jiangbiao910 opened a new issue, #6127:
URL: https://github.com/apache/hudi/issues/6127
Hudi has recently released the latest version of Hudi, 0.11.1, which is
pulled from Github and modified as follows for our Hadoop environment CDH6.3.2。
Upgrading to 0.11.1 resulting use sparksql:
`
create table if not exists zone_test.hudi_spark_table0718_mor_0111
(
id string,
brand_id int,
name string,
model_id int,
model_name string,
etl_update_time string,
dt string,
hh string
) using hudi
options (
type = 'mor',
primaryKey = 'brand_id,vehicle_model_id',
preCombineField = 'etl_update_time',
hoodie.cleaner.commits.retained = '2',
hoodie.compact.inline=true
)
partitioned by (dt,hh)
;
insert into zone_test.hudi_spark_table0718_mor_0111 partition (dt,hh)
select id,
brand_id,
name,
model_id,
model_name,
CAST(current_timestamp AS string) as etl_update_time,
'20220718',
'10'
from zone_test.test_vehicle_status_2_hi
;
`
now I can see **3 tables** in the Hive
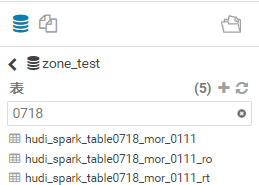
But,there is **zero result** in the table
**zone_test.hudi_spark_table0718_mor_0111** and
**hudi_spark_table0718_mor_0111_ro
hudi_spark_table0718_mor_0111_rt** has **2 records**。this is a bug?
However when I run this SQL:
`set hoodie.datasource.hive_sync.skip_ro_suffix=true;
create table if not exists zone_test.hudi_spark_table0718_mor_0111_skip
(
id string,
brand_id int,
name string,
model_id int,
model_name string,
etl_update_time string,
dt string,
hh string
) using hudi
options (
type = 'mor',
primaryKey = 'brand_id,vehicle_model_id',
preCombineField = 'etl_update_time',
hoodie.cleaner.commits.retained = '2',
hoodie.compact.inline=true
)
partitioned by (dt,hh)
;
insert into zone_test.hudi_spark_table0718_mor_0111_skip partition (dt,hh)
select id,
brand_id,
name,
model_id,
model_name,
CAST(current_timestamp AS string) as etl_update_time,
'20220715',
'10'
from zone_test.test_vehicle_status_2_hi
;
`
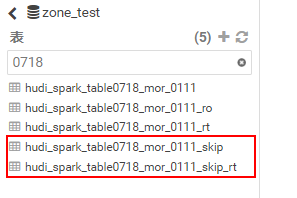
now I can see 2 tables in the Hive,both
**hudi_spark_table0718_mor_0111_skip and
hudi_spark_table0718_mor_0111_skip_rt** has **2recoreds**。
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}