nikspatel03 opened a new issue, #7201:
URL: https://github.com/apache/hudi/issues/7201
Hello,
We want to use deltastreamer utility to ingest kafka Json data into hudi COW
table but showing garbage values in hudi table and unable to sync to glue
metastore.
Kafka version : 2.0.0
EMR-5.35.0
Hudi 0.9.0-amzn-2
**To Reproduce:**
_**Kafka Sample Payload:**_
{
"record": [{
"ticker": "USD",
"side": "Buy",
"price": 82.71,
"timestamp": 1668032589000,
"date": "2022-11-09"
},
{
"ticker": "USD",
"side": "Sell",
"price": 79.57,
"timestamp": 1668032589000,
"date": "2022-11-09"
}
]
}
**_src.avsc_**
{
"type": "record",
"name": "data",
"fields": [{
"name": "record",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "data2",
"fields": [{
"name": "ticker",
"type": ["string", "null"]
}, {
"name": "side",
"type": ["string", "null"]
}, {
"name": "price",
"type": ["double", "null"]
}, {
"name": "timestamp",
"type": ["long", "null"]
}, {
"name": "date",
"type": {
"type": "int",
"logicalType": "date"
}
}]
}
}
}]
}
**_tgt.avsc_**
{
"type": "record",
"name": "data",
"fields": [{
"name": "ticker",
"type": ["string", "null"]
}, {
"name": "side",
"type": ["string", "null"]
}, {
"name": "price",
"type": ["double", "null"]
}, {
"name": "timestamp",
"type": ["long", "null"]
}, {
"name": "date",
"type": {
"type": "int",
"logicalType": "date"
}
}]
}
**_## Spark-submit Command: ##_**
spark-submit
--deploy-mode client
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer
--conf spark.shuffle.service.enabled=true
--conf spark.dynamicAllocation.enabled=true
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.sql.hive.convertMetastoreParquet=false
--conf yarn.nodemanager.vmem-check-enabled=false
--conf yarn.nodemanager.pmem-check-enabled=false
--conf spark.app.name=currency_ticks_cdc
--jars /usr/lib/spark/external/lib/spark-avro.jar
/usr/lib/hudi/hudi-utilities-bundle.jar
--table-type COPY_ON_WRITE
--op INSERT
--source-ordering-field timestamp
--target-table CURRENCY_TICKS
--source-class org.apache.hudi.utilities.sources.JsonKafkaSource
--transformer-class
org.apache.hudi.utilities.transform.SqlQueryBasedTransformer
--target-base-path <S3_PATH>/CURRENCY_TICKS
--schemaprovider-class
org.apache.hudi.utilities.schema.FilebasedSchemaProvider
--hoodie-conf security.protocol=SASL_SSL
--hoodie-conf auto.offset.reset=earliest
--hoodie-conf group.id=currency_ticks_gp3
--hoodie-conf sasl.mechanism=SCRAM-SHA-512
--hoodie-conf
sasl.jaas.config="org.apache.kafka.common.security.scram.ScramLoginModule
required username='updater' password='abcd123;"
--hoodie-conf
hoodie.datasource.hive_sync.jdbcurl=jdbc:hive2://10.67.28.33:10000
--hoodie-conf hoodie.datasource.write.recordkey.field=ticker,side,timestamp
--hoodie-conf hoodie.datasource.write.partitionpath.field=date
--hoodie-conf
hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexKeyGenerator
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=date
--hoodie-conf hoodie.datasource.hive_sync.support_timestamp=false
--hoodie-conf hoodie.datasource.hive_sync.enable=true
--hoodie-conf hoodie.datasource.hive_sync.database=<DB_NAME>
--hoodie-conf hoodie.datasource.hive_sync.table=CURRENCY_TICKS
--hoodie-conf hoodie.datasource.hive_sync.assume_date_partitioning=false
--hoodie-conf
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor
--hoodie-conf hoodie.deltastreamer.source.kafka.topic=test-topic-2
--hoodie-conf hoodie.deltastreamer.transformer.sql="select explode(record)
from <SRC>"
--hoodie-conf hoodie.insert.shuffle.parallelism=50
--hoodie-conf bootstrap.servers=<BOOTSTRAP_SERVERS>
--hoodie-conf
hoodie.deltastreamer.schemaprovider.source.schema.file=s3://<S3_PATH>/src.avsc
--hoodie-conf
hoodie.deltastreamer.schemaprovider.target.schema.file=s3://<S3_PATH>/tgt.avsc
--enable-sync
--source-limit 10000000
**_Hudi Table :_**
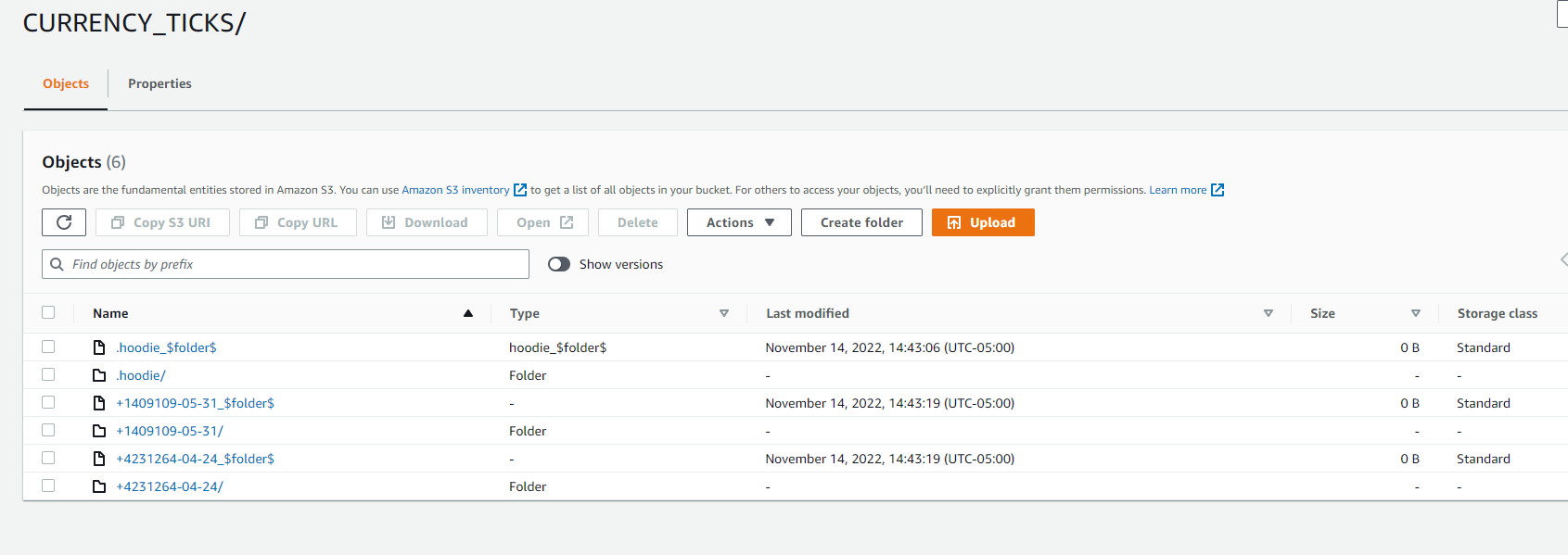
Also unable to sync metastore throwing following error:
22/11/14 19:43:52 ERROR HoodieDeltaStreamer: Got error running delta sync
once. Shutting down
org.apache.hudi.exception.HoodieException: Got runtime exception when hive
syncing CURRENCY_TICKS
at
org.apache.hudi.hive.HiveSyncTool.syncHoodieTable(HiveSyncTool.java:120)
at
org.apache.hudi.utilities.deltastreamer.DeltaSync.syncHive(DeltaSync.java:625)
at
org.apache.hudi.utilities.deltastreamer.DeltaSync.syncMeta(DeltaSync.java:601)
at
org.apache.hudi.utilities.deltastreamer.DeltaSync.writeToSink(DeltaSync.java:526)
at
org.apache.hudi.utilities.deltastreamer.DeltaSync.syncOnce(DeltaSync.java:303)
at
org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.lambda$sync$2(HoodieDeltaStreamer.java:186)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:96)
at
org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.sync(HoodieDeltaStreamer.java:184)
at
org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer.main(HoodieDeltaStreamer.java:513)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at
org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:863)
at
org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at
org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:938)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:947)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hudi.hive.HoodieHiveSyncException: Failed to sync
partitions for table CURRENCY_TICKS
at
org.apache.hudi.hive.HiveSyncTool.syncPartitions(HiveSyncTool.java:339)
at
org.apache.hudi.hive.HiveSyncTool.syncHoodieTable(HiveSyncTool.java:195)
at org.apache.hudi.hive.HiveSyncTool.doSync(HiveSyncTool.java:131)
at
org.apache.hudi.hive.HiveSyncTool.syncHoodieTable(HiveSyncTool.java:117)
... 20 more
Caused by: org.apache.hudi.hive.HoodieHiveSyncException: Failed in executing
SQL ALTER TABLE `CURRENCY_TICKS` ADD IF NOT EXISTS PARTITION
(`date`='+4231264-04-24') LOCATION 's3://CURRENCY_TICKS/+4231264-04-24'
PARTITION (`date`='+1409109-05-31') LOCATION
's3://CURRENCY_TICKS/+1409109-05-31'
at org.apache.hudi.hive.ddl.JDBCExecutor.runSQL(JDBCExecutor.java:59)
at
org.apache.hudi.hive.ddl.QueryBasedDDLExecutor.lambda$addPartitionsToTable$0(QueryBasedDDLExecutor.java:114)
at
java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384)
at
java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647)
at
org.apache.hudi.hive.ddl.QueryBasedDDLExecutor.addPartitionsToTable(QueryBasedDDLExecutor.java:114)
at
org.apache.hudi.hive.HoodieHiveClient.addPartitionsToTable(HoodieHiveClient.java:114)
at
org.apache.hudi.hive.HiveSyncTool.syncPartitions(HiveSyncTool.java:334)
... 23 more
I think the issue is Json Arraytype in the payload, How can I successfully
ingest this kind of payload?
Thanks,
Nikul
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}