15663671003 opened a new issue, #6723:
URL: https://github.com/apache/hudi/issues/6723
**Describe the problem you faced**
The problem that the parquet file cannot be found when using spark to
incrementally read the MOR table, When reading, no write transactions are
executed
Steps to reproduce the behavior:
1. Start Spark
2. Create a dataframe of one record
3. Use BUCKET SIMPLE index upsert hudi to partition the table
3. First success
4. The second failure
How to solve this problem
**Expected behavior**
By checking the code, it is found that the exception code is
```
public static int bucketIdFromFileId(String fileId) {
return Integer.parseInt(fileId.substring(0, 8));
}
```
Trace the file successfully written for the first time. It is found that the
first 8 bytes of the parquet file are not numbers to complete eight characters,
but 8-byte hexadecimal strings.
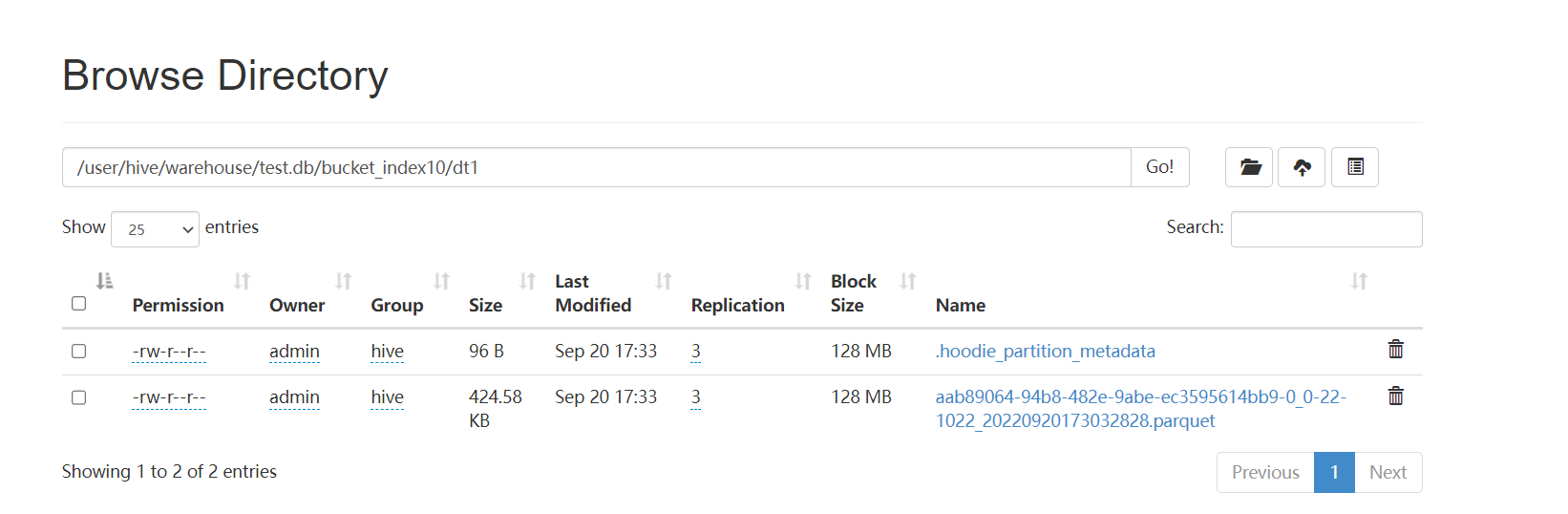
the code to replace the first eight bytes is
```
public static String newBucketFileIdPrefix(String bucketId) {
return FSUtils.createNewFileIdPfx().replaceFirst(".{8}", bucketId);
}
```
I don't know why this problem occurs. Please help me
**Environment Description**
* Hudi version : 0.12.0
* Spark version : 2.4.8
* Hive version : 2.1.1
* Hadoop version : 3.0.0
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.8
/_/
Using Python version 3.7.9 (default, Jan 14 2021 11:40:45)
SparkSession available as 'spark'.
