fs.s3.maxRetries=30 --conf spark.yarn.executor.memoryOverhead=5g Hudi configs: hoodie.consistency.check.enabled -> true hoodie.datasource.write.table.type -> "COPY_ON_WRITE" hoodie.datasource.write.keygenerator.class -> "org.apache.hudi.keygen.ComplexKeyGenerator" hoodie.upsert.shuffle.parallelism -> 1500 hoodie.bulkinsert.shuffle.parallelism -> 1800 hoodie.parquet.max.file.size -> 500 * 1024 * 1024 hoodie.datasource.write.operation -> "upsert" hoodie.metadata.enable -> true hoodie.metadata.validate -> true hoodie.fail.on.timeline.archiving -> false hoodie.clean.automatic -> true hoodie.cleaner.commits.retained: 72 hoodie.keep.min.commits: 100 hoodie.keep.max.commits: 150 hoodie.write.markers.type: timeline_server_based **Stacktrace** Getting small files from partitions isEmpty at HoodieSparkSqlWriter.scala:609 +details org.apache.spark.rdd.RDD.isEmpty(RDD.scala:1557) org.apache.hudi.HoodieSparkSqlWriter$.commitAndPerformPostOperations(HoodieSparkSqlWriter.scala:609) org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:274) org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:164) org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:46) org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70) org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68) org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:90) org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:194) org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:232) org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:229) org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:190) org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:134) org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:133) org.apache.spark.sql.DataFrameWriter.$anonfun$runCommand$1(DataFrameWriter.scala:989) org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232) org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:110) org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:135) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}