soumilshah1995 opened a new issue, #8400:
URL: https://github.com/apache/hudi/issues/8400
Subject : Need Help on Compaction Offline for MOR tables
Good Afternoon and hope you are fine I would want some assistance for next
content I am creating on hudi offline compaction for
MOR tables
After searching and reading I would seek some guidance on how to submit
offline compaction and if I am missing anything
Attaching sample code
```
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv(".env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = "us-east-1"
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ------------------Hudi settings
---------------------------------------------
glue_db = "hudi_db"
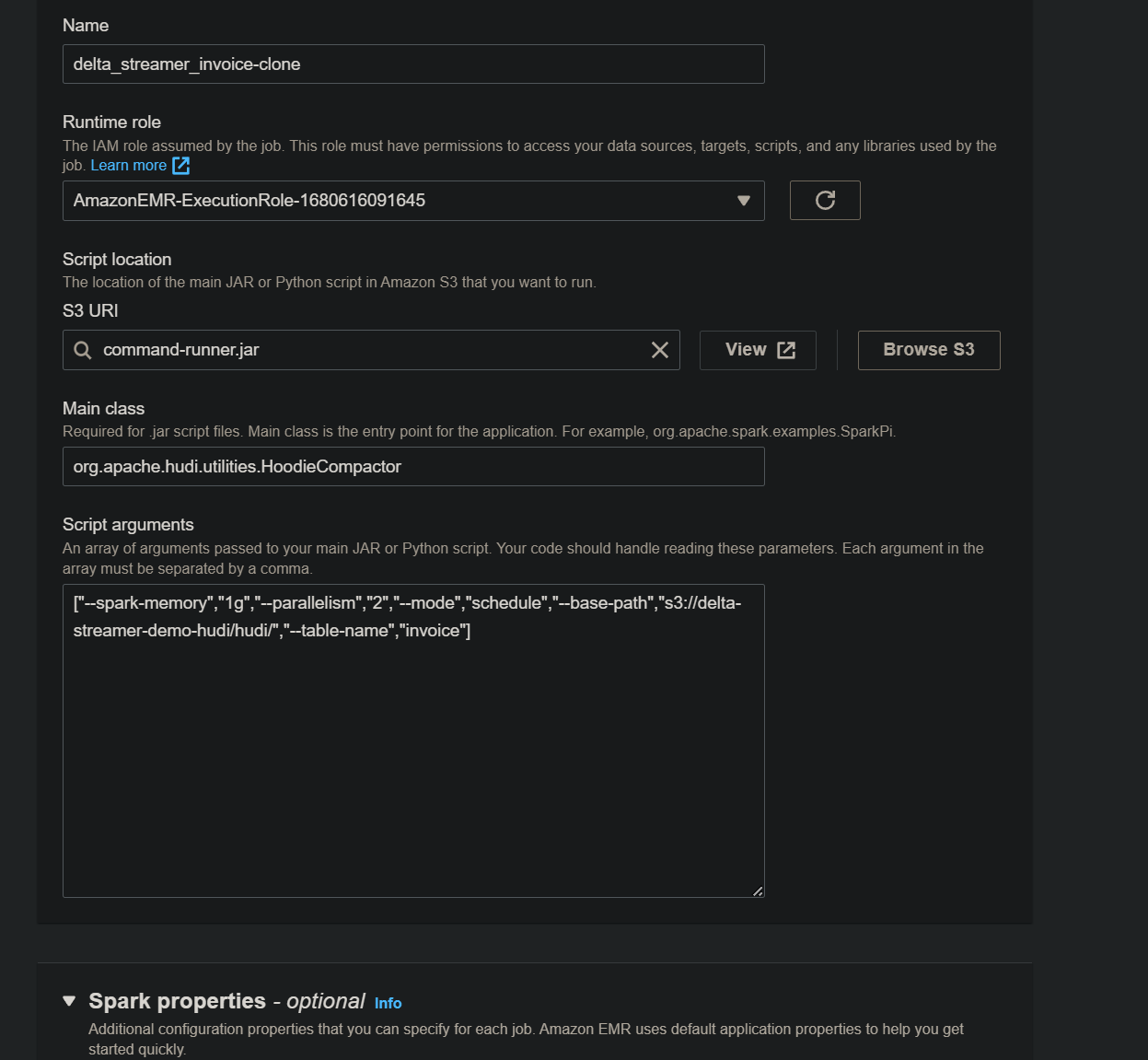
table_name = "invoice"
path = "s3://delta-streamer-demo-hudi/hudi/"
#
---------------------------------------------------------------------------------
# EMR
#
--------------------------------------------------------------------------------
ApplicationId = os.getenv("ApplicationId")
ExecutionTime = 600
ExecutionArn = os.getenv("ExecutionArn")
JobName = 'delta_streamer_{}'.format(table_name)
#
--------------------------------------------------------------------------------
spark_submit_parameters = ' --conf
spark.jars=/usr/lib/hudi/hudi-utilities-bundle.jar'
spark_submit_parameters += ' --class
org.apache.hudi.utilities.HoodieCompactor
/usr/lib/hudi/hudi-utilities-bundle.jar'
arguments = [
'--spark-memory', '1g',
'--parallelism', '2',
"--mode", "schedule",
"--base-path", path,
"--table-name", table_name
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': "command-runner.jar",
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
# Error
```
Job failed, please check complete logs in configured logging destination.
ExitCode: 1. Last few exceptions: Exception in thread "main"
org.apache.hudi.com.beust.jcommander.ParameterException: Was passed main
parameter 'command-runner.jar' but no main parameter was defined in your arg
```
looking fwd for your guidance
References
https://hudi.apache.org/docs/compaction/
https://github.com/apache/hudi/issues/6903
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}