cuibo01 commented on PR #5678: URL: https://github.com/apache/hudi/pull/5678#issuecomment-1137001976
> > > Thanks for the contribution, can we explain a little what's the purpose of this patch ? Is is an improvement or bug fix ? Personally i dislike to introducing multiple threads based on that StreamReadOperator is already with distributed parallelism. > > > > > > MergeOnReadInputFormat#open takes a long time, causing the chk to time out > > https://github.com/apache/hudi/blob/f30b3aef3e5e12e9119d6b5294c94a0282719e00/hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/table/format/mor/MergeOnReadInputFormat.java#L655 > > Thanks, did you analyze what causes the most of time here ? I guess it is the Merge On Read table iterator initialization takes much time, because it reads all the records of one file group into a map (`BitCaskMap` by default), which takes time(for precombining logic here). > > Is the time out caused by too many splits queued up there or due to some file split is huge ? 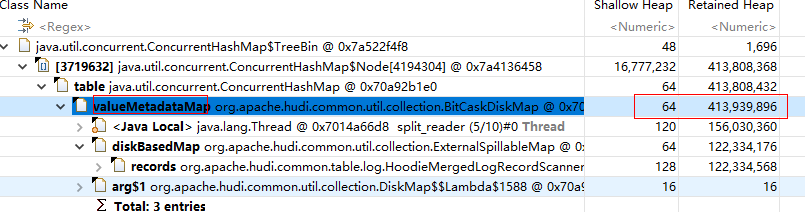 i find that large files cause slow opening...For example, when a job is restarted using `start-commit=earliest` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}