soumilshah1995 commented on issue #8400:
URL: https://github.com/apache/hudi/issues/8400#issuecomment-1520570741
# GLue Job
```
try:
import sys
import os
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from awsglue.utils import getResolvedOptions
from pyspark.sql.types import *
from datetime import datetime, date
import boto3
from functools import reduce
from pyspark.sql import Row
import uuid
from faker import Faker
except Exception as e:
print("Modules are missing : {} ".format(e))
spark = (SparkSession.builder.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.catalog.spark_catalog',
'org.apache.spark.sql.hudi.catalog.HoodieCatalog') \
.config('spark.sql.extensions',
'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.legacy.pathOptionBehavior.enabled',
'true').getOrCreate())
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
logger = glueContext.get_logger()
# =================================INSERTING DATA
=====================================
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
x,
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales',
'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL',
'RJ')),
str(faker.random_int(min=10000, max=150000)),
str(faker.random_int(min=18, max=60)),
str(faker.random_int(min=0, max=100000)),
str(faker.unix_time()),
faker.email(),
faker.credit_card_number(card_type='amex'),
) for x in range(5)
]
# ============================== Settings
=======================================
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://delta-streamer-demo-hudi/hudi/"
method = 'upsert'
table_type = "MERGE_ON_READ"
#
====================================================================================
hudi_part_write_config = {
'className': 'org.apache.hudi',
'hoodie.table.name': table_name,
'hoodie.datasource.write.table.type': table_type,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.precombine.field': precombine,
"hoodie.schema.on.read.enable": "true",
"hoodie.datasource.write.reconcile.schema": "true",
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.support_timestamp': 'false',
'hoodie.datasource.hive_sync.database': db_name,
'hoodie.datasource.hive_sync.table': table_name
, "hoodie.clean.automatic": "false"
, "hoodie.clean.async": "false"
, "hoodie.clustering.async.enabled": "false"
, "hoodie.metadata.enable": "false"
, "hoodie.metadata.index.async": "false"
, "hoodie.metadata.index.column.stats.enable": "false"
, "hoodie.compact.inline": "false"
, 'hoodie.compact.schedule.inline': 'true'
, "hoodie.metadata.index.check.timeout.seconds": "60"
, "hoodie.write.concurrency.mode": "optimistic_concurrency_control"
, "hoodie.write.lock.provider":
"org.apache.hudi.client.transaction.lock.InProcessLockProvider"
}
# ====================================================
"""Create Spark Data Frame """
# ====================================================
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
