DavidZ1 opened a new issue, #8071: URL: https://github.com/apache/hudi/issues/8071
**_Tips before filing an issue_** - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** We currently have a car cloud business that consumes in real time through flink tasks and writes it into hudi. The source is kafka, and the messages of json in kafka are parsed. There are about **3600 fields** for hudi, 90% of which are of double type. However, our test found that flink writes to hudi at a faster speed It is relatively slow and cannot keep up with the speed of Kafka message production. We can't find the reason at present? A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1. 2. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. **Environment Description** * Hudi version :0.12.2 and 0.13.0 * Spark version : 3.2.2 * Hive version : 3.2.1 * Hadoop version : 3.2.2 * Storage (HDFS/S3/GCS..) : COS (cloud cloud ) * Running on Docker? (yes/no) : yes **Additional context** 1.Hudi config `checkpoint.interval=300 checkpoint.timeout=600 compaction.max_memory=1024 payload.class.name=org.apache.hudi.common.model.OverwriteNonDefaultsWithLatestAvroPayload compaction.delta_commits=20 compaction.trigger.strategy=num_or_time compaction.delta_seconds=3600 clean.policy=KEEP_LATEST_COMMITS clean.retain_commits=2 hoodie.bucket.index.num.buckets=40 archive.max_commits=50 archive.min_commits=40 table.type=MERGE_ON_READ hoodie.datasource.write.hive_style_partitioning=true index.type=BUCKET write.operation=upsert compaction.schedule.enabled=true compaction.async.enabled=true ` 2.kafka 24 partitions, 200G messages per hour, each message is a JSON format, flink obtains about 3600 signal field data (double) from the JSON message 3.flink We used 20 tasks (each task 2 core and 8gb memory) or 48 tasks (each task 1 core and 4gb memory) for the flink task. After running