duc-dn opened a new issue, #7806: URL: https://github.com/apache/hudi/issues/7806
**Describe the problem you faced** As I understand, Copy-on-Write storage mode boils down to copying the contents of the previous data to a new Parquet file, along with newly written data #### Hudi kafka connector - But, when I ingested data from the Kafka topic and saved data to minio. I tried to read the data file by pandas and I found that it doesn't right as the definition of Copy-on-write table - I send dummy data to Kafka topic. Afterward, I ingested data using hudi-kafka-connector (commit 1 time every 60s). After performing 2 commits, I stopped the commit.  - I read data files by pandas 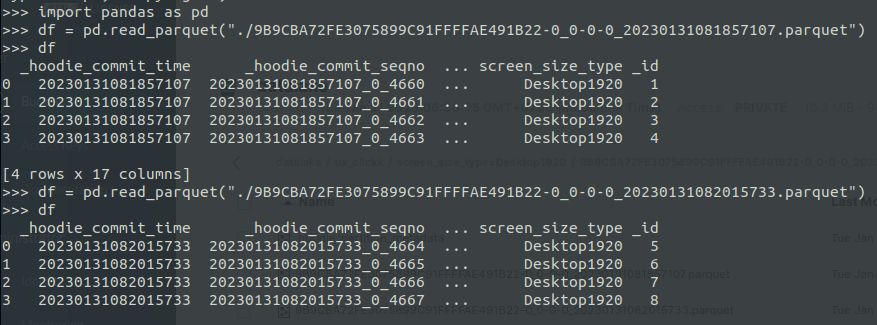 - According to the interpretation above, the 9B9CBA72FE3075899C91FFFFAE491B22-0_0-0-0_20230131082015733.parquet file has to copy records of 9B9CBA72FE3075899C91FFFFAE491B22-0_0-0-0_20230131081857107.parquet and merge new records --- #### Spark - I tried to ingest with spark and the above interpretation is correct. I performed 2 commits ``` val schema = StructType( Array( StructField("language", StringType, true), StructField("users", StringType, true), StructField("id", StringType, true) )) ``` - The first data ingestion ``` val rowData= Seq(Row("Python", "20000", "a"), Row("Python", "100000", "b"), Row("Python", "3000", "c")) val df = spark.createDataFrame(rowData, schema) ``` - The second data ingestion ``` val rowData= Seq(Row("Python", "20000", "d"), Row("Python", "100000", "e"), Row("Python", "3000", "f")) val df = spark.createDataFrame(rowData, schema) ``` - Save to minio ``` df.write.format("hudi"). option (TABLE_NAME, tableName). option (RECORDKEY_FIELD_OPT_KEY, "id"). option (PARTITIONPATH_FIELD_OPT_KEY, "language"). option (PRECOMBINE_FIELD_OPT_KEY, "users"). option("hoodie.datasource.write.hive_style_partitioning", "true"). option("hoodie.datasource.hive_sync.enable", "true"). option("hoodie.datasource.hive_sync.mode", "hms"). option("hoodie.datasource.hive_sync.database", "default"). option("hoodie.datasource.hive_sync.table", tableName). option("hoodie.datasource.hive_sync.partition_fields", "language"). option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor"). option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083"). mode (Append). save(basePath) ``` - There are data files  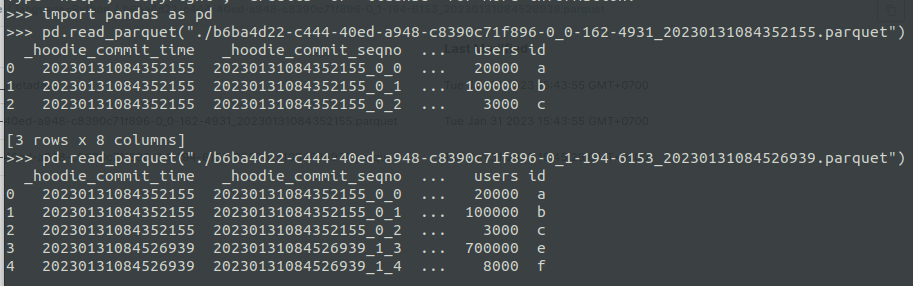 => Can anyone explain it to me and the way I understand about copy on write table like that is correct? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}