soumilshah1995 opened a new issue, #8030:
URL: https://github.com/apache/hudi/issues/8030
Good Morning
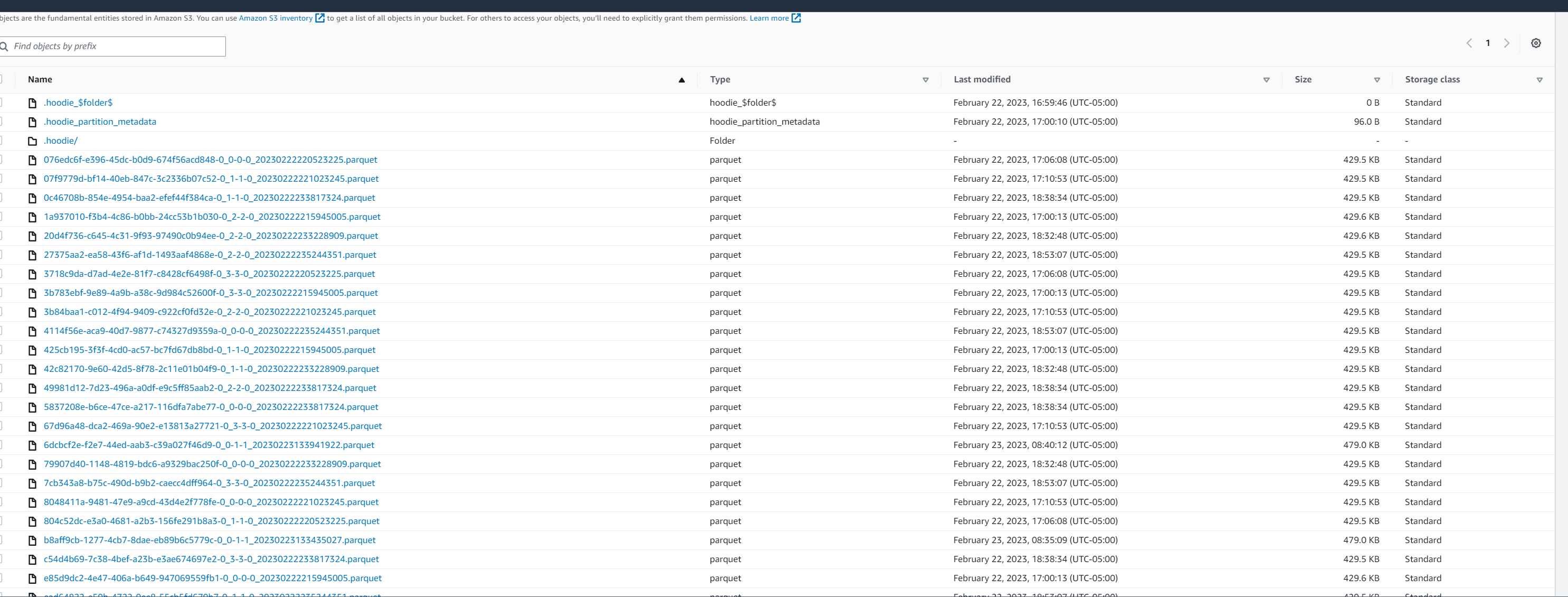
i am trying out following.
i have ingested some fake data into Hudi datalake and i am trying to figure
out if there is way to convert smaller files which are already in HUDI into
larger files. i know there is compaction
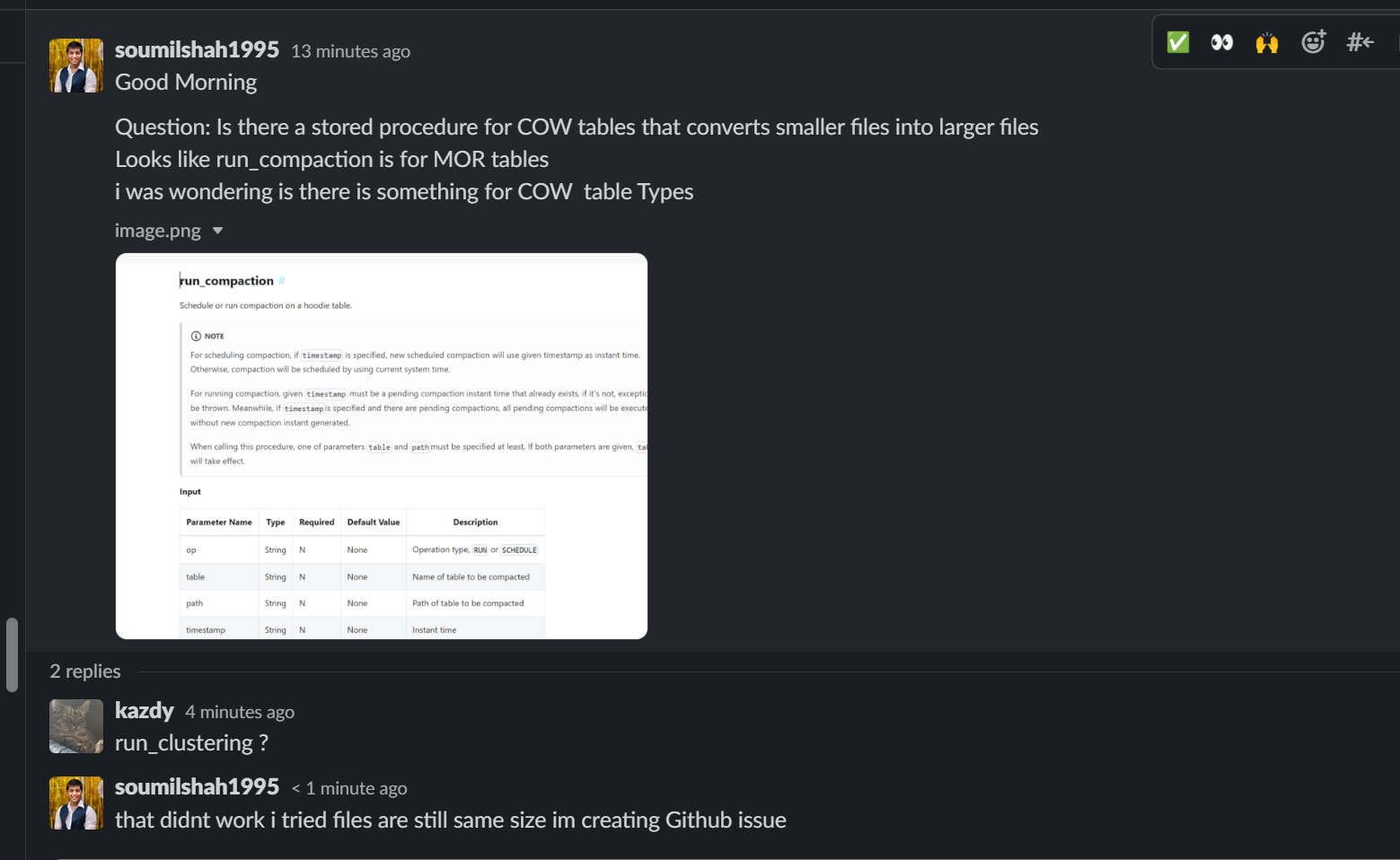
### Sample Code
```
try:
import sys
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.types import *
from datetime import datetime, date
import boto3
from functools import reduce
from pyspark.sql import Row
import uuid
from faker import Faker
except Exception as e:
print("Modules are missing : {} ".format(e))
job_start_ts = datetime.now()
ts_format = '%Y-%m-%d %H:%M:%S'
spark = (SparkSession.builder.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.catalog.spark_catalog',
'org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions',
'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled',
'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
uuid.uuid4().__str__(),
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales',
'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL',
'RJ')),
str(faker.random_int(min=10000, max=150000)),
str(faker.random_int(min=18, max=60)),
str(faker.random_int(min=0, max=100000)),
str(faker.unix_time()),
faker.email(),
faker.credit_card_number(card_type='amex'),
faker.date()
) for x in range(100)
]
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts", "email", "credit_card",
"date"]
spark_df = spark.createDataFrame(data=data, schema=columns)
# ============================== Settings
=======================================
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://hudi-demos-emr-serverless-project-soumil/tmp/"
method = 'bulk_insert'
table_type = "COPY_ON_WRITE"
#
====================================================================================
hudi_part_write_config = {
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.table.type': table_type,
'hoodie.datasource.write.operation': method,
'hoodie.bulkinsert.sort.mode': "NONE",
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.precombine.field': precombine,
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.support_timestamp': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name,
}
#
spark_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
# ================================================================
# Stored procedures
# ================================================================
# ================================================================
# Clustering
# ================================================================
show_clustering_query = f"call show_clustering('{db_name}.{table_name}')"
show_clustering_before_df = spark.sql(show_clustering_query)
query_run_clustering = f"call run_clustering('{db_name}.{table_name}')"
run_clustering_df = spark.sql(query_run_clustering)
print("\n")
show_clustering_after_df = spark.sql(show_clustering_query)
print(f"""
************STATS*************
show_clustering_query : {show_clustering_query}
show_clustering_before_df :{show_clustering_before_df.show()}
query_run_clustering : {query_run_clustering}
run_clustering_df : {run_clustering_df.show()}
show_clustering_after_df : {show_clustering_after_df.show()}
*******************************
""")
```
* Maybe I am missing some settings or configuration looking foreword for
help from community
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}