>>> table = "test.bucket_index10"
>>> path = "/user/hive/warehouse/test.db/bucket_index10"
>>> hudi_options = {
... 'hoodie.table.name': table,
... 'hoodie.datasource.write.table.name': table,
... 'hoodie.datasource.write.operation': "upsert",
... 'hoodie.datasource.write.table.type': "MERGE_ON_READ",
... 'hoodie.datasource.write.keygenerator.class':
'org.apache.hudi.keygen.ComplexKeyGenerator',
... 'hoodie.datasource.write.payload.class':
"org.apache.hudi.common.model.DefaultHoodieRecordPayload",
... "hoodie.index.type": "BUCKET",
... "hoodie.bucket.index.num.buckets": 256,
... "hoodie.index.bucket.engine": "SIMPLE",
... 'hoodie.datasource.write.partitionpath.field': "dt",
... 'hoodie.datasource.write.precombine.field': "ts",
... 'hoodie.datasource.write.recordkey.field': "rk",
... }
>>> df = spark.createDataFrame([["rk1", "ts1", "dt1"]], ["rk", "ts", "dt"])
>>> df.write.format("hudi").options(**hudi_options).save(path, mode='append')
22/09/20 17:30:32 WARN config.DFSPropertiesConfiguration: Cannot find
HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
22/09/20 17:30:32 WARN config.DFSPropertiesConfiguration: Properties file
file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
22/09/20 17:30:33 WARN metadata.HoodieBackedTableMetadata: Metadata table
was not found at path
/user/hive/warehouse/test.db/bucket_index10/.hoodie/metadata
00:52 WARN: Timeline-server-based markers are not supported for HDFS: base
path /user/hive/warehouse/test.db/bucket_index10. Falling back to direct
markers.
01:14 WARN: Timeline-server-based markers are not supported for HDFS: base
path /user/hive/warehouse/test.db/bucket_index10. Falling back to direct
markers.
>>> df.write.format("hudi").options(**hudi_options).save(path, mode='append')
22/09/20 17:32:17 WARN impl.MetricsConfig: Cannot locate configuration:
tried hadoop-metrics2-hbase.properties,hadoop-metrics2.properties
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/spark-2.4.8-bin-hadoop2.7/python/pyspark/sql/readwriter.py",
line 742, in save
self._jwrite.save(path)
File
"/opt/spark-2.4.8-bin-hadoop2.7/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py",
line 1257, in __call__
File "/opt/spark-2.4.8-bin-hadoop2.7/python/pyspark/sql/utils.py", line
63, in deco
return f(*a, **kw)
File
"/opt/spark-2.4.8-bin-hadoop2.7/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py",
line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o118.save.
: org.apache.hudi.exception.HoodieUpsertException: Failed to upsert for
commit time 20220920173216169
at
org.apache.hudi.table.action.commit.BaseWriteHelper.write(BaseWriteHelper.java:64)
at
org.apache.hudi.table.action.deltacommit.SparkUpsertDeltaCommitActionExecutor.execute(SparkUpsertDeltaCommitActionExecutor.java:46)
at
org.apache.hudi.table.HoodieSparkMergeOnReadTable.upsert(HoodieSparkMergeOnReadTable.java:89)
at
org.apache.hudi.table.HoodieSparkMergeOnReadTable.upsert(HoodieSparkMergeOnReadTable.java:76)
at
org.apache.hudi.client.SparkRDDWriteClient.upsert(SparkRDDWriteClient.java:155)
at
org.apache.hudi.DataSourceUtils.doWriteOperation(DataSourceUtils.java:206)
at
org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:329)
at
org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:183)
at
org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at
org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:136)
at
org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:132)
at
org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:160)
at
org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at
org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:157)
at
org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:132)
at
org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:83)
at
org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:81)
at
org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:696)
at
org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:696)
at
org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75)
at
org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:696)
at
org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:305)
at
org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:291)
at
org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:249)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at
py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NumberFormatException: For input string: "aab89064"
at
java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at
org.apache.hudi.index.bucket.BucketIdentifier.bucketIdFromFileId(BucketIdentifier.java:84)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex.lambda$loadPartitionBucketIdFileIdMapping$0(HoodieSimpleBucketIndex.java:59)
at java.util.ArrayList.forEach(ArrayList.java:1257)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex.loadPartitionBucketIdFileIdMapping(HoodieSimpleBucketIndex.java:56)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex.access$000(HoodieSimpleBucketIndex.java:40)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex$SimpleBucketIndexLocationMapper.lambda$new$1(HoodieSimpleBucketIndex.java:89)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321)
at
java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at
java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801)
at
java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at
java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at
java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at
java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at
java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex$SimpleBucketIndexLocationMapper.<init>(HoodieSimpleBucketIndex.java:89)
at
org.apache.hudi.index.bucket.HoodieSimpleBucketIndex.getLocationMapper(HoodieSimpleBucketIndex.java:78)
at
org.apache.hudi.index.bucket.HoodieBucketIndex.tagLocation(HoodieBucketIndex.java:75)
at
org.apache.hudi.table.action.commit.HoodieWriteHelper.tag(HoodieWriteHelper.java:49)
at
org.apache.hudi.table.action.commit.HoodieWriteHelper.tag(HoodieWriteHelper.java:32)
at
org.apache.hudi.table.action.commit.BaseWriteHelper.write(BaseWriteHelper.java:53)
... 39 more
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}