df = spark.createDataFrame(data=data, schema=columns)
df.write.format("hudi").options(**hudi_part_write_config).mode("overwrite").save(path)
# ====================================================
"""APPEND """
# ====================================================
impleDataUpd = [
(6, "This is APPEND", "Sales", "RJ", 81000, 30, 23000, 827307999),
(7, "This is APPEND", "Engineering", "RJ", 79000, 53, 15000, 1627694678),
]
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
usr_up_df = spark.createDataFrame(data=impleDataUpd, schema=columns)
usr_up_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
# ====================================================
"""UPDATE """
# ====================================================
impleDataUpd = [
(3, "this is update 1 on data lake", "Sales", "RJ", 81000, 30, 23000,
827307999),
]
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
usr_up_df = spark.createDataFrame(data=impleDataUpd, schema=columns)
usr_up_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
impleDataUpd = [
(3, "this is update 2 on data lake", "Sales", "RJ", 81000, 30, 23000,
827307999),
]
columns = ["emp_id", "employee_name", "department", "state", "salary",
"age", "bonus", "ts"]
usr_up_df = spark.createDataFrame(data=impleDataUpd, schema=columns)
usr_up_df.write.format("hudi").options(**hudi_part_write_config).mode("append").save(path)
```
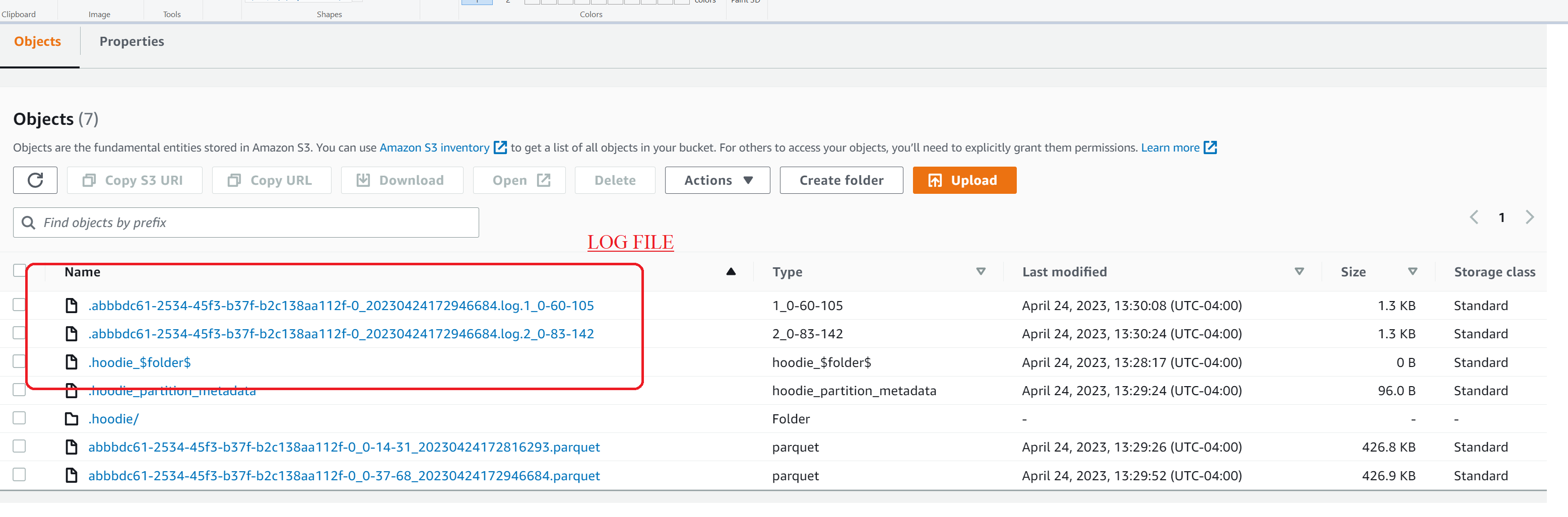
# Hudi Data Lake
# EMR Job
```
try:
import json
import uuid
import os
import boto3
from dotenv import load_dotenv
load_dotenv("../.env")
except Exception as e:
pass
global AWS_ACCESS_KEY
global AWS_SECRET_KEY
global AWS_REGION_NAME
AWS_ACCESS_KEY = os.getenv("DEV_ACCESS_KEY")
AWS_SECRET_KEY = os.getenv("DEV_SECRET_KEY")
AWS_REGION_NAME = "us-east-1"
client = boto3.client("emr-serverless",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION_NAME)
def lambda_handler_test_emr(event, context):
# ============================== Settings
=======================================
db_name = "hudidb"
table_name = "employees"
recordkey = 'emp_id'
precombine = "ts"
PARTITION_FIELD = 'state'
path = "s3://delta-streamer-demo-hudi/hudi/"
method = 'upsert'
table_type = "MERGE_ON_READ"
#
====================================================================================
#
---------------------------------------------------------------------------------
# EMR
#
--------------------------------------------------------------------------------
ApplicationId = os.getenv("ApplicationId")
ExecutionTime = 600
ExecutionArn = os.getenv("ExecutionArn")
JobName = 'delta_streamer_compaction_{}'.format(table_name)
#
--------------------------------------------------------------------------------
spark_submit_parameters = ' --conf
spark.serializer=org.apache.spark.serializer.KryoSerializer'
spark_submit_parameters += ' --class
org.apache.hudi.utilities.HoodieCompactor'
jar_path =
"s3://delta-streamer-demo-hudi/jar_test/hudi-utilities-bundle_2.12-0.13.0.jar"
