maheshguptags commented on issue #7589: URL: https://github.com/apache/hudi/issues/7589#issuecomment-1370489489
Hi @yihua ,Thanks for looking into this. you are partially right but I want to preserve all the clustered file from 1 clustered file to till very end of the pipeline. let me give you the example. step 1 image : it contains the 3 commit of the file  step 2 image contain after the clustering file : 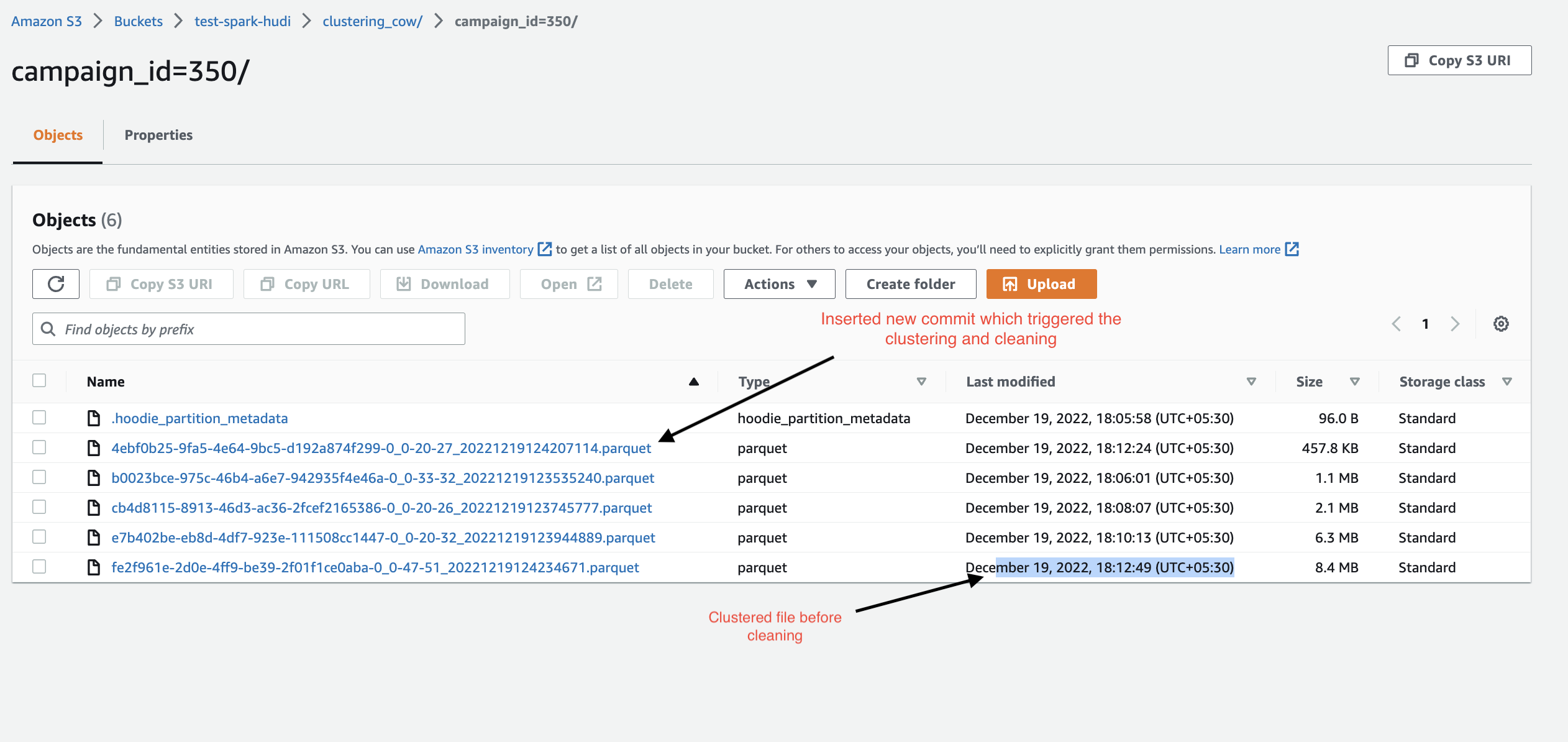 step 3 it contains only the clustered file and the latest commit files  step 4 image inserted few more commit then perform the clustering  Step 5 Image : Now this time clustering and cleaning will be triggered (4 commits completed) so it will clean the last cluster file (size exactly 8.4MB) and create new cluster file having all updated data. Whereas my wish is to preserve the old clustered file (8.4MB) file and create new clustered file. This way I will be able to maintain historical data of my process.  I hope I am able to explain the use case, If not we can quick catch up on call. Let me know your thought on this Thanks!! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}