soumilshah1995 opened a new issue, #8112:
URL: https://github.com/apache/hudi/issues/8112
Hello i am trying to rollback to previous commit to see how the
functionality works
### Steps
#### Step1 I inserted some sample dataset and took save points
#### Step 2 : i tried rollback it throws error
## Code
```
try:
import sys
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.types import *
from datetime import datetime, date
import boto3
from functools import reduce
from pyspark.sql import Row
import uuid
from faker import Faker
except Exception as e:
print("Modules are missing : {} ".format(e))
job_start_ts = datetime.now()
ts_format = '%Y-%m-%d %H:%M:%S'
spark = (SparkSession.builder.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.catalog.spark_catalog',
'org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions',
'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled',
'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
uuid.uuid4().__str__(),
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales',
'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL',
'RJ')),
str(faker.random_int(min=10000, max=150000)),
str(faker.random_int(min=18, max=60)),
str(faker.random_int(min=0, max=100000)),
str(faker.unix_time()),
faker.email(),
faker.credit_card_number(card_type='amex'),
faker.date()
) for x in range(100)
]
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts", "email", "credit_card",
"date"]
spark_df = spark.createDataFrame(data=data, schema=columns)
# ============================== Settings
=======================================
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://hudi-demos-emr-serverless-project-soumil/backup/"
method = 'bulk_insert'
table_type = "COPY_ON_WRITE"
#
====================================================================================
hudi_part_write_config = {
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.table.type': table_type,
'hoodie.datasource.write.operation': method,
'hoodie.bulkinsert.sort.mode': "NONE",
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.precombine.field': precombine,
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.support_timestamp': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name,
}
#
spark_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
# =========================Stored procedures
========================================
try:
print("TRY 1")
roll_back_to_commit = "20230307121936430"
roll_back_query = f"call rollback_to_instant('{db_name}.{table_name}',
'{roll_back_to_commit}')"
print(roll_back_query)
spark_df = spark.sql(roll_back_query)
print(spark_df.show())
except Exception as e:
print("Failed roll back 1", e)
try:
print("TRY 2")
roll_back_to_commit = "20230307121936430"
roll_back_query = f"call rollback_savepoints('{db_name}.{table_name}',
'{roll_back_to_commit}')"
print(roll_back_query)
spark_df = spark.sql(roll_back_query)
print(spark_df.show())
except Exception as e:
print("Failed roll back 2", e)
# try:
# query_show_commits = f"call show_commits('{db_name}.{table_name}', 5)"
# spark_df_commits = spark.sql(query_show_commits)
# commits = list(map(lambda row: row[0], spark_df_commits.collect()))
#
# query_save_point = f"call create_savepoint('{db_name}.{table_name}',
'{commits[0]}')"
# execute_save_point = spark.sql(query_save_point)
#
# show_check_points_query = f"call
show_savepoints('{db_name}.{table_name}')"
# show_check_points_query_df = spark.sql(show_check_points_query)
#
#
# print(f"""
# ************STATS*************
# query {query_show_commits}
# spark_df {spark_df_commits.show()}
# commits {commits}
# Latest commit: {commits[0]}
#
# ############# Save Points ###########
# query: {query_save_point}
# save_point {execute_save_point.show()}
#
# ############# SHOW CHECK POINT ###########
# query: {show_check_points_query}
# show_check_points_query_df {show_check_points_query_df.show()}
# *******************************
# """)
#
# except Exception as e:
# print("Error : {} ".format(e))
```
### Note
i was able to do savepoints its just that i am not able to rollback
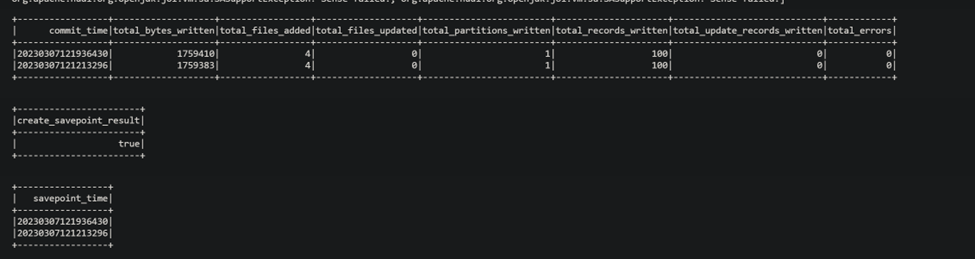
### Logs
```
<html>
<body>
<!--StartFragment-->
TRY 1call rollback_to_instant('hudidb.employees', '20230307121936430')
--
An error occurred while calling o91.sql.
: org.apache.hudi.exception.HoodieRollbackException: Failed to rollback
s3://hudi-demos-emr-serverless-project-soumil/backup commits 20230307121936430
at
org.apache.hudi.client.BaseHoodieWriteClient.rollback(BaseHoodieWriteClient.java:785)
at
org.apache.hudi.client.BaseHoodieWriteClient.rollback(BaseHoodieWriteClient.java:731)
at
org.apache.spark.sql.hudi.command.procedures.RollbackToInstantTimeProcedure.call(RollbackToInstantTimeProcedure.scala:73)
at
org.apache.spark.sql.hudi.command.CallProcedureHoodieCommand.run(CallProcedureHoodieCommand.scala:33)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73)
at
org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:103)
at
org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at
org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224)
at
org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:114)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$7(SQLExecution.scala:139)
at
org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107)
at
org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:224)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:139)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:245)
at
org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:138)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:100)
at
org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:96)
at
org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:615)
at
org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:177)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:615)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at
org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at
org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:591)
at
org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:96)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:83)
at
org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:81)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:222)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:102)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:99)
at
org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:622)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:617)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at
py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:750)
Caused by: org.apache.hudi.exception.HoodieRollbackException: Could not
rollback a savepointed commit. Delete savepoint first before rolling
back20230307121936430
at
org.apache.hudi.table.action.rollback.BaseRollbackActionExecutor.lambda$validateSavepointRollbacks$1(BaseRollbackActionExecutor.java:148)
at java.util.ArrayList.forEach(ArrayList.java:1259)
at
org.apache.hudi.table.action.rollback.BaseRollbackActionExecutor.validateSavepointRollbacks(BaseRollbackActionExecutor.java:146)
at
org.apache.hudi.table.action.rollback.BaseRollbackActionExecutor.doRollbackAndGetStats(BaseRollbackActionExecutor.java:208)
at
org.apache.hudi.table.action.rollback.BaseRollbackActionExecutor.runRollback(BaseRollbackActionExecutor.java:108)
at
org.apache.hudi.table.action.rollback.BaseRollbackActionExecutor.execute(BaseRollbackActionExecutor.java:135)
at
org.apache.hudi.table.HoodieSparkCopyOnWriteTable.rollback(HoodieSparkCopyOnWriteTable.java:281)
at
org.apache.hudi.client.BaseHoodieWriteClient.rollback(BaseHoodieWriteClient.java:768)
... 51 more
TRY 2
call rollback_savepoints('hudidb.employees', '20230307121936430')
Failed roll back 2
procedure: rollback_savepoints is not exists
```
please let me know if i am doing something wrong :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}