gbzy opened a new issue, #8180:
URL: https://github.com/apache/hudi/issues/8180
**Describe the problem you faced**
We found snapshot queries did not merge the base and delta files of the
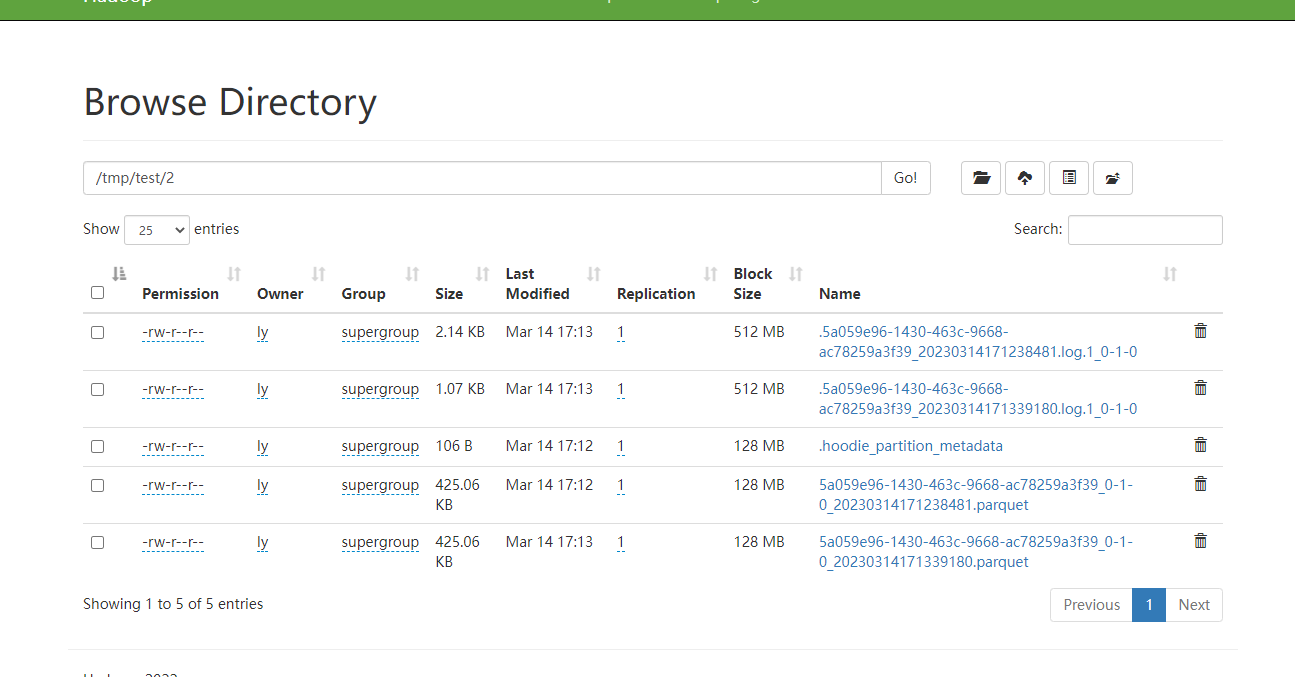
latest file slice on-the-fly. From the console logs, we can see that the
MergeOnReadInputSplit's basePath is empty, but the base file existed.
`17:13:15,384 INFO org.apache.hudi.source.StreamReadOperator
[] - Processing input split : MergeOnReadInputSplit{splitNum=0,
basePath=Optional.empty,
logPaths=Option{val=[hdfs://192.168.80.50:9000/tmp/test/2/.5a059e96-1430-463c-9668-ac78259a3f39_20230314171238481.log.1_0-1-0]},
latestCommit='20230314171238638',
tablePath='hdfs://192.168.80.50:9000/tmp/test',
maxCompactionMemoryInBytes=104857600, mergeType='payload_combine',
instantRange=Option{val=org.apache.hudi.common.table.log.InstantRange$CloseCloseRange@ad0189e}}`
>
+----+--------------------------------+--------------------------------+-------------+-------------+--------------------------------+
>| op | id | name |
age | score | part |
>+----+--------------------------------+--------------------------------+-------------+-------------+--------------------------------+
>| +I | id1 | (NULL) |
(NULL) | 93 | 2 |
Here is the DDL
> CREATE TABLE t1(
id VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
score INT,
`part` VARCHAR(40),
ts TIMESTAMP(3)
)
PARTITIONED BY (`part`)
WITH (
'connector' = 'hudi-oss',
'path' = 'hdfs://192.168.80.50:9000/tmp/test',
'payload.class' = 'org.apache.hudi.common.model.PartialUpdateAvroPayload',
'clean.retain_commits' = '2',
'write.operation' = 'upsert',
'write.tasks' = '1',
'metadata.enabled' = 'true',
'hoodie.datasource.query.type' = 'snapshot',"
'read.streaming.enabled' = 'true', "
'read.streaming.check-interval' = '10',"
'table.type' = 'MERGE_ON_READ'
)
**Expected behavior**
Snapshot quries should merge the base and delta files of the latest file
slice on-the-fly.
**Environment Description**
* Hudi version : 0.13.0
* Hadoop version : 3.3.4
* Storage (HDFS/S3/GCS..) : hdfs
* Running on Docker? (yes/no) : no
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}