Xiaohan-Shen opened a new issue, #6653: URL: https://github.com/apache/hudi/issues/6653
**Describe the problem you faced** Hey guys, I tried to run DeltaStreamer on EMR to capture changes in MySQL through AWS DMS and store them COW on S3. I tried to run it for a table with 30,000 rows and 9 columns, which takes up ~6M on MySQL, but on S3 the Hudi table's folder takes up >10 GB... Did I configure something wrong? 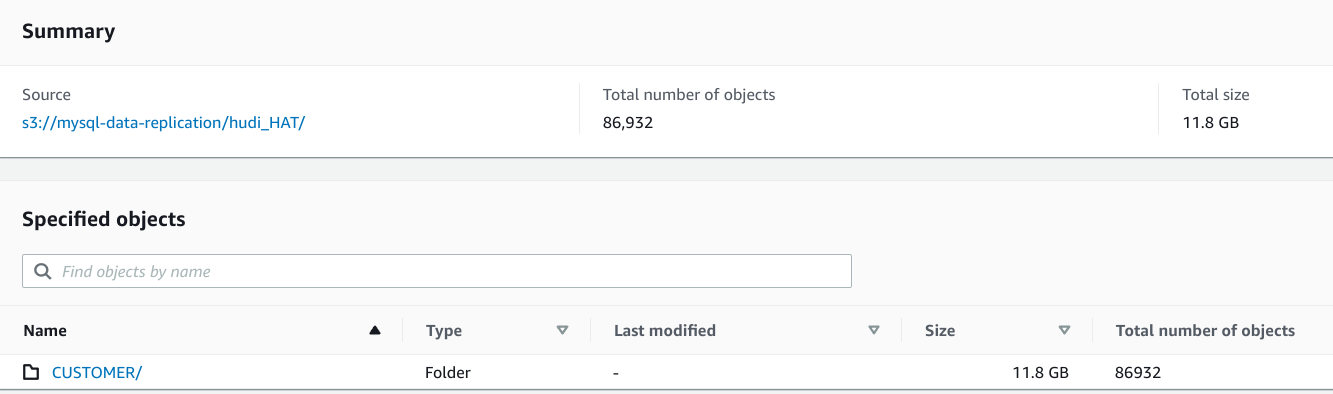 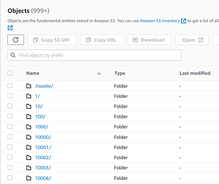 **To Reproduce** Steps to reproduce the behavior: 1. Follow basic setup described in this [blog](https://cwiki.apache.org/confluence/display/HUDI/2020/01/20/Change+Capture+Using+AWS+Database+Migration+Service+and+Hudi) 2. Insert 30,000 rows into MySQL and wait until AWS DMS captures the changes 3. Use this command to start Hudi: ``` spark-submit --jars /usr/lib/spark/external/lib/spark-avro.jar,/usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/hudi/hudi-utilities-bundle.jar --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --packages org.apache.hudi:hudi-spark-bundle_2.12:0.11.0,org.apache.spark:spark-avro_2.12:3.2.1 --master yarn --deploy-mode client /usr/lib/hudi/hudi-utilities-bundle.jar --table-type COPY_ON_WRITE --source-ordering-field updated_at --source-class org.apache.hudi.utilities.sources.ParquetDFSSource --target-base-path s3://mysql-data-replication/hudi_orders --target-table hudi_orders --transformer-class org.apache.hudi.utilities.transform.AWSDmsTransformer --continuous --hoodie-conf hoodie.datasource.write.recordkey.field=order_id --hoodie-conf hoodie.datasource.write.partitionpath.field=customer_name --hoodie-conf hoodie.deltastreamer.source.dfs.root=s3://mysql-data-replication/hudi_dms/orders --payload-class org.apache.hudi.payload.AWSDmsAvroPayload ``` **Expected behavior** The table takes up 6M on MySQL, so I expect the Hudi table to be <30M on S3. **Environment Description** * Hudi version : 0.11.0 * Spark version : 3.2.1 * Hive version : should be irrelevant, but 3.1.3 * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}