# schedule | execute | scheduleAndExecute
arguments = [
'--spark-memory', '5g',
'--parallelism', '2',
"--mode", "scheduleAndExecute",
"--base-path", path,
"--table-name", table_name,
"--hoodie-conf",
"hoodie.datasource.write.recordkey.field={}".format(recordkey),
"--hoodie-conf",
"hoodie.datasource.write.precombine.field={}".format(precombine),
"--hoodie-conf", "hoodie.metadata.index.async=false",
"--hoodie-conf", "hoodie.metadata.enable=false"
]
response = client.start_job_run(
applicationId=ApplicationId,
clientToken=uuid.uuid4().__str__(),
executionRoleArn=ExecutionArn,
jobDriver={
'sparkSubmit': {
'entryPoint': jar_path,
'entryPointArguments': arguments,
'sparkSubmitParameters': spark_submit_parameters
},
},
executionTimeoutMinutes=ExecutionTime,
name=JobName,
)
print("response", end="\n")
print(response)
lambda_handler_test_emr(context=None, event=None)
```
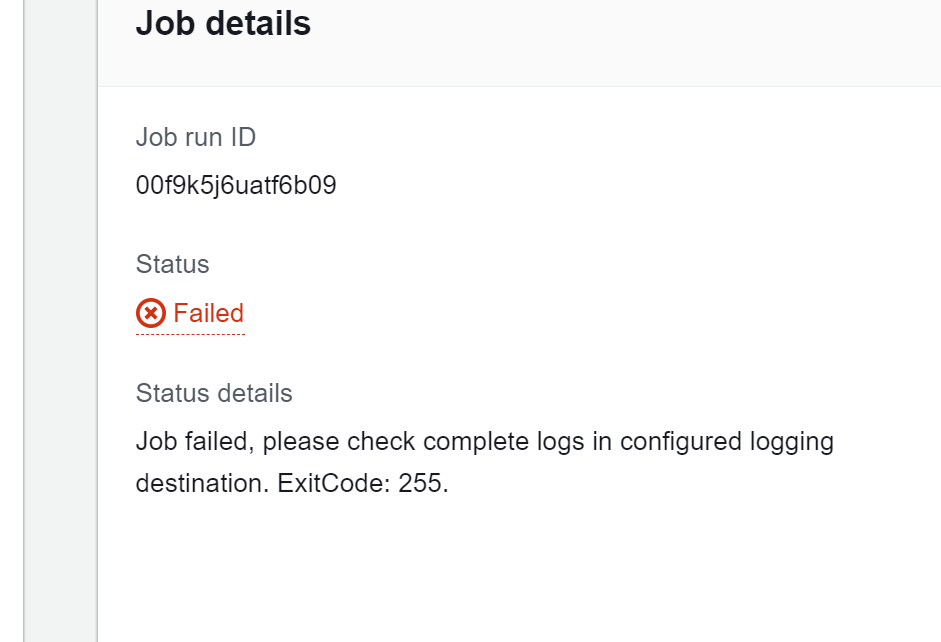
# Error
# Stdrout
```
23/04/24 17:32:45 INFO SparkContext: Running Spark version 3.3.1-amzn-0
23/04/24 17:32:45 INFO ResourceUtils:
==============================================================
23/04/24 17:32:45 INFO ResourceUtils: No custom resources configured for
spark.driver.
23/04/24 17:32:45 INFO ResourceUtils:
==============================================================
23/04/24 17:32:45 INFO SparkContext: Submitted application:
compactor-employees
23/04/24 17:32:45 INFO ResourceProfile: Default ResourceProfile created,
executor resources: Map(cores -> name: cores, amount: 4, script: , vendor: ,
memory -> name: memory, amount: 5120, script: , vendor: , offHeap -> name:
offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name:
cpus, amount: 1.0)
23/04/24 17:32:45 INFO ResourceProfile: Limiting resource is cpus at 4 tasks
per executor
23/04/24 17:32:46 INFO ResourceProfileManager: Added ResourceProfile id: 0
23/04/24 17:32:46 INFO SecurityManager: Changing view acls to: hadoop
23/04/24 17:32:46 INFO SecurityManager: Changing modify acls to: hadoop
23/04/24 17:32:46 INFO SecurityManager: Changing view acls groups to:
23/04/24 17:32:46 INFO SecurityManager: Changing modify acls groups to:
23/04/24 17:32:46 INFO SecurityManager: SecurityManager: authentication
enabled; ui acls disabled; users with view permissions: Set(hadoop); groups
with view permissions: Set(); users with modify permissions: Set(hadoop);
groups with modify permissions: Set()
23/04/24 17:32:46 INFO deprecation: mapred.output.compression.codec is
deprecated. Instead, use mapreduce.output.fileoutputformat.compress.codec
23/04/24 17:32:46 INFO deprecation: mapred.output.compression.type is
deprecated. Instead, use mapreduce.output.fileoutputformat.compress.type
23/04/24 17:32:46 INFO deprecation: mapred.output.compress is deprecated.
Instead, use mapreduce.output.fileoutputformat.compress
23/04/24 17:32:46 INFO Utils: Successfully started service 'sparkDriver' on
port 38683.
