rohit-m-99 opened a new issue, #6943: URL: https://github.com/apache/hudi/issues/6943
**Describe the problem you faced** Column stat indexing seems to be running at query time. Currently use a deltastreamer to write files and have been using ColumnStatIndexes and data-skipping for query speed. However after executing any query, I am seeing long running jobs detailed below. If I kill this job, my query runs normally without error. 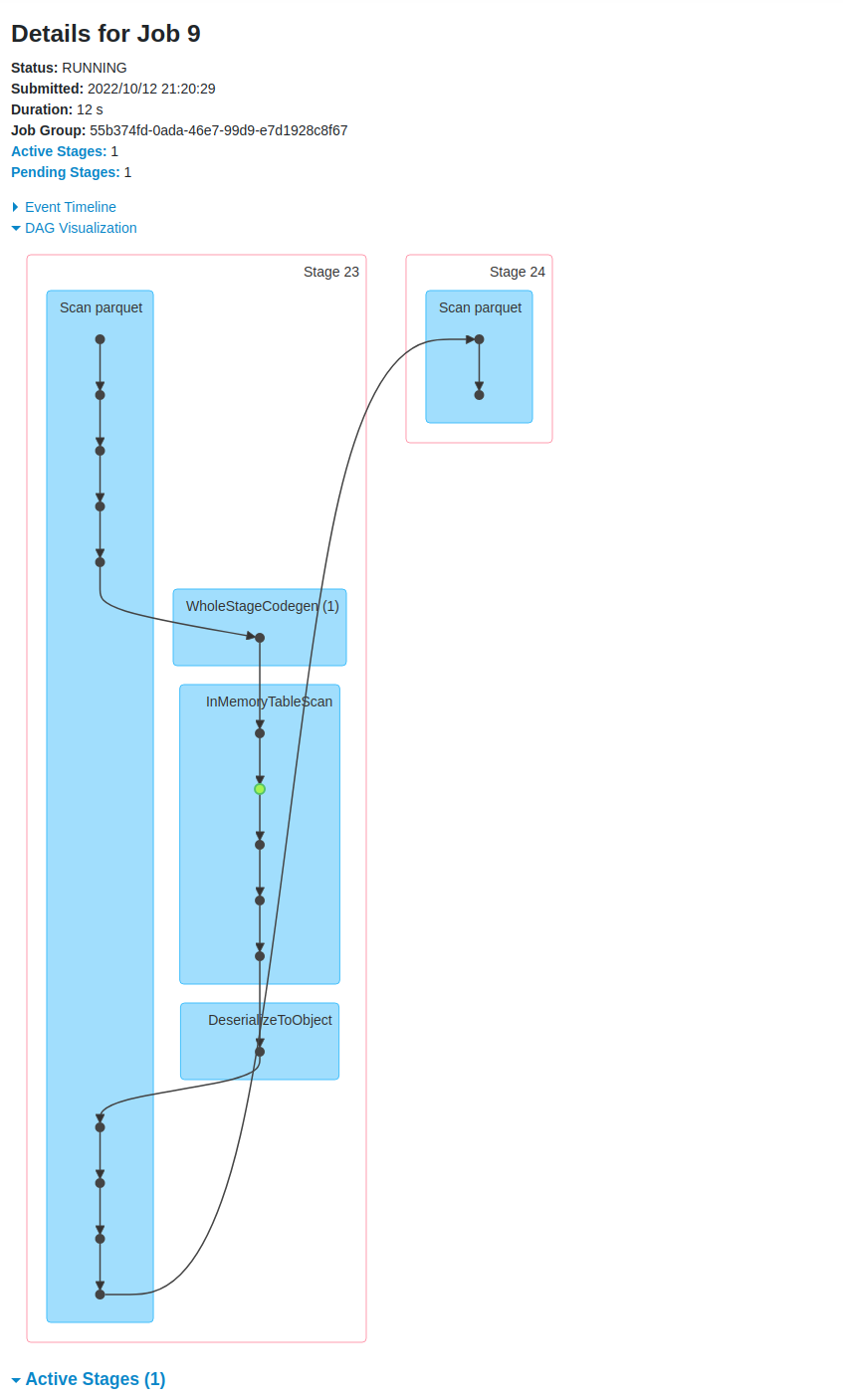 ```org.apache.spark.rdd.RDD.distinct(RDD.scala:470) org.apache.hudi.ColumnStatsIndexSupport.transposeColumnStatsIndex(ColumnStatsIndexSupport.scala:141) org.apache.hudi.ColumnStatsIndexSupport.transposeColumnStatsIndex$(ColumnStatsIndexSupport.scala:121) org.apache.hudi.HoodieFileIndex.transposeColumnStatsIndex(HoodieFileIndex.scala:69) org.apache.hudi.HoodieFileIndex.$anonfun$lookupCandidateFilesInMetadataTable$2(HoodieFileIndex.scala:209) org.apache.hudi.HoodieDatasetUtils$.withPersistence(HoodieDatasetUtils.scala:40) org.apache.hudi.HoodieFileIndex.$anonfun$lookupCandidateFilesInMetadataTable$1(HoodieFileIndex.scala:208) scala.util.Try$.apply(Try.scala:213) org.apache.hudi.HoodieFileIndex.lookupCandidateFilesInMetadataTable(HoodieFileIndex.scala:190) org.apache.hudi.HoodieFileIndex.listFiles(HoodieFileIndex.scala:116) org.apache.spark.sql.execution.FileSourceScanExec.selectedPartitions$lzycompute(DataSourceScanExec.scala:215) org.apache.spark.sql.execution.FileSourceScanExec.selectedPartitions(DataSourceScanExec.scala:210) org.apache.spark.sql.execution.FileSourceScanExec.dynamicallySelectedPartitions$lzycompute(DataSourceScanExec.scala:245) org.apache.spark.sql.execution.FileSourceScanExec.dynamicallySelectedPartitions(DataSourceScanExec.scala:226) org.apache.spark.sql.execution.FileSourceScanExec.inputRDD$lzycompute(DataSourceScanExec.scala:413) org.apache.spark.sql.execution.FileSourceScanExec.inputRDD(DataSourceScanExec.scala:398) org.apache.spark.sql.execution.FileSourceScanExec.doExecuteColumnar(DataSourceScanExec.scala:497) org.apache.spark.sql.execution.SparkPlan.$anonfun$executeColumnar$1(SparkPlan.scala:207) org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:218) org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)``` **To Reproduce** Ingestion method, using deltastreamer ``` #!