soumilshah1995 opened a new issue, #7555:
URL: https://github.com/apache/hudi/issues/7555
```
import os
import sys
import uuid
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from pyspark.sql.types import *
from datetime import datetime
from functools import reduce
from faker import Faker
SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1
pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
def create_spark_session():
spark = SparkSession \
.builder \
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.getOrCreate()
return spark
spark = create_spark_session()
```
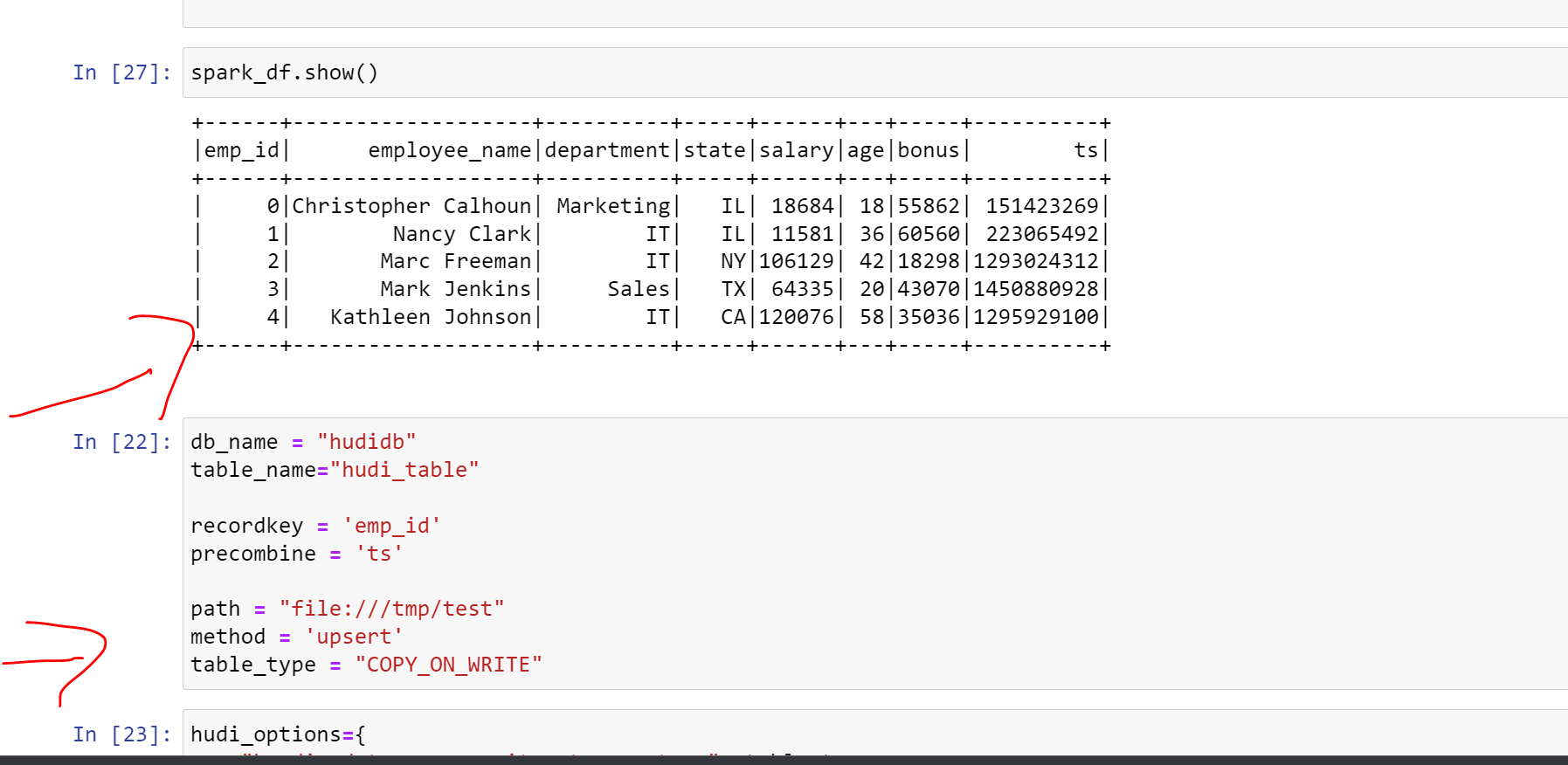
## When trying to insert data
```
Py4JJavaError: An error occurred while calling o157.save.
: java.lang.UnsatisfiedLinkError: 'boolean
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(java.lang.String, int)'
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at
org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:793)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1218)
at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1423)
at
org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:601)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1972)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:2014)
at
org.apache.hadoop.fs.ChecksumFileSystem.listStatus(ChecksumFileSystem.java:761)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1972)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:2014)
at
org.apache.hudi.common.fs.HoodieWrapperFileSystem.lambda$listStatus$19(HoodieWrapperFileSystem.java:589)
at
org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeMetrics(HoodieWrapperFileSystem.java:106)
at
org.apache.hudi.common.fs.HoodieWrapperFileSystem.listStatus(HoodieWrapperFileSystem.java:588)
at
org.apache.hudi.common.table.HoodieTableMetaClient.scanFiles(HoodieTableMetaClient.java:499)
at
org.apache.hudi.common.table.HoodieTableMetaClient.scanHoodieInstantsFromFileSystem(HoodieTableMetaClient.java:592)
at
org.apache.hudi.common.table.HoodieTableMetaClient.scanHoodieInstantsFromFileSystem(HoodieTableMetaClient.java:575)
at
org.apache.hudi.common.table.timeline.HoodieActiveTimeline.<init>(HoodieActiveTimeline.java:162)
at
org.apache.hudi.common.table.timeline.HoodieActiveTimeline.<init>(HoodieActiveTimeline.java:154)
at
org.apache.hudi.common.table.timeline.HoodieActiveTimeline.<init>(HoodieActiveTimeline.java:174)
at
org.apache.hudi.common.table.HoodieTableMetaClient.getActiveTimeline(HoodieTableMetaClient.java:338)
at
org.apache.hudi.common.table.HoodieTableMetaClient.getCommitsTimeline(HoodieTableMetaClient.java:515)
at
org.apache.hudi.common.table.HoodieTableMetaClient.isTimelineNonEmpty(HoodieTableMetaClient.java:506)
at
org.apache.hudi.common.table.TableSchemaResolver.getTableAvroSchemaFromLatestCommit(TableSchemaResolver.java:395)
at
org.apache.hudi.HoodieSparkSqlWriter$.getLatestTableSchema(HoodieSparkSqlWriter.scala:410)
at
org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:248)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:144)
at
org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:47)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:98)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:95)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:98)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:94)
at
org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:584)
at
org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:176)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:584)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:560)
at
org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:94)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:81)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:79)
at
org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:116)
at
org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:860)
at
org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:390)
at
org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:363)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:239)
at
java.base/jdk.internal.reflect.DirectMethodHandleAccessor.invoke(DirectMethodHandleAccessor.java:104)
at java.base/java.lang.reflect.Method.invoke(Method.java:578)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at
py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:1589)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}