23/04/24 17:32:46 INFO SparkEnv: Registering MapOutputTracker
23/04/24 17:32:46 INFO SparkEnv: Registering BlockManagerMaster
23/04/24 17:32:46 INFO BlockManagerMasterEndpoint: Using
org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/04/24 17:32:46 INFO BlockManagerMasterEndpoint:
BlockManagerMasterEndpoint up
23/04/24 17:32:46 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
23/04/24 17:32:46 INFO DiskBlockManager: Created local directory at
/tmp/blockmgr-8f446246-8819-4282-bb21-cd9202f28988
23/04/24 17:32:46 INFO MemoryStore: MemoryStore started with capacity 7.3 GiB
23/04/24 17:32:46 INFO SparkEnv: Registering OutputCommitCoordinator
23/04/24 17:32:46 INFO SubResultCacheManager: Sub-result caches are disabled.
23/04/24 17:32:46 INFO Utils: Successfully started service 'SparkUI' on port
8090.
23/04/24 17:32:46 INFO SparkContext: Added JAR
s3://delta-streamer-demo-hudi/jar_test/hudi-utilities-bundle_2.12-0.13.0.jar at
s3://delta-streamer-demo-hudi/jar_test/hudi-utilities-bundle_2.12-0.13.0.jar
with timestamp 1682357565906
23/04/24 17:32:47 INFO Utils: Using initial executors = 3, max of
spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors
and spark.executor.instances
23/04/24 17:32:47 INFO ExecutorContainerAllocator: Set total expected execs
to {0=3}
23/04/24 17:32:47 INFO Utils: Successfully started service
'org.apache.spark.network.netty.NettyBlockTransferService' on port 35927.
23/04/24 17:32:47 INFO NettyBlockTransferService: Server created on
[2600:1f18:5856:4301:8471:a289:676c:1ff0]:35927
23/04/24 17:32:47 INFO BlockManager: Using
org.apache.spark.storage.RandomBlockReplicationPolicy for block replication
policy
23/04/24 17:32:47 INFO BlockManagerMaster: Registering BlockManager
BlockManagerId(driver, [2600:1f18:5856:4301:8471:a289:676c:1ff0], 35927, None)
23/04/24 17:32:47 INFO BlockManagerMasterEndpoint: Registering block manager
[2600:1f18:5856:4301:8471:a289:676c:1ff0]:35927 with 7.3 GiB RAM,
BlockManagerId(driver, [2600:1f18:5856:4301:8471:a289:676c:1ff0], 35927, None)
23/04/24 17:32:47 INFO BlockManagerMaster: Registered BlockManager
BlockManagerId(driver, [2600:1f18:5856:4301:8471:a289:676c:1ff0], 35927, None)
23/04/24 17:32:47 INFO BlockManager: Initialized BlockManager:
BlockManagerId(driver, [2600:1f18:5856:4301:8471:a289:676c:1ff0], 35927, None)
23/04/24 17:32:47 INFO ExecutorContainerAllocator: Going to request 3
executors for ResourceProfile Id: 0, target: 3 already provisioned: 0.
23/04/24 17:32:47 INFO DefaultEmrServerlessRMClient: Creating containers
with container role SPARK_EXECUTOR and keys: Set(1, 2, 3)
23/04/24 17:32:47 INFO SingleEventLogFileWriter: Logging events to
file:/var/log/spark/apps/00f9k5j6uatf6b09.inprogress
23/04/24 17:32:47 INFO Utils: Using initial executors = 3, max of
spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors
and spark.executor.instances
23/04/24 17:32:47 INFO ExecutorAllocationManager: Dynamic allocation is
enabled without a shuffle service.
