txl2017 opened a new issue, #7814: URL: https://github.com/apache/hudi/issues/7814
Analyzed Logical Plan got error when query hudi table use sparksql. java.lang.OutOfMemoryError: Java heap space 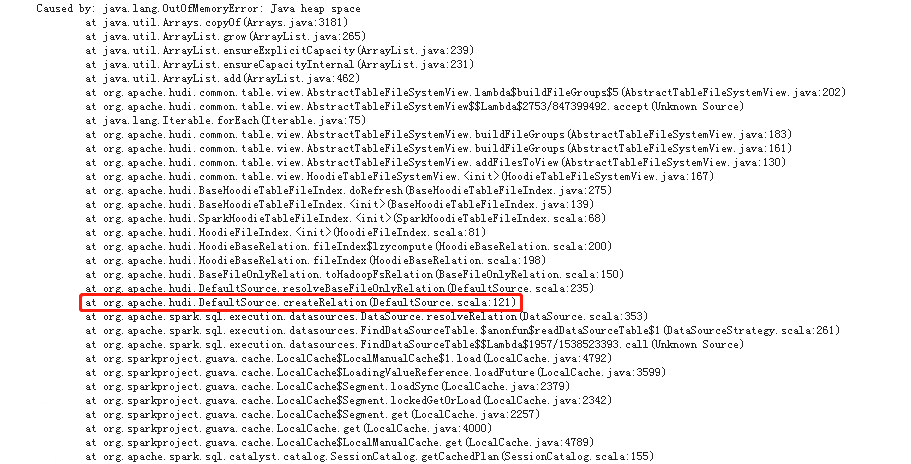 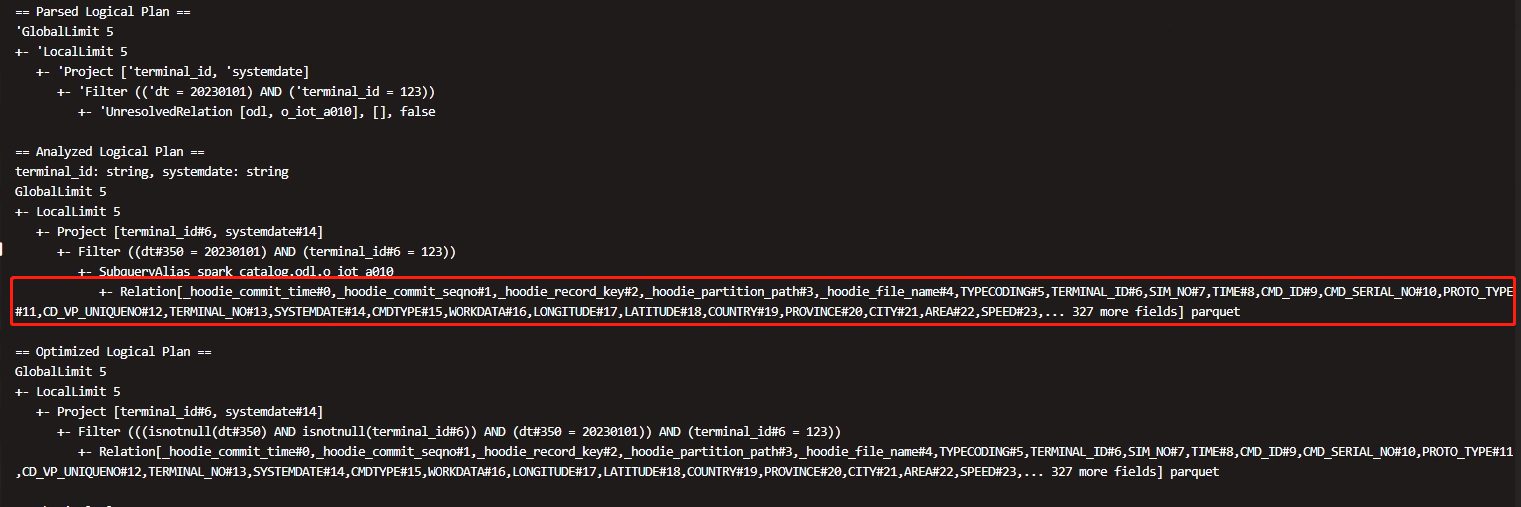 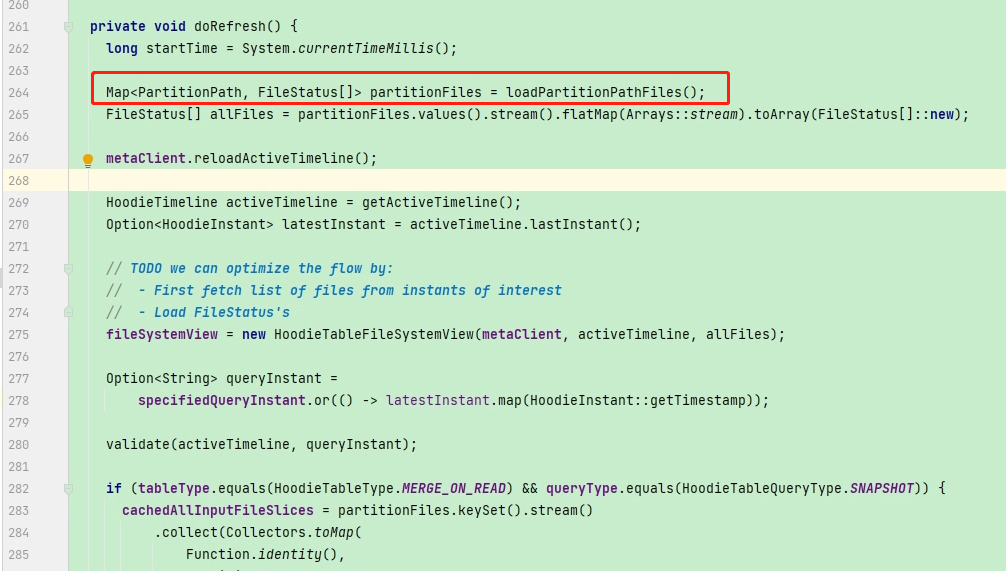 if relation only contain table fields info, why does hudi Load all partition paths and it's files under the query table path when in createRelation and it's real cost a lot of memory in spark driver. can we get table fields from the latest commit in createRelation? **Environment Description** * Hudi version : 0.11.1 * Spark version : 3.1.2 * Hive version : 2.1.1 * Hadoop version : 3.0.0 * Storage (HDFS/S3/GCS..) : hdfs * Running on Docker? (yes/no) : no **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}