for an hour, we found that the speed of consumption could not keep up with the speed of message production. We use Tencent Cloud's streaming computing platform Oceanus: 1 computing CU includes 1 core CPU and 4GB memory. According to the difference between upstream and downstream and processing logic, the processing capacity of 1CU is about 5000 pieces/second to 50000 pieces/second. The computing performance of simple services is about 30,000 entries/second/core to 50,000 entries/second/core, and the computing performance of complex services is about 5,000 entries/second/core to 10,000 entries/second/core. When writing cos at the same time, there will be many small files, the maximum can reach 4000+. 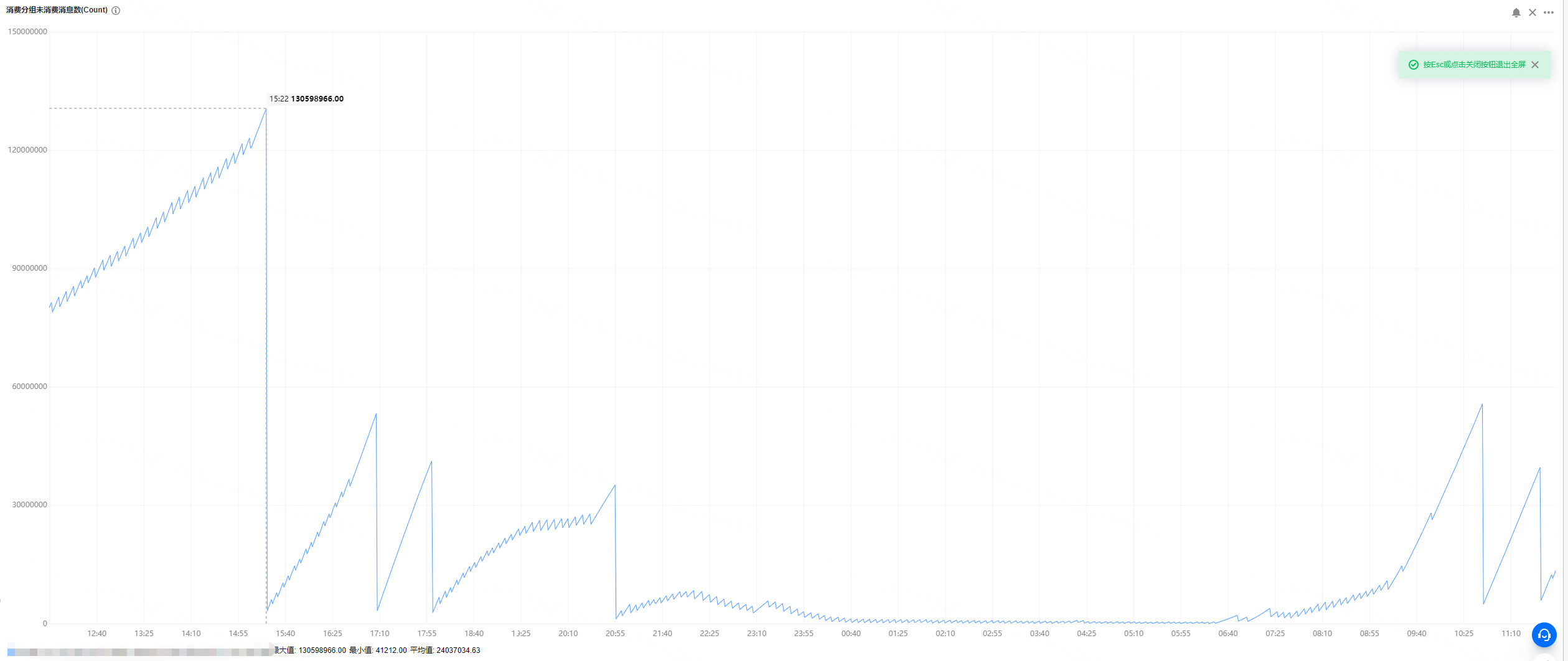 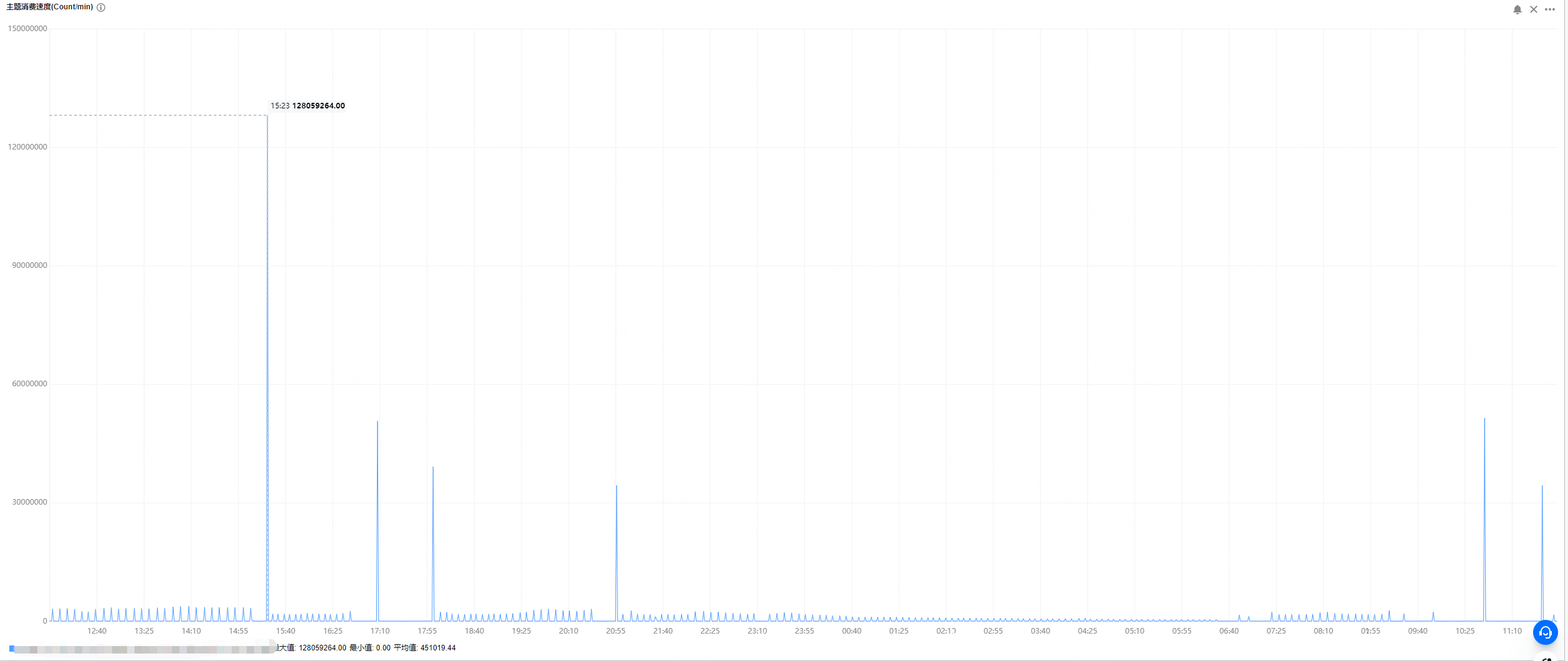 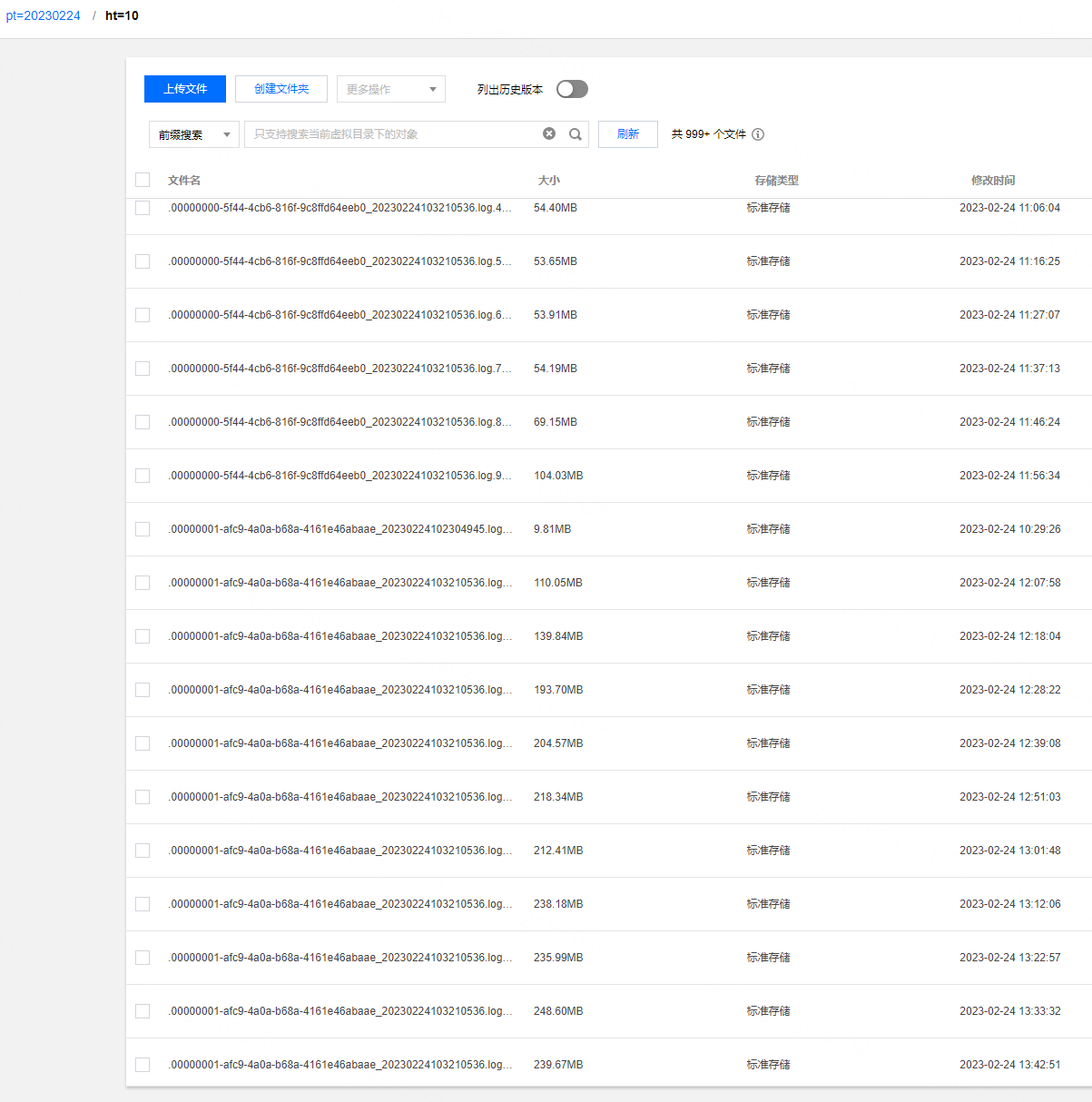 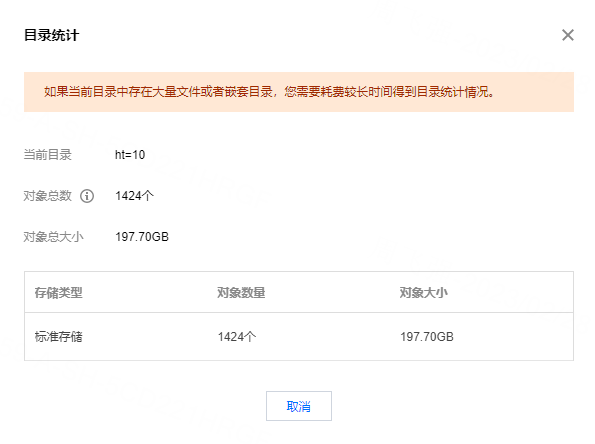 Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}