23/04/24 17:32:47 INFO ExecutorContainerAllocator: Set total expected execs
to {0=3}
23/04/24 17:32:47 INFO DefaultEmrServerlessRMClient: Containers created with
container role SPARK_EXECUTOR. key to container id map: Map(2 ->
b4c3da29-8d54-5c47-92b5-cb12498c32a8, 1 ->
bcc3da29-8d24-1e3f-c6b7-b941a5b6c570, 3 -> fec3da29-8d30-0e57-f3b6-35b5fe897c79)
23/04/24 17:32:51 INFO
EmrServerlessClusterSchedulerBackend$EmrServerlessDriverEndpoint: Registered
executor NettyRpcEndpointRef(spark-client://Executor)
(2600:1f18:5856:4301:6434:e690:3a6b:a55e:42664) with ID 1, ResourceProfileId 0
23/04/24 17:32:51 INFO
EmrServerlessClusterSchedulerBackend$EmrServerlessDriverEndpoint: Registered
executor NettyRpcEndpointRef(spark-client://Executor)
(2600:1f18:5856:4301:cddc:9113:28e1:eb26:38970) with ID 3, ResourceProfileId 0
23/04/24 17:32:51 INFO ExecutorMonitor: New executor 1 has registered (new
total is 1)
23/04/24 17:32:51 INFO ExecutorMonitor: New executor 3 has registered (new
total is 2)
23/04/24 17:32:51 INFO BlockManagerMasterEndpoint: Registering block manager
[2600:1f18:5856:4301:cddc:9113:28e1:eb26]:43825 with 2.7 GiB RAM,
BlockManagerId(3, [2600:1f18:5856:4301:cddc:9113:28e1:eb26], 43825, None)
23/04/24 17:32:51 INFO BlockManagerMasterEndpoint: Registering block manager
[2600:1f18:5856:4301:6434:e690:3a6b:a55e]:38015 with 2.7 GiB RAM,
BlockManagerId(1, [2600:1f18:5856:4301:6434:e690:3a6b:a55e], 38015, None)
23/04/24 17:32:51 INFO
EmrServerlessClusterSchedulerBackend$EmrServerlessDriverEndpoint: Registered
executor NettyRpcEndpointRef(spark-client://Executor)
(2600:1f18:5856:4301:54a3:8e48:1700:41c7:43444) with ID 2, ResourceProfileId 0
23/04/24 17:32:51 INFO ExecutorMonitor: New executor 2 has registered (new
total is 3)
23/04/24 17:32:51 INFO EmrServerlessClusterSchedulerBackend:
SchedulerBackend is ready for scheduling beginning after reached
minRegisteredResourcesRatio: 0.8
23/04/24 17:32:51 INFO BlockManagerMasterEndpoint: Registering block manager
[2600:1f18:5856:4301:54a3:8e48:1700:41c7]:34311 with 2.7 GiB RAM,
BlockManagerId(2, [2600:1f18:5856:4301:54a3:8e48:1700:41c7], 34311, None)
23/04/24 17:32:51 INFO S3NativeFileSystem: Opening
's3://delta-streamer-demo-hudi/hudi/.hoodie/hoodie.properties' for reading
23/04/24 17:32:51 WARN HoodieWriteConfig: Embedded timeline server is
disabled, fallback to use direct marker type for spark
23/04/24 17:32:52 WARN HoodieCompactor: No instant time is provided for
scheduling compaction.
23/04/24 17:32:52 INFO S3NativeFileSystem: Opening
's3://delta-streamer-demo-hudi/hudi/.hoodie/hoodie.properties' for reading
23/04/24 17:32:52 WARN HoodieCompactor: Couldn't do schedule
23/04/24 17:32:52 INFO SparkUI: Stopped Spark web UI at
http://[2600:1f18:5856:4301:8471:a289:676c:1ff0]:8090
23/04/24 17:32:52 INFO EmrServerlessClusterSchedulerBackend: Shutting down
all executors
23/04/24 17:32:52 INFO
EmrServerlessClusterSchedulerBackend$EmrServerlessDriverEndpoint: Asking each
executor to shut down
23/04/24 17:32:52 INFO MapOutputTrackerMasterEndpoint:
MapOutputTrackerMasterEndpoint stopped!
23/04/24 17:32:52 INFO MemoryStore: MemoryStore cleared
23/04/24 17:32:52 INFO BlockManager: BlockManager stopped
23/04/24 17:32:52 INFO BlockManagerMaster: BlockManagerMaster stopped
23/04/24 17:32:52 INFO
OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:
OutputCommitCoordinator stopped!
23/04/24 17:32:52 INFO SparkContext: Successfully stopped SparkContext
23/04/24 17:32:52 INFO ShutdownHookManager: Shutdown hook called
23/04/24 17:32:52 INFO ShutdownHookManager: Deleting directory
/tmp/spark-7d6b3915-7b6d-4bfd-b534-a898b6dd6653
23/04/24 17:32:52 INFO ShutdownHookManager: Deleting directory
/tmp/spark-03ad476f-549d-4bc5-b1f4-16b1a343a93c
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}