koochiswathiTR opened a new issue, #7530:
URL: https://github.com/apache/hudi/issues/7530
Our application is spark streaming application runs on AWS EMR.
We read messages from kinesis stream. We see logs of hudi logs files
increasing day by day in our application, As per our understanding these log
files needs to clean up after compaction.
We keep only two days of logs files and will run compaction every 1 hour
Please find my hudi configurations.
Please help us to clean up on these files.
Quick resolution would be really appreciated.
DataSourceWriteOptions.TABLE_TYPE.key() ->
DataSourceWriteOptions.MOR_TABLE_TYPE_OPT_VAL,
DataSourceWriteOptions.RECORDKEY_FIELD.key() -> "guid",
DataSourceWriteOptions.PARTITIONPATH_FIELD.key() -> "collectionName",
DataSourceWriteOptions.PRECOMBINE_FIELD.key() -> "operationTime",
HoodieCompactionConfig.INLINE_COMPACT_TRIGGER_STRATEGY.key() ->
CompactionTriggerStrategy.TIME_ELAPSED.name,
//Compaction runs once per hour
HoodieCompactionConfig.INLINE_COMPACT_TIME_DELTA_SECONDS.key() ->
String.valueOf(60 * 60),
HoodieCompactionConfig.CLEANER_HOURS_RETAINED.key() -> "48",
HoodieCompactionConfig.CLEANER_POLICY.key() ->
HoodieCleaningPolicy.KEEP_LATEST_BY_HOURS.name,
HoodieCompactionConfig.ASYNC_CLEAN.key() -> "false",
HoodieCompactionConfig.INLINE_COMPACT.key() -> "true",
HoodieMetricsConfig.TURN_METRICS_ON.key() -> "true",
HoodieMetricsConfig.METRICS_REPORTER_TYPE_VALUE.key() ->
MetricsReporterType.DATADOG.name(),
HoodieMetricsDatadogConfig.API_SITE_VALUE.key() -> "US",
HoodieMetricsDatadogConfig.METRIC_PREFIX_VALUE.key() ->
"tacticalnovusingest.hudi",
HoodieMetricsDatadogConfig.API_KEY_SUPPLIER.key() -> "XXX",
HoodieMetadataConfig.ENABLE.key() -> "false",
HoodieWriteConfig.ROLLBACK_USING_MARKERS_ENABLE.key() -> "false"
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? Yes
- Join the mailing list to engage in conversations and get faster support at
[email protected].
- If you have triaged this as a bug, then file an
[issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
Because of the increased log files, compaction is taking time to look for
log files and waiting batches or unprocessed batches are increasing in spark
which is causing data latency.
A clear and concise description of the problem.
**Environment Description**
* Hudi version : 0.11.1
* Spark version : 3.2.1
* Hive version : NA
* Storage (HDFS/S3/GCS..) : S3
* EMR : 6.7
* Running on Docker? (yes/no) : NO
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```Add the stacktrace of the error.```
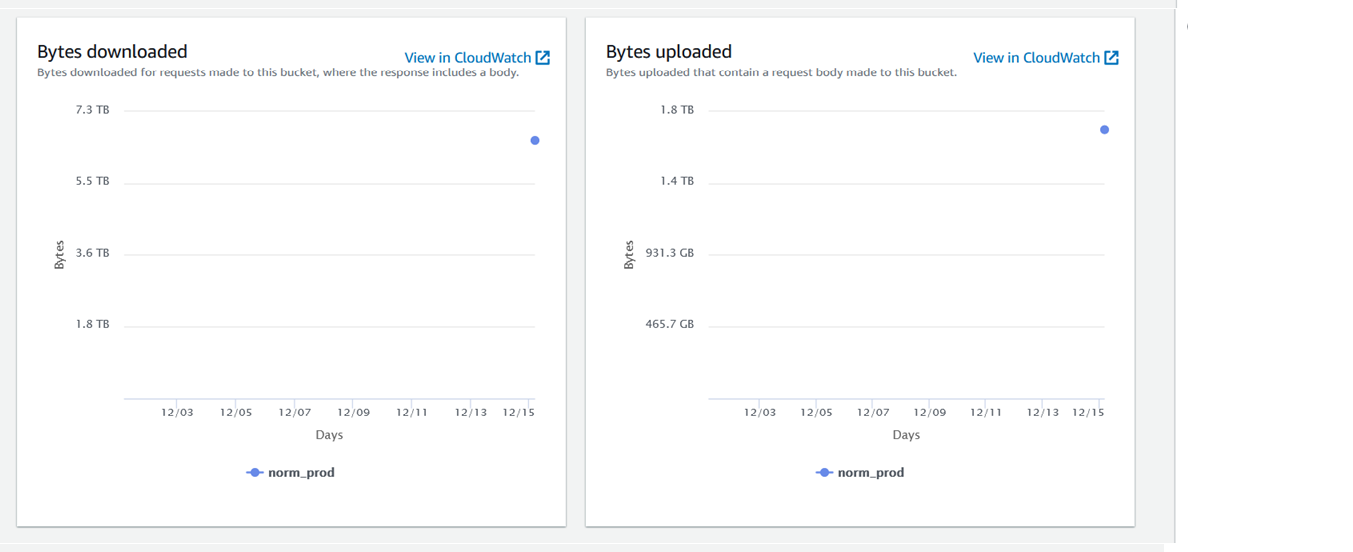
Attached files are my S3 Storage and s3 files,

506762/208889058-6da92349-25cb-4f81-aac9-5fed353f59e5.PNG)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}