vinothchandar commented on PR #5436: URL: https://github.com/apache/hudi/pull/5436#issuecomment-1143238175
@danny0405 @YannByron I went over our conversations, re-read this RFC and the google doc. The main outstanding debate is whether to materialize the `before` image of the records during write time (batch friendly) or derive it on the fly during query time (streaming friendly). Materializing costs more $$ in terms of storage cost + the additional compute cost for double writing. Conceptually, deriving it on the fly (using just a `_hoodie_operation` field added to each record) needs more work on CDC query side. E.g: let's take a CDC query for changes between commit times [t1, tN]. For each file group, we need to start with the latest file slice as of t1, extract rows that changed after or at t1, and extract its before image from the file slice before. Effectively, this will incur double reading. But even with materialization, we cannot really avoid this, can we? 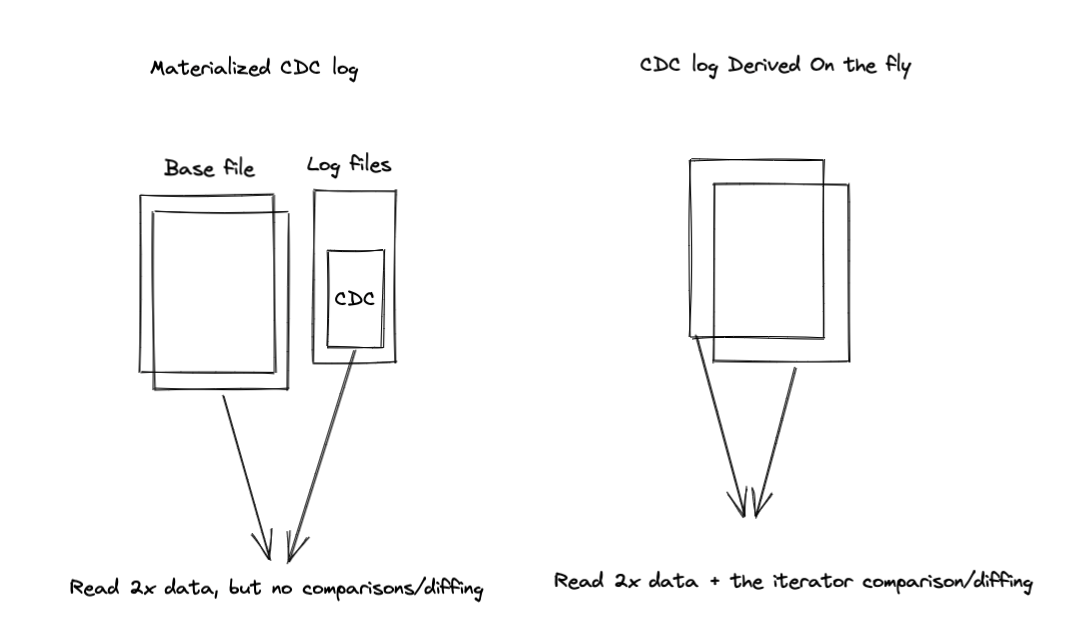 @YannByron Can you quantify the extra cost in stitching/diffing on the fly? Is that performance sensitive? Trying to understand why you think if we don't materialize the CDC query cost will be high. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}