soumilshah1995 opened a new issue, #8401: URL: https://github.com/apache/hudi/issues/8401
I would like to inform you that I have created a new ticket regarding the issue at hand. As per the user's request, I have created a separate ticket for this issue, which will enable us to better track and address the issue at hand. The reference ticket number is [insert ticket number], and you can find more details about it at this link: https://github.com/apache/hudi/issues/8040 For your reference, the previous ticket number is [8040]. I have included this information in my new ticket for easy access to any relevant details that were previously provided. Thank you for your attention to this matter. Please let me know if there is any additional information that I can provide to assist in resolving this issue. # Code ``` try: import sys import os from pyspark.context import SparkContext from pyspark.sql.session import SparkSession from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when from pyspark.sql.functions import * from awsglue.utils import getResolvedOptions from pyspark.sql.types import * from datetime import datetime, date import boto3 from functools import reduce from pyspark.sql import Row import uuid from faker import Faker except Exception as e: print("Modules are missing : {} ".format(e)) spark = (SparkSession.builder.config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer') \ .config('spark.sql.hive.convertMetastoreParquet', 'false') \ .config('spark.sql.catalog.spark_catalog', 'org.apache.spark.sql.hudi.catalog.HoodieCatalog') \ .config('spark.sql.extensions', 'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \ .config('spark.sql.legacy.pathOptionBehavior.enabled', 'true').getOrCreate()) sc = spark.sparkContext glueContext = GlueContext(sc) job = Job(glueContext) logger = glueContext.get_logger() # =================================INSERTING DATA ===================================== global faker faker = Faker() class DataGenerator(object): @staticmethod def get_data(): return [ ( uuid.uuid4().__str__(), faker.name(), faker.random_element(elements=('IT', 'HR', 'Sales', 'Marketing')), faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL', 'RJ')), str(faker.random_int(min=10000, max=150000)), str(faker.random_int(min=18, max=60)), str(faker.random_int(min=0, max=100000)), str(faker.unix_time()), faker.email(), faker.credit_card_number(card_type='amex'), ) for x in range(100) ] data = DataGenerator.get_data() columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts", "email", "credit_card"] spark_df = spark.createDataFrame(data=data, schema=columns) # ============================== Settings ======================================= db_name = "hudidb" table_name = "employees" recordkey = 'emp_id' precombine = "ts" PARTITION_FIELD = 'state' path = "s3://hudi-demos-emr-serverless-project-soumil/tmp1/" method = 'upsert' table_type = "MERGE_ON_READ" # ==================================================================================== hudi_part_write_config = { 'className': 'org.apache.hudi', "hoodie.schema.on.read.enable":"true", "hoodie.datasource.write.reconcile.schema":"true", "hoodie.avro.schema.external.transformation":"true", 'hoodie.avro.schema.validate':"true", "hoodie.datasource.write.schema.allow.auto.evolution.column.drop":"true", 'hoodie.table.name': table_name, 'hoodie.datasource.write.table.type': table_type, 'hoodie.datasource.write.operation': method, 'hoodie.datasource.write.recordkey.field': recordkey, 'hoodie.datasource.write.precombine.field': precombine, 'hoodie.datasource.hive_sync.mode': 'hms', 'hoodie.datasource.hive_sync.enable': 'true', 'hoodie.datasource.hive_sync.use_jdbc': 'false', 'hoodie.datasource.hive_sync.support_timestamp': 'false', 'hoodie.datasource.hive_sync.database': db_name, 'hoodie.datasource.hive_sync.table': table_name, } spark_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path) # ================================================================ # Adding NEW COLUMN # ================================================================ class DataGenerator(object): @staticmethod def get_data(): return [ ( uuid.uuid4().__str__(), faker.name(), faker.random_element(elements=('IT', 'HR', 'Sales', 'Marketing')), faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL', 'RJ')), str(faker.random_int(min=10000, max=150000)), str(faker.random_int(min=18, max=60)), str(faker.random_int(min=0, max=100000)), str(faker.unix_time()), faker.email(), faker.credit_card_number(card_type='amex'), faker.date().__str__() ) for x in range(100) ] data = DataGenerator.get_data() columns = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts", "email", "credit_card", "new_date_col"] spark_df = spark.createDataFrame(data=data, schema=columns) spark_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path) try: print("Try1") table_name_test = f"{table_name}_ro" query = f"alter table {db_name}.{table_name_test} drop column credit_card" spark.sql(query) except Exception as e: print("ERR1", e) try: print("Try2") table_name_test = f"{table_name}_rt" query = f"alter table {db_name}.{table_name_test} drop column credit_card" spark.sql(query) except Exception as e: print("ERR2", e) ``` 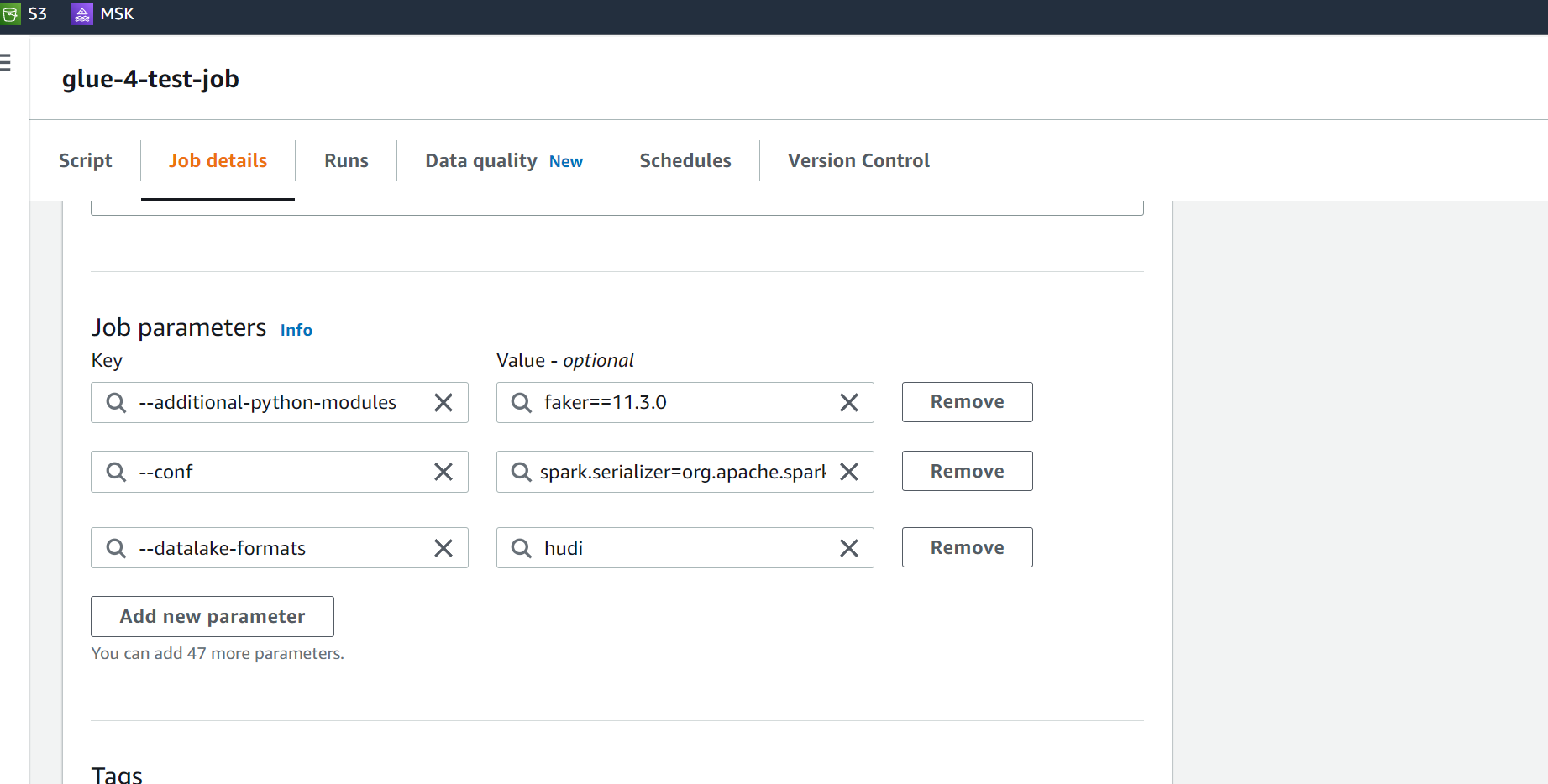 ``` --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog --conf spark.sql.legacy.pathOptionBehavior.enabled=true --conf spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension ``` # Error 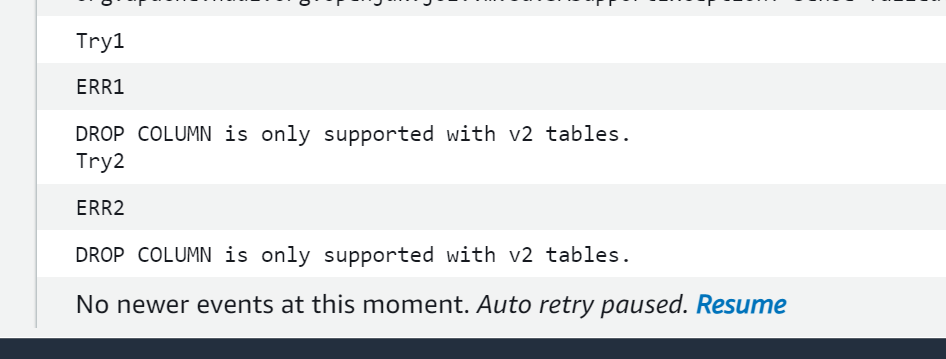 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}