/bin/bash spark-submit \ --jars opt/spark/jars/hudi-utilities-bundle.jar,/opt/spark/jars/hadoop-aws.jar,/opt/spark/jars/aws-java-sdk.jar \ --master spark://spark-master:7077 \ --total-executor-cores 10 \ --executor-memory 4g \ --conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \ --conf spark.hadoop.fs.s3a.connection.maximum=10000 \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer opt/spark/jars/hudi-utilities-bundle.jar \ --source-class org.apache.hudi.utilities.sources.ParquetDFSSource \ --target-table per_tick_stats \ --table-type COPY_ON_WRITE \ --min-sync-interval-seconds 30 \ --source-limit 1000000000 \ --continuous \ --source-ordering-field $3 \ --target-base-path $2 \ --hoodie-conf hoodie.clustering.plan.strategy.sort.columns=$5 \ --hoodie-conf hoodie.clustering.inline=false \ --hoodie-conf hoodie.clustering.plan.strategy.max.bytes.per.group=107374182400 \ --hoodie-conf hoodie.clustering.plan.strategy.max.num.groups=65536 \ --hoodie-conf hoodie.clustering.plan.strategy.small.file.limit=100000000 \ --hoodie-conf hoodie.clustering.plan.strategy.target.file.max.bytes=134217728 \ --hoodie-conf hoodie.clustering.inline.max.commits=4 \ --hoodie-conf hoodie.deltastreamer.source.dfs.root=$1 \ --hoodie-conf hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator \ --hoodie-conf hoodie.datasource.write.recordkey.field=$4 \ --hoodie-conf hoodie.datasource.write.precombine.field=$3 \ --hoodie-conf hoodie.datasource.write.partitionpath.field=$6 \ --hoodie-conf hoodie.metadata.enable=true \ --hoodie-conf hoodie.metadata.index.column.stats.enable=true \ --op INSERT ``` Query method ``` stat_data_frame = ( self.session.read.format("hudi") .option("hoodie.enable.data.skipping", "true") .option("hoodie.metadata.enable", "true") .option("hoodie.metadata.index.column.stats.enable", "true") .load(self.spark_path) ) stat_data_frame.createOrReplaceTempView(target_table) query = self.session.sql(request.sql_query) ``` **Expected behavior** Query should run without any additional steps ahead of it. **Environment Description** * Hudi version : 0.11.1 * Spark version : 3.1.3 * Hive version : * Hadoop version : * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : tes -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}