kepplertreet commented on issue #7388:
URL: https://github.com/apache/hudi/issues/7388#issuecomment-1340354970
Hi @xushiyan
Added the Hudi option
This is how the config looks like at the moment
`"hoodie.table.name": "<table_name>",
"hoodie.datasource.write.table.name": "<table_name>",
"hoodie.datasource.write.table.type" : "MERGE_ON_READ",
"hoodie.datasource.write.recordkey.field": "<primary_key>",
"hoodie.datasource.write.partitionpath.field" : "_year_month",
"hoodie.datasource.write.keygenerator.class":
"org.apache.hudi.keygen.SimpleKeyGenerator",
"hoodie.datasource.hive_sync.table" : "<table_name>",
"hoodie.datasource.hive_sync.database" : "<database_name>",
"hoodie.datasource.write.row.writer.enable" : "false",
"hoodie.insert.shuffle.parallelism" : 64,
"hoodie.upsert.shuffle.parallelism" : 64,
"hoodie.table.version": "4",
"hoodie.datasource.write.operation": "insert",
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.write.precombine.field": "_commit_time_ms",
"hoodie.datasource.write.commitmeta.key.prefix": "_",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.auto_create_database": "true",
"hoodie.datasource.hive_sync.support_timestamp": "false",
"hoodie.datasource.hive_sync.skip_ro_suffix": "true",
"hoodie.parquet.compression.codec": "snappy",
"hoodie.metrics.on": "false",
"hoodie.metadata.enable": "true",
"hoodie.metadata.metrics.enable": "false",
"hoodie.compact.inline": "true",
"hoodie.index.type": "BLOOM",
"hoodie.clean.automatic": "true",
"hoodie.clean.async": "false",
"hoodie.cleaner.commits.retained": 1,
"hoodie.clustering.inline": "true"
"hoodie.clustering.plan.strategy.sort.columns": "<record_key_field>",
"hoodie.clustering.plan.strategy.class":
"org.apache.hudi.client.clustering.plan.strategy.SparkSizeBasedClusteringPlanStrategy",
"hoodie.clustering.execution.strategy.class": "
org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy",
"hoodie.clustering.inline.max.commits": 1,
"hoodie.clustering.plan.strategy.target.file.max.bytes": "268435456",
"hoodie.clustering.plan.strategy.small.file.limit": "209715200" `
**Now it seems to throw and exception**
# Stack Trace
`Exception Occurred in DataSourceWriter:
An error occurred while calling o136.save.
: org.apache.hudi.exception.HoodieException: Unable to load class
at
org.apache.hudi.common.util.ReflectionUtils.getClass(ReflectionUtils.java:57)
at
org.apache.hudi.common.util.ReflectionUtils.loadClass(ReflectionUtils.java:89)
at
org.apache.hudi.table.action.commit.BaseCommitActionExecutor.executeClustering(BaseCommitActionExecutor.java:245)
at
org.apache.hudi.table.action.cluster.SparkExecuteClusteringCommitActionExecutor.execute(SparkExecuteClusteringCommitActionExecutor.java:53)
at
org.apache.hudi.table.HoodieSparkCopyOnWriteTable.cluster(HoodieSparkCopyOnWriteTable.java:188)
at
org.apache.hudi.client.SparkRDDWriteClient.cluster(SparkRDDWriteClient.java:363)
at
org.apache.hudi.client.BaseHoodieWriteClient.lambda$inlineClustering$16(BaseHoodieWriteClient.java:1364)
at org.apache.hudi.common.util.Option.ifPresent(Option.java:97)
at
org.apache.hudi.client.BaseHoodieWriteClient.inlineClustering(BaseHoodieWriteClient.java:1362)
at
org.apache.hudi.client.BaseHoodieWriteClient.runTableServicesInline(BaseHoodieWriteClient.java:565)
at
org.apache.hudi.client.BaseHoodieWriteClient.commitStats(BaseHoodieWriteClient.java:245)
at
org.apache.hudi.client.SparkRDDWriteClient.commit(SparkRDDWriteClient.java:122)
at
org.apache.hudi.HoodieSparkSqlWriter$.commitAndPerformPostOperations(HoodieSparkSqlWriter.scala:684)
at
org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:316)
at
org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:173)
at
org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:103)
at
org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at
org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224)
at
org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:114)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$7(SQLExecution.scala:139)
at
org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at
org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:139)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:245)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:138)
at
org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:100)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:96)
at
org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:615)
at
org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:177)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:615)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:591)
at
org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:96)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:83)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:81)
at
org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:124)
at
org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:860)
at
org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:390)
at
org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:363)
at
org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:239)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at
py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at
py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.lang.ClassNotFoundException:
org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at
org.apache.hudi.common.util.ReflectionUtils.getClass(ReflectionUtils.java:54)
... 61 more
`
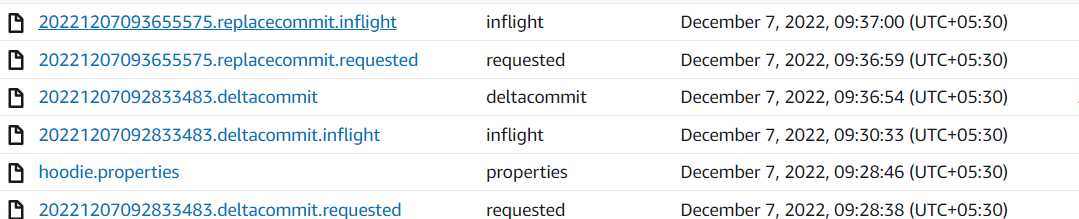
# Hudi Timeline
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}